diff --git a/C04-Recurrences/4.2.md b/C04-Recurrences/4.2.md
index a753da45..a9c442da 100644
--- a/C04-Recurrences/4.2.md
+++ b/C04-Recurrences/4.2.md
@@ -1,88 +1,89 @@
-### Exercises 4.2-1
-***
-Use a recursion tree to determine a good asymptotic upper bound on the recurrence
+### Exercises 4.2-1
+***
+Use a recursion tree to determine a good asymptotic upper bound on the recurrence
 = 3T\(\\lceil n/2 \\rceil\) + n). Use the substitution method to verify your answer.
-### `Answer`
-
-
-树的高度是lgn,有3^lgn个叶子节点.
-
- = n\\sum_{i = 0}^{lg\(n\)-1}\(\\frac{3}{2}\)^i + \\Theta\(3^{\\lg{n}}\) \\\\ ~
-\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\) + \\Theta\(3^{\\lg{n}}\) \\\\ ~
-\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\) + \\Theta\(n^{\\lg{3}}\) \\\\ ~
-\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\)
-)
-
-我们猜想  \\le cn^{\\lg{3}}+2n )
-
- \\le 3c\(n/2\)^{\\lg{3}} + 2n \\\\ ~
-\\hspace{15 mm} \\le cn^{\\lg{3}}+2n \\\\ ~
-\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\)
-)
-
-
-### Exercises 4.2-2
-***
-Argue that the solution to the recurrence
- = T\(n/3\) + T\(2n/3\) + cn )
-, where c is a constant, is Ω(nlgn) by appealing to the recurrsion tree.
-
-### `Answer`
-最短的叶子高度是lg3n,每一层都要cn.也就是说,只考虑最短叶子的那一层(忽略其他层)已经有cnlg3n.
-
-
-### Exercises 4.2-3
-***
-Draw the recursion tree for
- = 4T\(\\lfloor n/2 \\rfloor\) + cn)
-,where c is a constant, and provide a tight asymptotic bound on its solution. Verify your bound by the substitution method.
-### `Answer`
-
-
-很明显是n^2的级别
-
-我们假设  \\le n^2+2cn)
-
- \\le 4c\(n/2\)^2 + 2cn/2+cn \\le cn^2+2cn)
-
-我们假设  \\ge n^2+2cn)
-
- \\ge 4c\(n/2\)^2 + 2cn/2+cn \\ge cn^2+2cn)
-
-### Exercises 4.2-4
-***
-Use a recursion tree to give an asymptotically tight solution to the recurrence T(n) = T(n - a) + T(a) + cn, where a ≥ 1 and c > 0 are constants.
-
-### `Answer`
-
-file:///Users/ganzhenchao/Workspaces/CLRS/C04-Recurrences/repo/s2/4.png
-  = \\sum_{i=0}^{n/a}c\(n-ia\) + \(n/a\)ca
-= \\Theta\(n^2\))
-
-我们假设  \\le cn^2)
-
- \\le c\(n-a\)^2 + ca + cn \\\\ ~
-\\hspace{15 mm} \\le cn^2-2acn+ca+cn \\\\ ~
-\\hspace{15 mm} \\le cn^2-c\(2an-a-n\) \\\\ ~
-\\hspace{15 mm}\\le cn^2 - cn ~~~~ if ~~ a > 1/2,n > 2a \\\\ ~
-\\hspace{15 mm}\\le cn^2 \\\\ ~
-\\hspace{15 mm} = \\Theta\(n^2\)
-)
-
-另外一个方向的证明和这个基本一样.
-
-### Exercises 4.2-5
-***
-Use a recursion tree to give an asymptotically tight solution to the recurrence T(n) = T(αn) +
T((1 - α)n) + cn, where α is a constant in the range 0 <α < 1 and c > 0 is also a constant.
-
-### `Answer`
-
-
-可以假设α < 1/2,因此树的高度有
-
- = \\sum_{i = 0}^{\\log_{1/ \\alpha}{n}}cn + \\Theta\(n\) = cn\\log_{1/ \\alpha}{n} + \\Theta\(n\) = \\Theta\(n\\lg{n}\) )
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+
+
+树的高度是lgn,有3^lgn个叶子节点.
+
+ = n\\sum_{i = 0}^{lg\(n\)-1}\(\\frac{3}{2}\)^i + \\Theta\(3^{\\lg{n}}\) \\\\ ~
+\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\) + \\Theta\(3^{\\lg{n}}\) \\\\ ~
+\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\) + \\Theta\(n^{\\lg{3}}\) \\\\ ~
+\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\)
+)
+
+我们猜想  \\le cn^{\\lg{3}}+2n )
+
+ \\le 3c\(n/2\)^{\\lg{3}} + 2n \\\\ ~
+\\hspace{15 mm} \\le cn^{\\lg{3}}+2n \\\\ ~
+\\hspace{15 mm} = \\Theta\(n^{\\lg{3}}\)
+)
+
+
+### Exercises 4.2-2
+***
+Argue that the solution to the recurrence
+ = T\(n/3\) + T\(2n/3\) + cn )
+, where c is a constant, is Ω(nlgn) by appealing to the recurrsion tree.
+
+### `Answer`
+最短的叶子高度是lg3n,每一层都要cn.也就是说,只考虑最短叶子的那一层(忽略其他层)已经有cnlg3n.
+
+
+### Exercises 4.2-3
+***
+Draw the recursion tree for
+ = 4T\(\\lfloor n/2 \\rfloor\) + cn)
+,where c is a constant, and provide a tight asymptotic bound on its solution. Verify your bound by the substitution method.
+### `Answer`
+
+
+很明显是n^2的级别
+
+我们假设  \\le n^2+2cn)
+
+ \\le 4c\(n/2\)^2 + 2cn/2+cn \\le cn^2+2cn)
+
+我们假设  \\ge n^2+2cn)
+
+ \\ge 4c\(n/2\)^2 + 2cn/2+cn \\ge cn^2+2cn)
+
+### Exercises 4.2-4
+***
+Use a recursion tree to give an asymptotically tight solution to the recurrence T(n) = T(n - a) + T(a) + cn, where a ≥ 1 and c > 0 are constants.
+
+### `Answer`
+
+file:///Users/ganzhenchao/Workspaces/CLRS/C04-Recurrences/repo/s2/4.png
+  = \\sum_{i=0}^{n/a}c\(n-ia\) + \(n/a\)ca
+= \\Theta\(n^2\))
+
+我们假设  \\le cn^2)
+
+ \\le c\(n-a\)^2 + ca + cn \\\\ ~
+\\hspace{15 mm} \\le cn^2-2acn+ca+cn \\\\ ~
+\\hspace{15 mm} \\le cn^2-c\(2an-a-n\) \\\\ ~
+\\hspace{15 mm}\\le cn^2 - cn ~~~~ if ~~ a > 1/2,n > 2a \\\\ ~
+\\hspace{15 mm}\\le cn^2 \\\\ ~
+\\hspace{15 mm} = \\Theta\(n^2\)
+)
+
+另外一个方向的证明和这个基本一样.
+
+### Exercises 4.2-5
+***
+Use a recursion tree to give an asymptotically tight solution to the recurrence T(n) = T(αn) +
+T((1 - α)n) + cn, where α is a constant in the range 0 <α < 1 and c > 0 is also a constant.
+
+### `Answer`
+
+
+可以假设α < 1/2,因此树的高度有
+
+ = \\sum_{i = 0}^{\\log_{1/ \\alpha}{n}}cn + \\Theta\(n\) = cn\\log_{1/ \\alpha}{n} + \\Theta\(n\) = \\Theta\(n\\lg{n}\) )
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C04-Recurrences/4.3.md b/C04-Recurrences/4.3.md
index c574affd..ddf0fd75 100644
--- a/C04-Recurrences/4.3.md
+++ b/C04-Recurrences/4.3.md
@@ -1,79 +1,80 @@
-### Exercises 4.3-1
-***
-Use the master method to give tight asymptotic bounds for the following recurrences.
-
-a.  = 4T\(n/2\)+n )
-
-b.  = 4T\(n/2\)+n^2 )
-
+### Exercises 4.3-1
+***
+Use the master method to give tight asymptotic bounds for the following recurrences.
+
+a.  = 4T\(n/2\)+n )
+
+b.  = 4T\(n/2\)+n^2 )
+
c.  = 4T\(n/2\)+n^3 )
-### `Answer`
-
-
-a.  )
-
-b.  )
-
-c.  )
-
-
-### Exercises 4.3-2
-***
-The recurrence T(n) = 7T (n/2)+n2 describes the running time of an algorithm A. A competing algorithm A′ has a running time of T′(n) = aT′(n/4) + n2. What is the largest integer value for a such that A′ is asymptotically faster than A?
-
-### `Answer`
-根据主定理,算法A的运行时间为 = \\Theta\(\\lg{7}\)\ \\approx n^{2.8} )
-
-A'的运行时间在a > 16时超过n^2,此时
-
- = \\Theta\(n^{\\log_{4}{a}}\) < \\lg{7} = \\log_{4}{49})
-
-所以最大值为48
-
-
-
-### Exercises 4.3-3
-***
-Use the master method to show that the solution to the binary-search recurrence T(n) = T (n/2)
+ Θ(1) is T(n) = Θ(lg n). (See Exercise 2.3-5 for a description of binary search.)
-### `Answer`
-
-
-so the solution is Θ(lgn).
-
-
-### Exercises 4.3-4
-***
-Can the master method be applied to the recurrence
- = 4T\(n/2\) + n^2 \\lg{n} )
+### `Answer`
+
+
+a.  )
+
+b.  )
+
+c.  )
+
+
+### Exercises 4.3-2
+***
+The recurrence T(n) = 7T (n/2)+n2 describes the running time of an algorithm A. A competing algorithm A′ has a running time of T′(n) = aT′(n/4) + n2. What is the largest integer value for a such that A′ is asymptotically faster than A?
+
+### `Answer`
+根据主定理,算法A的运行时间为 = \\Theta\(\\lg{7}\)\ \\approx n^{2.8} )
+
+A'的运行时间在a > 16时超过n^2,此时
+
+ = \\Theta\(n^{\\log_{4}{a}}\) < \\lg{7} = \\log_{4}{49})
+
+所以最大值为48
+
+
+
+### Exercises 4.3-3
+***
+Use the master method to show that the solution to the binary-search recurrence T(n) = T (n/2)
++ Θ(1) is T(n) = Θ(lg n). (See Exercise 2.3-5 for a description of binary search.)
+### `Answer`
+
+
+so the solution is Θ(lgn).
+
+
+### Exercises 4.3-4
+***
+Can the master method be applied to the recurrence
+ = 4T\(n/2\) + n^2 \\lg{n} )
Why or why not? Give an asymptotic upper bound for this recurrence.
-
-### `Answer`
-
-
-The problem is that it is not polynomially larger. The ratio 
- / n^{\\log_{b}{a}} = \\lg{n})
-is asymptotically less than
- for any positive constant
-
-
-### Exercises 4.3-5
-***
-Consider the regularity condition af (n/b) ≤ cf(n) for some constant c < 1, which is part of case 3 of the master theorem. Give an example of constants a ≥ 1 and b > 1 and a function f (n) that satisfies all the conditions in case 3 of the master theorem except the regularity condition.
-
-### `Answer`
-let
-
- a = 1
- b = 2
- f(n) = 2 - cos(n)
-
-我们需要证明
-
-}\) < cn \\\\ ~ \\Rightarrow c > \\frac{2- \\cos\(n/2\)}{2} \\\\ ~
-\\Rightarrow c > \\frac{3}{2}
-)
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+
+
+The problem is that it is not polynomially larger. The ratio 
+ / n^{\\log_{b}{a}} = \\lg{n})
+is asymptotically less than
+ for any positive constant
+
+
+### Exercises 4.3-5
+***
+Consider the regularity condition af (n/b) ≤ cf(n) for some constant c < 1, which is part of case 3 of the master theorem. Give an example of constants a ≥ 1 and b > 1 and a function f (n) that satisfies all the conditions in case 3 of the master theorem except the regularity condition.
+
+### `Answer`
+let
+
+ a = 1
+ b = 2
+ f(n) = 2 - cos(n)
+
+我们需要证明
+
+}\) < cn \\\\ ~ \\Rightarrow c > \\frac{2- \\cos\(n/2\)}{2} \\\\ ~
+\\Rightarrow c > \\frac{3}{2}
+)
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C04-Recurrences/4.4.md b/C04-Recurrences/4.4.md
index 7fabc0ad..2ed9d3b7 100644
--- a/C04-Recurrences/4.4.md
+++ b/C04-Recurrences/4.4.md
@@ -1,47 +1,47 @@
-### Exercises 4.4-1
-***
+### Exercises 4.4-1
+***
Give a simple and exact expression for nj in equation (4.12) for the case in which b is a positive integer instead of an arbitrary real number.
-### `Answer`
-
-
-
-### Exercises 4.4-2
-***
-Show that if  = \\Theta\(n^{\\log_{b}{a}}\) \\lg^k{n} ) , where k ≥ 0, then the master recurrence has solution
-Show that if  = \\Theta\(n^{\\log_{b}{a}}\) \\lg^{k+1}{n} ).
-
-### `Answer`
- = \\sum_{j = 0}^{\\log_{b}{n-1}} a^jf\(n/b^j\) \\\\ ~ f\(n/b^j\) = \\Theta\\Big\(\(n/b^j\)^{\\log_b{a}}\\lg^k\(n/b^j\)\\Big\) \\\\
-g\(n\) = \\Theta\\Big\(\\sum_{j=0}^{\\log_b{n}-1}a^j\\big\(\\frac{n}{b^j}\\big\)^{\\log_b{a}}\\lg^k\\big\(\\frac{n}{b^j}\\big\)\\Big\) = \\Theta\(A\) \\\\
-A = \\sum_{j=0}^{\\log_b{n}-1}a^j\\big\(\\frac{n}{b^j}\\big\)^{\\log_b{a}}\\lg^k\\frac{n}{b^j}
- = n^{\\log_b{a}}\\sum_{j=0}^{\\log_b{n}-1}\\Big\(\\frac{a}{b^{\\log_b{a}}}\\Big\)^j\\lg^k\\frac{n}{b^j}
- = n^{\\log_b{a}}\\sum_{j=0}^{\\log_b{n}-1}\\lg^k\\frac{n}{b^j}
- = n^{\\log_b{a}}B \\\\
-\\lg^k\\frac{n}{d} = \(\\lg{n} - \\lg{d}\)^k = \\lg^k{n} + o\(\\lg^k{n}\) \\\\
-B = \\sum_{j=0}^{\\log_b{n}-1}\\lg^k\\frac{n}{b^j}
- = \\sum_{j=0}^{\\log_b{n}-1}\\Big\(\\lg^k{n} - o\(\\lg^k{n}\)\\Big\)
- = \\log_b{n}\\lg^k{n} + \\log_b{n} \\cdot o\(\\lg^k{n}\)
- = \\Theta\(\\log_b{n}\\lg^k{n}\)
- = \\Theta\(\\lg^{k+1}{n}\) \\\\
-g\(n\) = \\Theta\(A\) = \\Theta\(n^{\\log_b{a}}B\) = \\Theta\(n^{\\log_b{a}}\\lg^{k+1}{n}\)
-)
-
-
-### Exercises 4.3-3
-***
+### `Answer`
+
+
+
+### Exercises 4.4-2
+***
+Show that if  = \\Theta\(n^{\\log_{b}{a}}\) \\lg^k{n} ) , where k ≥ 0, then the master recurrence has solution
+Show that if  = \\Theta\(n^{\\log_{b}{a}}\) \\lg^{k+1}{n} ).
+
+### `Answer`
+ = \\sum_{j = 0}^{\\log_{b}{n-1}} a^jf\(n/b^j\) \\\\ ~ f\(n/b^j\) = \\Theta\\Big\(\(n/b^j\)^{\\log_b{a}}\\lg^k\(n/b^j\)\\Big\) \\\\
+g\(n\) = \\Theta\\Big\(\\sum_{j=0}^{\\log_b{n}-1}a^j\\big\(\\frac{n}{b^j}\\big\)^{\\log_b{a}}\\lg^k\\big\(\\frac{n}{b^j}\\big\)\\Big\) = \\Theta\(A\) \\\\
+A = \\sum_{j=0}^{\\log_b{n}-1}a^j\\big\(\\frac{n}{b^j}\\big\)^{\\log_b{a}}\\lg^k\\frac{n}{b^j}
+ = n^{\\log_b{a}}\\sum_{j=0}^{\\log_b{n}-1}\\Big\(\\frac{a}{b^{\\log_b{a}}}\\Big\)^j\\lg^k\\frac{n}{b^j}
+ = n^{\\log_b{a}}\\sum_{j=0}^{\\log_b{n}-1}\\lg^k\\frac{n}{b^j}
+ = n^{\\log_b{a}}B \\\\
+\\lg^k\\frac{n}{d} = \(\\lg{n} - \\lg{d}\)^k = \\lg^k{n} + o\(\\lg^k{n}\) \\\\
+B = \\sum_{j=0}^{\\log_b{n}-1}\\lg^k\\frac{n}{b^j}
+ = \\sum_{j=0}^{\\log_b{n}-1}\\Big\(\\lg^k{n} - o\(\\lg^k{n}\)\\Big\)
+ = \\log_b{n}\\lg^k{n} + \\log_b{n} \\cdot o\(\\lg^k{n}\)
+ = \\Theta\(\\log_b{n}\\lg^k{n}\)
+ = \\Theta\(\\lg^{k+1}{n}\) \\\\
+g\(n\) = \\Theta\(A\) = \\Theta\(n^{\\log_b{a}}B\) = \\Theta\(n^{\\log_b{a}}\\lg^{k+1}{n}\)
+)
+
+
+### Exercises 4.3-3
+***
Show that case 3 of the master theorem is overstated, in the sense that the regularity condition af(n/b) ≤ cf(n) for some constant c < 1 implies that there exists a constant  = \\Omega\(n^{\\log_b{a+\\epsilon}}\)).
-### `Answer`
-根据case3,我们有 \\le cf\(n\) ~~~~ a \\ge 1,b \\ge 1 c < 1 )
-
-变形一下
-
- \\ge kf\(n\) ~~~where ~ k = a/c > a \\\\ \\Rightarrow f\(b^i\) \\ge k^i f\(1\) \\\\
-if~~ n = b^i, i = \\log_b{n}, then f\(n\) \\ge k^{\\log_b{n}}f\(1\) \\\\
-k^{\\log_b{n}} = n^{\\log_b{k}} ~ and ~ \\log_b{k} \\ge \\log_b{a} ~so~ \\log_b{k} = \\log_b{a} + \\epsilon
-)
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+根据case3,我们有 \\le cf\(n\) ~~~~ a \\ge 1,b \\ge 1 c < 1 )
+
+变形一下
+
+ \\ge kf\(n\) ~~~where ~ k = a/c > a \\\\ \\Rightarrow f\(b^i\) \\ge k^i f\(1\) \\\\
+if~~ n = b^i, i = \\log_b{n}, then f\(n\) \\ge k^{\\log_b{n}}f\(1\) \\\\
+k^{\\log_b{n}} = n^{\\log_b{k}} ~ and ~ \\log_b{k} \\ge \\log_b{a} ~so~ \\log_b{k} = \\log_b{a} + \\epsilon
+)
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C04-Recurrences/problem.md b/C04-Recurrences/problem.md
index 2f693345..c49eb793 100644
--- a/C04-Recurrences/problem.md
+++ b/C04-Recurrences/problem.md
@@ -1,231 +1,317 @@
-### Problems 1 : Recurrence examples
-***
-Throughout this book, we assume that parameter passing during procedure calls takes constant time, even if an N-element array is being passed. This assumption is valid in most systems because a pointer to the array is passed, not the array itself. This problem examines the implications of three parameter-passing strategies:
-
-1. An array is passed by pointer. Time = Θ(1).
-
2. An array is passed by copying. Time = Θ(N), where N is the size of the array.
-
3. An array is passed by copying only the subrange that might be accessed by the called
procedure. Time = Θ(q - p + 1) if the subarray A[p...q] is passed.
-
**a.** Consider the recursive binary search algorithm for finding a number in a sorted array (see Exercise 2.3-5). Give recurrences for the worst-case running times of binary search when arrays are passed using each of the three methods above, and give good upper bounds on the solutions of the recurrences. Let N be the size of the original problem and n be the size of a subproblem.
**b.** Redo part (a) for the MERGE-SORT algorithm from Section 2.3.1.
-
-### `Answer`
-1. Θ(n^4)
-
-2. Θ(n)
-
-3. Θ(n^2lgn)
-
-4. Θ(n^2)
-
-5.  )
-
-6. 
-
-7. Θ(n^3)
-
-
-
-### Problems 2 : Finding the missing integer
-***
-An array A[1...n] contains all the integers from 0 to n except one. It would be easy to determine the missing integer in O(n) time by using an auxiliary array B[0...n] to record which numbers appear in A. In this problem, however, we cannot access an entire integer in A with a single operation. The elements of A are represented in binary, and the only operation we can use to access them is "fetch the jth bit of A[i]," which takes constant time.
-
Show that if we use only this operation, we can still determine the missing integer in O(n) time.
-
-### `Answer`
-* 00000
-* 00001
-* 00010
-* 00011
-* 00101
-* 00110
-* 00111
-* 01000
-
-[code](./exercise_code/findMissing.py)
-
-我们用上面的8个数字当作例子,[0,8]缺4.
-
- 1.第一次迭代发现最末位1出现4次0出现3次,所以missnum的最后一位是4,排除掉末位为1的数字
- 2.然后一次次迭代
-
-### Problems 3 : Parameter-passing costs
Throughout this book, we assume that parameter passing during procedure calls takes constant time, even if an N-element array is being passed. This assumption is valid in most systems because a pointer to the array is passed, not the array itself. This problem examines the implications of three parameter-passing strategies:
-
1. An array is passed by pointer. Time = Θ(1).
-
2. An array is passed by copying. Time = Θ(N), where N is the size of the array.
-
3. An array is passed by copying only the subrange that might be accessed by the calledprocedure. Time = Θ(q - p + 1) if the subarray A[p...q] is passed.
-
**a.** Consider the recursive binary search algorithm for finding a number in a sorted array (see Exercise 2.3-5). Give recurrences for the worst-case running times of binary search when arrays are passed using each of the three methods above, and give good upper bounds on the solutions of the recurrences. Let N be the size of the original problem and n be the size of a subproblem.
-
**b.** Redo part (a) for the MERGE-SORT algorithm from Section 2.3.1.
-
### `Answer`
-
**a.**
-
1. T(n) = T(n/2) + 2, O(lgN)
-
2. T(n) = T(n/2) + N, O(NlgN)
-
3. T(n) = T(n/2) + n, O(N)
-
**b.**
-
-1. T(n) = 2T(n/2) + n + 2, O(NlgN)
-
2. T(n) = 2T(n/2) + n + 2N, O(2^{lgN})
-
3. T(N) = 2T(n/2) + n + 2n, O(Nlg^**2**N)
-
### Problems 4 : More recurrence examples
-
**a.**
 = 3T\(n/2\) + \\lg{n} \\\\
by~applying~master~method~\\Theta\(n^{\\log_3{4}}\))
-***
**b.**
 = 5T\(n/5\) + n/\\lg{n} \\\\
T\(n\) = 5T\(n/5\) + \\frac{n}{\\lg{n}} = 25T\(n/25\) + 5\\frac{n/5}{\\lg\(n/5\)} + \\frac{n}{\\lg{n}} = 25T\(n/25\) + \\frac{n}{\\lg{n}-\\lg{5}} + \\frac{n}{\\lg{n}} = nT\(1\)+\\sum_{i = 0}^{\\lg{n}-1}\\frac{n}{\\lg{n}-i\\lg{5}} = nT\(1\)+n\\sum_{i = 1}^{\\lg{n}}\\frac{1}{\\lg{n}} = \\Theta\(n\\lg{\\lg{n}}\))
-***
**c.**
 = 4T\(n/2\)+n^2\\sqrt{n} \\\\
-by ~applying~master~method~ \\Theta\(n^2\\sqrt{n}\) )
-***
-**d.**
 = 3T\(n/3+5\) + n/2 \\\\
by ~applying~master~method~ \\Theta\(n\\lg{n}\)
)
-***
**e.**
The same as b
-***
**f.**
 = T\(n/2\) + T\(n/4\) + T\(n/8\) + n\\\\
Let's ~ guess ~ \\Theta\(n\) \\\\
-T\(n\) = cn/2 + cn/4 + cn/8 \\le cn = O\(n\) \\\\
-T\(n\) = cn/2 + cn/4 + cn/8 \\ge cn = \\Omega\(n\)
)
-***
**g.**
 = T\(n-1\) + 1/n \\\\
-T\(n\) = \\sum_{i = 1}^{n}\\frac{1}{i} = \\Theta\(lg{n}\)
-)
-***
-**h.**
 = T\(n-1\) + \\lg{n} \\\\
-T\(n\) = \\sum_{i=1}^{n}\\lg{i} = \\lg{n!} = \\Theta\(n\\lg{n}\) ~ remember ~we ~prove ~it ~in ~section~1
)
-***
**i.**
 = T\(n-2\) + 2\\lg{n} ~ The ~same
-)
-***
-**j.**
 = \\sqrt{n}T\(\\sqrt{n}\)+n \\\\
-Let's ~ guess ~ \\Theta\(cn\\lg{\\lg{n}}\) \\\\
-T\(n\) \\le \\sqrt{n}c\\sqrt{n}\\lg{\\lg{\\sqrt{n}}}+n \\\\
-= cn\\lg{\\lg{\\sqrt{n}}}+n \\\\
-= cn\\lg{\\frac{\\lg{n}}{2}}+n \\\\
-= cn\\lg{\\lg{n}} - cn\\lg{2}+n \\\\
-= cn\\lg{\\lg{n}} + \(1-c\)n \\\\
-\\le cn\\lg{\\lg{n}} ~~~~~~~~~ if ~ c > 1 \\\\
-= \\Theta\(cn\\lg{\\lg{n}}\)
)
-
-
-### Problems 5 : Fibonacci numbers
-***
-This problem develops properties of the Fibonacci numbers, which are defined by recurrence (3.21). We shall use the technique of generating functions to solve the Fibonacci recurrence. Define the generating function (or formal power series) F as
-
- = \\sum_{i=0}^{\\infty}F\_iz^i \\\\
-= 0 + z + z^2 + 2z^3 + 3z^4 + 5z^5 + 8z^6 + 13z^7 + 21z^8 + \\ldots \\\\
-where~ F_i ~is ~the~ ith ~Fibonacci~ number.)
-
-a. Show that  = z + z\mathcal{F}\(z\) + z^2\mathcal{F}\(z\))
-
-b. Show that  = \\frac{z}{1-z-z^2} = \\frac{z}{\(1-\\phi{z}\)\(1-\\widehat\\phi{z}\)} = \\frac{1}{\\sqrt{5}}\(\\frac{1}{1-\\phi{z}}-\\frac{1}{1-\\widehat\\phi{z}}\)
-)
-
-c. Show that Show that  = \\sum_{i=0}^{\\infty}\\frac{1}{\\sqrt{5}}\(\\phi^i - \\widehat\\phi^i\)z^i )
-
-d. Prove that  = \\phi^i/\\sqrt{5}) for i > 0 , rounded to the nearest integer.
-
-e. Prove that  for i ≥ 0.
-
-### `Answer`
-**a.**
-
- + z^2\mathcal{F}\(z\) \\\\
-= z + z\\sum_{i=0}^{\\infty}F\_iz^i + z^2\\sum_{i=0}^{\\infty}F\_iz^i \\\\
-= z + z\\sum_{i=1}^{\\infty}F\_{i-1}z^i + z^2\\sum_{i=2}^{\\infty}F\_{i-2}z^i \\\\
-= z + F_1z + \\sum_{i=2}^{\\infty}\(F_{i-1}+F_{i-2}\)z^i \\\\
-= z + F_1z + \\sum_{i=2}^{\\infty}F_iz^i \\\\
-= \\mathcal{F}\(z\))
-
-**b.**
-这个结论的证明还是很straight-forward的,就不写公式啦.
-
-**c.**
-
- = \\frac{1}{\\sqrt5}\\Big\(\\frac{1}{1 - \\phi z} - \\frac{1}{1 - \\hat\\phi z}\\Big\) = \\frac{1}{\\sqrt5}\\Big\(\\sum_{i=0}^{\\infty}\\phi^i z^i - \\sum_{i=0}^{\\infty}\\hat{\\phi}^i z^i\\Big\)= \\sum_{i=0}^{\\infty}\\frac{1}{\\sqrt5}\(\\phi^i - \\hat{\\phi}^i\) z^i
-)
-
-**d.**
-
- = \\sum_{i=0}^{\\infty}\\alpha_iz^i \\quad\\text{ where } \\alpha_i = \\frac{\\phi^i - \\hat{\\phi}^i}{\\sqrt5} \\\\
-\\quad\\text{ so we have } \\alpha_i = F_i \\\\
-F_i = \\frac{\\phi^i - \\hat{\\phi}^i}{\\sqrt5} = \\frac{\\phi^i}{\\sqrt5} - \\frac{\\hat{\\phi}^i}{\\sqrt5} \\\\
-\\quad\\text{because } |\\hat\\phi| < 1 \\quad\\text{, so } \\frac{|\\hat\\phi^i|}{\\sqrt{5}} < 0.5
-)
-
-**e.**
-[we had prove it previously](https://github.com/gzc/CLRS/blob/master/C03-Growth-of-Functions/3.2.md#exercises-32-7)
-
-### Problems 6 : VLSI chip testing
-***
-Professor Diogenes has n supposedly identical VLSI[1] chips that in principle are capable of testing each other. The professor's test jig accommodates two chips at a time. When the jig is loaded, each chip tests the other and reports whether it is good or bad. A good chip always reports accurately whether the other chip is good or bad, but the answer of a bad chip cannot be trusted. Thus, the four possible outcomes of a test are as follows:
-
Chip A says | Chip B says | Conclusion
:----:|:----:|:----:
B is good | A is good | both are good, or both are bad
B is good | A is bad | at least one is bad
B is bad | A is good | at least one is bad
+### Problems 1 : Recurrence examples
+***
+Throughout this book, we assume that parameter passing during procedure calls takes constant time, even if an N-element array is being passed. This assumption is valid in most systems because a pointer to the array is passed, not the array itself. This problem examines the implications of three parameter-passing strategies:
+
+1. An array is passed by pointer. Time = Θ(1).
+
+2. An array is passed by copying. Time = Θ(N), where N is the size of the array.
+
+3. An array is passed by copying only the subrange that might be accessed by the called
+procedure. Time = Θ(q - p + 1) if the subarray A[p...q] is passed.
+
+
+**a.** Consider the recursive binary search algorithm for finding a number in a sorted array (see Exercise 2.3-5). Give recurrences for the worst-case running times of binary search when arrays are passed using each of the three methods above, and give good upper bounds on the solutions of the recurrences. Let N be the size of the original problem and n be the size of a subproblem.
+
+**b.** Redo part (a) for the MERGE-SORT algorithm from Section 2.3.1.
+
+### `Answer`
+1. Θ(n^4)
+
+2. Θ(n)
+
+3. Θ(n^2lgn)
+
+4. Θ(n^2)
+
+5.  )
+
+6. 
+
+7. Θ(n^3)
+
+
+
+### Problems 2 : Finding the missing integer
+***
+An array A[1...n] contains all the integers from 0 to n except one. It would be easy to determine the missing integer in O(n) time by using an auxiliary array B[0...n] to record which numbers appear in A. In this problem, however, we cannot access an entire integer in A with a single operation. The elements of A are represented in binary, and the only operation we can use to access them is "fetch the jth bit of A[i]," which takes constant time.
+
+Show that if we use only this operation, we can still determine the missing integer in O(n) time.
+
+### `Answer`
+* 00000
+* 00001
+* 00010
+* 00011
+* 00101
+* 00110
+* 00111
+* 01000
+
+[code](./exercise_code/findMissing.py)
+
+我们用上面的8个数字当作例子,[0,8]缺4.
+
+ 1.第一次迭代发现最末位1出现4次0出现3次,所以missnum的最后一位是4,排除掉末位为1的数字
+ 2.然后一次次迭代
+
+### Problems 3 : Parameter-passing costs
+
+Throughout this book, we assume that parameter passing during procedure calls takes constant time, even if an N-element array is being passed. This assumption is valid in most systems because a pointer to the array is passed, not the array itself. This problem examines the implications of three parameter-passing strategies:
+
+
+1. An array is passed by pointer. Time = Θ(1).
+
+
+2. An array is passed by copying. Time = Θ(N), where N is the size of the array.
+
+
+3. An array is passed by copying only the subrange that might be accessed by the calledprocedure. Time = Θ(q - p + 1) if the subarray A[p...q] is passed.
+
+**a.** Consider the recursive binary search algorithm for finding a number in a sorted array (see Exercise 2.3-5). Give recurrences for the worst-case running times of binary search when arrays are passed using each of the three methods above, and give good upper bounds on the solutions of the recurrences. Let N be the size of the original problem and n be the size of a subproblem.
+
+**b.** Redo part (a) for the MERGE-SORT algorithm from Section 2.3.1.
+
+
+### `Answer`
+
+**a.**
+
+1. T(n) = T(n/2) + 2, O(lgN)
+
+2. T(n) = T(n/2) + N, O(NlgN)
+
+3. T(n) = T(n/2) + n, O(N)
+
+
+**b.**
+
+1. T(n) = 2T(n/2) + n + 2, O(NlgN)
+
+2. T(n) = 2T(n/2) + n + 2N, O(2^{lgN})
+
+3. T(N) = 2T(n/2) + n + 2n, O(Nlg^**2**N)
+
+
+### Problems 4 : More recurrence examples
+
+**a.**
+ = 3T\(n/2\) + \\lg{n} \\\\
+by~applying~master~method~\\Theta\(n^{\\log_3{4}}\))
+***
+**b.**
+ = 5T\(n/5\) + n/\\lg{n} \\\\
+T\(n\) = 5T\(n/5\) + \\frac{n}{\\lg{n}} = 25T\(n/25\) + 5\\frac{n/5}{\\lg\(n/5\)} + \\frac{n}{\\lg{n}} = 25T\(n/25\) + \\frac{n}{\\lg{n}-\\lg{5}} + \\frac{n}{\\lg{n}} = nT\(1\)+\\sum_{i = 0}^{\\lg{n}-1}\\frac{n}{\\lg{n}-i\\lg{5}} = nT\(1\)+n\\sum_{i = 1}^{\\lg{n}}\\frac{1}{\\lg{n}} = \\Theta\(n\\lg{\\lg{n}}\))
+***
+**c.**
+ = 4T\(n/2\)+n^2\\sqrt{n} \\\\
+by ~applying~master~method~ \\Theta\(n^2\\sqrt{n}\) )
+***
+**d.**
+ = 3T\(n/3+5\) + n/2 \\\\
+by ~applying~master~method~ \\Theta\(n\\lg{n}\)
+)
+***
+**e.**
+The same as b
+***
+**f.**
+ = T\(n/2\) + T\(n/4\) + T\(n/8\) + n\\\\
+Let's ~ guess ~ \\Theta\(n\) \\\\
+T\(n\) = cn/2 + cn/4 + cn/8 \\le cn = O\(n\) \\\\
+T\(n\) = cn/2 + cn/4 + cn/8 \\ge cn = \\Omega\(n\)
+)
+***
+**g.**
+ = T\(n-1\) + 1/n \\\\
+T\(n\) = \\sum_{i = 1}^{n}\\frac{1}{i} = \\Theta\(lg{n}\)
+)
+***
+**h.**
+ = T\(n-1\) + \\lg{n} \\\\
+T\(n\) = \\sum_{i=1}^{n}\\lg{i} = \\lg{n!} = \\Theta\(n\\lg{n}\) ~ remember ~we ~prove ~it ~in ~section~1
+)
+***
+**i.**
+ = T\(n-2\) + 2\\lg{n} ~ The ~same
+)
+***
+**j.**
+ = \\sqrt{n}T\(\\sqrt{n}\)+n \\\\
+Let's ~ guess ~ \\Theta\(cn\\lg{\\lg{n}}\) \\\\
+T\(n\) \\le \\sqrt{n}c\\sqrt{n}\\lg{\\lg{\\sqrt{n}}}+n \\\\
+= cn\\lg{\\lg{\\sqrt{n}}}+n \\\\
+= cn\\lg{\\frac{\\lg{n}}{2}}+n \\\\
+= cn\\lg{\\lg{n}} - cn\\lg{2}+n \\\\
+= cn\\lg{\\lg{n}} + \(1-c\)n \\\\
+\\le cn\\lg{\\lg{n}} ~~~~~~~~~ if ~ c > 1 \\\\
+= \\Theta\(cn\\lg{\\lg{n}}\)
+)
+
+
+### Problems 5 : Fibonacci numbers
+***
+This problem develops properties of the Fibonacci numbers, which are defined by recurrence (3.21). We shall use the technique of generating functions to solve the Fibonacci recurrence. Define the generating function (or formal power series) F as
+
+ = \\sum_{i=0}^{\\infty}F\_iz^i \\\\
+= 0 + z + z^2 + 2z^3 + 3z^4 + 5z^5 + 8z^6 + 13z^7 + 21z^8 + \\ldots \\\\
+where~ F_i ~is ~the~ ith ~Fibonacci~ number.)
+
+a. Show that  = z + z\mathcal{F}\(z\) + z^2\mathcal{F}\(z\))
+
+b. Show that  = \\frac{z}{1-z-z^2} = \\frac{z}{\(1-\\phi{z}\)\(1-\\widehat\\phi{z}\)} = \\frac{1}{\\sqrt{5}}\(\\frac{1}{1-\\phi{z}}-\\frac{1}{1-\\widehat\\phi{z}}\)
+)
+
+c. Show that Show that  = \\sum_{i=0}^{\\infty}\\frac{1}{\\sqrt{5}}\(\\phi^i - \\widehat\\phi^i\)z^i )
+
+d. Prove that  = \\phi^i/\\sqrt{5}) for i > 0 , rounded to the nearest integer.
+
+e. Prove that  for i ≥ 0.
+
+### `Answer`
+**a.**
+
+ + z^2\mathcal{F}\(z\) \\\\
+= z + z\\sum_{i=0}^{\\infty}F\_iz^i + z^2\\sum_{i=0}^{\\infty}F\_iz^i \\\\
+= z + z\\sum_{i=1}^{\\infty}F\_{i-1}z^i + z^2\\sum_{i=2}^{\\infty}F\_{i-2}z^i \\\\
+= z + F_1z + \\sum_{i=2}^{\\infty}\(F_{i-1}+F_{i-2}\)z^i \\\\
+= z + F_1z + \\sum_{i=2}^{\\infty}F_iz^i \\\\
+= \\mathcal{F}\(z\))
+
+**b.**
+这个结论的证明还是很straight-forward的,就不写公式啦.
+
+**c.**
+
+ = \\frac{1}{\\sqrt5}\\Big\(\\frac{1}{1 - \\phi z} - \\frac{1}{1 - \\hat\\phi z}\\Big\) = \\frac{1}{\\sqrt5}\\Big\(\\sum_{i=0}^{\\infty}\\phi^i z^i - \\sum_{i=0}^{\\infty}\\hat{\\phi}^i z^i\\Big\)= \\sum_{i=0}^{\\infty}\\frac{1}{\\sqrt5}\(\\phi^i - \\hat{\\phi}^i\) z^i
+)
+
+**d.**
+
+ = \\sum_{i=0}^{\\infty}\\alpha_iz^i \\quad\\text{ where } \\alpha_i = \\frac{\\phi^i - \\hat{\\phi}^i}{\\sqrt5} \\\\
+\\quad\\text{ so we have } \\alpha_i = F_i \\\\
+F_i = \\frac{\\phi^i - \\hat{\\phi}^i}{\\sqrt5} = \\frac{\\phi^i}{\\sqrt5} - \\frac{\\hat{\\phi}^i}{\\sqrt5} \\\\
+\\quad\\text{because } |\\hat\\phi| < 1 \\quad\\text{, so } \\frac{|\\hat\\phi^i|}{\\sqrt{5}} < 0.5
+)
+
+**e.**
+[we had prove it previously](https://github.com/gzc/CLRS/blob/master/C03-Growth-of-Functions/3.2.md#exercises-32-7)
+
+### Problems 6 : VLSI chip testing
+***
+Professor Diogenes has n supposedly identical VLSI[1] chips that in principle are capable of testing each other. The professor's test jig accommodates two chips at a time. When the jig is loaded, each chip tests the other and reports whether it is good or bad. A good chip always reports accurately whether the other chip is good or bad, but the answer of a bad chip cannot be trusted. Thus, the four possible outcomes of a test are as follows:
+
+Chip A says | Chip B says | Conclusion
+:----:|:----:|:----:
+B is good | A is good | both are good, or both are bad
+B is good | A is bad | at least one is bad
+B is bad | A is good | at least one is bad
B is bad | A is bad | at least one is bad
-
a. Show that if more than n/2 chips are bad, the professor cannot necessarily determine which chips are good using any strategy based on this kind of pairwise test. Assume that the bad chips can conspire to fool the professor.
-
b. Consider the problem of finding a single good chip from among n chips, assuming that
more than n/2 of the chips are good. Show that ⌊n/2⌋ pairwise tests are sufficient to
reduce the problem to one of nearly half the size.
-
c. Show that the good chips can be identified with Θ(n) pairwise tests, assuming that
more than n/2 of the chips are good. Give and solve the recurrence that describes the number of tests.
-
-
### `Answer`
a. 如果超过一半是坏的,那么我们可以从这些坏的中取出一组数量和好的一样多的,他们的表现能和好的一样.
-
b. 将所有的芯片两两配对,如果报告是both are good or bad,那么就从中随机选一个留下来,否则全部扔掉. 一直这样递归下去,最后剩下的是好的.
-
c. T(n) = T(n/2)+n/2,是Θ(n)的.
-
### Problems 7 : Monge arrays
-***
-An m × n array A of real numbers is a **Monge array** if for all i, j, k, and l such that 1 ≤ i < k ≤ m and 1 ≤ j < l ≤ n, we have
-
A[i, j] + A[k, l] ≤ A[i, l] + A[k, j].
-
In other words, whenever we pick two rows and two columns of a Monge array and consider the four elements at the intersections of the rows and the columns, the sum of the upper-left and lower-right elements is less or equal to the sum of the lower-left and upper-right elements. For example, the following array is Monge:
-

-
-a. Prove that an array is Monge if and only if for all i = 1,2,...,m-1 and j = 1,2,...,n- 1, we have
A[i, j] + A[i + 1, j + 1] ≤ A[i, j + 1] + A[i + 1, j].
Note (For the "only if" part, use induction separately on rows and columns.)
-
b. The following array is not Monge. Change one element in order to make it Monge.
-
-
-
-c. Let f(i) be the index of the column containing the leftmost minimum element of row i. Prove that f(1) ≤ f(2) ≤ ··· ≤ f(m) for any m × n Monge array.
-
-d. Here is a description of a divide-and-conquer algorithm that computes the left-most minimum element in each row of an m × n Monge array A:
Construct a submatrix A′ of A consisting of the even-numbered rows of A. Recursively determine the leftmost minimum for each row of A′. Then compute the leftmost minimum in the odd-numbered rows of A.
Explain how to compute the leftmost minimum in the odd-numbered rows of A (given that the leftmost minimum of the even-numbered rows is known) in O(m + n) time.
-
e. Write the recurrence describing the running time of the algorithm described in part (d). Show that its solution is O(m + n log m).
### `Answer`
-**a.**
-
-
-***
-
-
-**b.**
-
-
-
-**c.** **反证法**
-
-如果i < j,f(i) >= f(j)
-
-A[i,f(j)]+A[j,f(i))] <= A[i,f(i)]+A[j,f(j)] 但是A[i,f(i)]和A[j,f(j)]是两行最小的元素,等式不成立.
-
-**d.**根据c可以知道第i行的左端最小值落在f(i-1)和f(i+1)之间. 总共有n/2个奇数行,总共需要比较m次,所以是O(m+n).
-
-**e.**
-T(m) = T(m/2) + cn + dm = O(nlgm + m)
-
-[code](./exercise_code/findIndex.py)
-
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+
+a. Show that if more than n/2 chips are bad, the professor cannot necessarily determine which chips are good using any strategy based on this kind of pairwise test. Assume that the bad chips can conspire to fool the professor.
+
+b. Consider the problem of finding a single good chip from among n chips, assuming that
+more than n/2 of the chips are good. Show that ⌊n/2⌋ pairwise tests are sufficient to
+reduce the problem to one of nearly half the size.
+
+c. Show that the good chips can be identified with Θ(n) pairwise tests, assuming that
+more than n/2 of the chips are good. Give and solve the recurrence that describes the number of tests.
+
+
+### `Answer`
+a. 如果超过一半是坏的,那么我们可以从这些坏的中取出一组数量和好的一样多的,他们的表现能和好的一样.
+
+b. 将所有的芯片两两配对,如果报告是both are good or bad,那么就从中随机选一个留下来,否则全部扔掉. 一直这样递归下去,最后剩下的是好的.
+
+c. T(n) = T(n/2)+n/2,是Θ(n)的.
+
+
+### Problems 7 : Monge arrays
+***
+An m × n array A of real numbers is a **Monge array** if for all i, j, k, and l such that 1 ≤ i < k ≤ m and 1 ≤ j < l ≤ n, we have
+
+A[i, j] + A[k, l] ≤ A[i, l] + A[k, j].
+
+In other words, whenever we pick two rows and two columns of a Monge array and consider the four elements at the intersections of the rows and the columns, the sum of the upper-left and lower-right elements is less or equal to the sum of the lower-left and upper-right elements. For example, the following array is Monge:
+
+
+
+a. Prove that an array is Monge if and only if for all i = 1,2,...,m-1 and j = 1,2,...,n- 1, we have
+A[i, j] + A[i + 1, j + 1] ≤ A[i, j + 1] + A[i + 1, j].
+Note (For the "only if" part, use induction separately on rows and columns.)
+
+
+b. The following array is not Monge. Change one element in order to make it Monge.
+
+
+
+c. Let f(i) be the index of the column containing the leftmost minimum element of row i. Prove that f(1) ≤ f(2) ≤ ··· ≤ f(m) for any m × n Monge array.
+
+d. Here is a description of a divide-and-conquer algorithm that computes the left-most minimum element in each row of an m × n Monge array A:
+Construct a submatrix A′ of A consisting of the even-numbered rows of A. Recursively determine the leftmost minimum for each row of A′. Then compute the leftmost minimum in the odd-numbered rows of A.
+Explain how to compute the leftmost minimum in the odd-numbered rows of A (given that the leftmost minimum of the even-numbered rows is known) in O(m + n) time.
+
+
+e. Write the recurrence describing the running time of the algorithm described in part (d). Show that its solution is O(m + n log m).
+
+### `Answer`
+**a.**
+
+
+***
+
+
+**b.**
+
+
+
+**c.** **反证法**
+
+如果i < j,f(i) >= f(j)
+
+A[i,f(j)]+A[j,f(i))] <= A[i,f(i)]+A[j,f(j)] 但是A[i,f(i)]和A[j,f(j)]是两行最小的元素,等式不成立.
+
+**d.**根据c可以知道第i行的左端最小值落在f(i-1)和f(i+1)之间. 总共有n/2个奇数行,总共需要比较m次,所以是O(m+n).
+
+**e.**
+T(m) = T(m/2) + cn + dm = O(nlgm + m)
+
+[code](./exercise_code/findIndex.py)
+
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.2.md b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.2.md
index 89e348a6..e889268b 100644
--- a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.2.md
+++ b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.2.md
@@ -1,52 +1,52 @@
-### Exercises 5.2-1
-***
+### Exercises 5.2-1
+***
In HIRE-ASSISTANT, assuming that the candidates are presented in a random order, what is the probability that you will hire exactly one time? What is the probability that you will hire exactly n times?
-### `Answer`
-分别是1/n和1/n!
-
-
-### Exercises 5.2-2
-***
+### `Answer`
+分别是1/n和1/n!
+
+
+### Exercises 5.2-2
+***
In HIRE-ASSISTANT, assuming that the candidates are presented in a random order, what is the probability that you will hire exactly twice?
-
-### `Answer`
-如果第一个雇员的质量是k,那么质量高于k的雇员都必须在质量最高的雇员后面.
-
-假设有n个雇员,质量分别是1,2,...,n.当第一个质量为k时,只雇佣2次的概率p = 1/(n-k).因为有n-k个质量比k高的,而且必须要最高的那个在前.而第一个质量为k的概率是1/n.所以
-
-
-
-### Exercises 5.2-3
-***
-Use indicator random variables to compute the expected value of the sum of n dice.
-
-### `Answer`
-Expectation of a single die
-
- = \\frac{1+2+3+4+5+6}{6} = 3.5 )
-
-Expectation of N dies
-
- = \\sum_{i = 1}^{n} E\(X_i\) = 3.5n )
-
-### Exercises 5.2-4
-***
-Use indicator random variables to solve the following problem, which is known as the **hat- check problem**. Each of n customers gives a hat to a hat-check person at a restaurant. The hat- check person gives the hats back to the customers in a random order. What is the expected number of customers that get back their own hat?
-
-### `Answer`
-每个人都是1/n的期望,所以总的是1
-
-### Exercises 5.2-5
-***
-Let A[1...n] be an array of n distinct numbers. If i < j and A[i] > A[j], then the pair (i, j) is called an inversion of A. (See Problem 2-4 for more on inversions.) Suppose that each element of A is chosen randomly, independently, and uniformly from the range 1 through n. Use indicator random variables to compute the expected number of inversions.
-
-### `Answer`
-最简单的解法如下:
-
-因为概率是一样的,所以出现正序和逆序是等量的,总共有n(n-1)/2对,所以期望是n(n-1)/4对.
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+如果第一个雇员的质量是k,那么质量高于k的雇员都必须在质量最高的雇员后面.
+
+假设有n个雇员,质量分别是1,2,...,n.当第一个质量为k时,只雇佣2次的概率p = 1/(n-k).因为有n-k个质量比k高的,而且必须要最高的那个在前.而第一个质量为k的概率是1/n.所以
+
+
+
+### Exercises 5.2-3
+***
+Use indicator random variables to compute the expected value of the sum of n dice.
+
+### `Answer`
+Expectation of a single die
+
+ = \\frac{1+2+3+4+5+6}{6} = 3.5 )
+
+Expectation of N dies
+
+ = \\sum_{i = 1}^{n} E\(X_i\) = 3.5n )
+
+### Exercises 5.2-4
+***
+Use indicator random variables to solve the following problem, which is known as the **hat- check problem**. Each of n customers gives a hat to a hat-check person at a restaurant. The hat- check person gives the hats back to the customers in a random order. What is the expected number of customers that get back their own hat?
+
+### `Answer`
+每个人都是1/n的期望,所以总的是1
+
+### Exercises 5.2-5
+***
+Let A[1...n] be an array of n distinct numbers. If i < j and A[i] > A[j], then the pair (i, j) is called an inversion of A. (See Problem 2-4 for more on inversions.) Suppose that each element of A is chosen randomly, independently, and uniformly from the range 1 through n. Use indicator random variables to compute the expected number of inversions.
+
+### `Answer`
+最简单的解法如下:
+
+因为概率是一样的,所以出现正序和逆序是等量的,总共有n(n-1)/2对,所以期望是n(n-1)/4对.
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.3.md b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.3.md
index 134e688a..84f8551b 100644
--- a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.3.md
+++ b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.3.md
@@ -1,61 +1,81 @@
-### Exercises 5.3-1
-***
-Professor Marceau objects to the loop invariant used in the proof of Lemma 5.5. He questions whether it is true prior to the first iteration. His reasoning is that one could just as easily declare that an empty subarray contains no 0-permutations. Therefore, the probability that an empty subarray contains a 0-permutation should be 0, thus invalidating the loop invariant prior to the first iteration. Rewrite the procedure RANDOMIZE-IN-PLACE so that its associated loop invariant applies to a nonempty subarray prior to the first iteration, and modify the proof of Lemma 5.5 for your procedure.
-
-### `Answer`
-感觉这题完全没意义呀...
-
-
-### Exercises 5.3-2
-***
-Professor Kelp decides to write a procedure that will produce at random any permutation besides the identity permutation. He proposes the following procedure:
-
PERMUTE-WITHOUT-IDENTITY(A)
1 n ← length[A]
2 for i ← 1 to n
3 do swap A[i] ↔ A[RANDOM(i + 1, n)]
-
Does this code do what Professor Kelp intends?
-
-### `Answer`
-没有,因为[1,3,2...]这样的序列虽然不是identity permutation但是却不会产生.
-
-### Exercises 5.3-3
-***
-Suppose that instead of swapping element A[i] with a random element from the subarray A[i .. n], we swapped it with a random element from anywhere in the array:

-
- PERMUTE-WITH-ALL(A)
1 n ← length[A]
2 for i ← 1 to n
3 do swap A[i] ↔ A[RANDOM(1, n)]
Does this code produce a uniform random permutation? Why or why not?
-
-### `Answer`
-不可以,因为本来有n!种排列,但是这种做法每个迭代有n种选择,所以有n^n种选择.而n^n不能被n!整除,因此不是uniform的排列.
-
-### Exercises 5.3-4
-***
-Professor Armstrong suggests the following procedure for generating a uniform random permutation:
-
PERMUTE-BY-CYCLIC(A)
1 n ← length[A]
2 offset ← RANDOM(1, n)
- 3 for i <- i to n
- 4 do dest <- i + offset
- 5 if dest > n
- 6 then dest <- dest-n
- 7 B[dest] -< A[i]
- 8 return B
Show that each element A[i] has a 1/n probability of winding up in any particular position in B. Then show that Professor Armstrong is mistaken by showing that the resulting permutation is not uniformly random.
-
-### `Answer`
-这个算法对于给定的offset,只会产生一种排列...也就是最后只有n种排列而不是n!种. 只会将原数组**平移**,谈不上**随机**.
-
-### Exercises 5.3-5
-***
-Prove that in the array P in procedure PERMUTE-BY-SORTING, the probability that all
elements are unique is at least 1 - 1/n.
-
-### `Answer`
-\(1-\\frac{2}{n^3}\) \(1-\\frac{3}{n^3}\)\\ldots \\\\ ~ \\hspace{10 mm}
-\\ge 1\(1-\\frac{n}{n^3}\)\(1-\\frac{n}{n^3}\) \(1-\\frac{n}{n^3}\)\\ldots \\\\ ~ \\hspace{10 mm}
-\\ge \(1-\\frac{1}{n^2}\)^n \\\\ ~ \\hspace{10 mm}
-\\ge 1-\\frac{1}{n} )
-
-### Exercises 5.3-6
-***
-Explain how to implement the algorithm PERMUTE-BY-SORTING to handle the case in which two or more priorities are identical. That is, your algorithm should produce a uniform random permutation, even if two or more priorities are identical.
-
-### `Answer`
-既然冲突了,那就重新产生嘛...
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### Exercises 5.3-1
+***
+Professor Marceau objects to the loop invariant used in the proof of Lemma 5.5. He questions whether it is true prior to the first iteration. His reasoning is that one could just as easily declare that an empty subarray contains no 0-permutations. Therefore, the probability that an empty subarray contains a 0-permutation should be 0, thus invalidating the loop invariant prior to the first iteration. Rewrite the procedure RANDOMIZE-IN-PLACE so that its associated loop invariant applies to a nonempty subarray prior to the first iteration, and modify the proof of Lemma 5.5 for your procedure.
+
+
+### `Answer`
+感觉这题完全没意义呀...
+
+
+### Exercises 5.3-2
+***
+Professor Kelp decides to write a procedure that will produce at random any permutation besides the identity permutation. He proposes the following procedure:
+
+ PERMUTE-WITHOUT-IDENTITY(A)
+ 1 n ← length[A]
+ 2 for i ← 1 to n
+ 3 do swap A[i] ↔ A[RANDOM(i + 1, n)]
+
+
+Does this code do what Professor Kelp intends?
+
+### `Answer`
+没有,因为[1,3,2...]这样的序列虽然不是identity permutation但是却不会产生.
+
+### Exercises 5.3-3
+***
+Suppose that instead of swapping element A[i] with a random element from the subarray A[i .. n], we swapped it with a random element from anywhere in the array:
+
+
+ PERMUTE-WITH-ALL(A)
+ 1 n ← length[A]
+ 2 for i ← 1 to n
+ 3 do swap A[i] ↔ A[RANDOM(1, n)]
+
+Does this code produce a uniform random permutation? Why or why not?
+
+### `Answer`
+不可以,因为本来有n!种排列,但是这种做法每个迭代有n种选择,所以有n^n种选择.而n^n不能被n!整除,因此不是uniform的排列.
+
+### Exercises 5.3-4
+***
+Professor Armstrong suggests the following procedure for generating a uniform random permutation:
+
+ PERMUTE-BY-CYCLIC(A)
+ 1 n ← length[A]
+ 2 offset ← RANDOM(1, n)
+ 3 for i <- i to n
+ 4 do dest <- i + offset
+ 5 if dest > n
+ 6 then dest <- dest-n
+ 7 B[dest] -< A[i]
+ 8 return B
+
+
+Show that each element A[i] has a 1/n probability of winding up in any particular position in B. Then show that Professor Armstrong is mistaken by showing that the resulting permutation is not uniformly random.
+
+### `Answer`
+这个算法对于给定的offset,只会产生一种排列...也就是最后只有n种排列而不是n!种. 只会将原数组**平移**,谈不上**随机**.
+
+### Exercises 5.3-5
+***
+Prove that in the array P in procedure PERMUTE-BY-SORTING, the probability that all
+elements are unique is at least 1 - 1/n.
+
+### `Answer`
+\(1-\\frac{2}{n^3}\) \(1-\\frac{3}{n^3}\)\\ldots \\\\ ~ \\hspace{10 mm}
+\\ge 1\(1-\\frac{n}{n^3}\)\(1-\\frac{n}{n^3}\) \(1-\\frac{n}{n^3}\)\\ldots \\\\ ~ \\hspace{10 mm}
+\\ge \(1-\\frac{1}{n^2}\)^n \\\\ ~ \\hspace{10 mm}
+\\ge 1-\\frac{1}{n} )
+
+### Exercises 5.3-6
+***
+Explain how to implement the algorithm PERMUTE-BY-SORTING to handle the case in which two or more priorities are identical. That is, your algorithm should produce a uniform random permutation, even if two or more priorities are identical.
+
+### `Answer`
+既然冲突了,那就重新产生嘛...
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.4.md b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.4.md
index ec9bdf9a..2ca00868 100644
--- a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.4.md
+++ b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/5.4.md
@@ -1,67 +1,69 @@
-### Exercises 5.4-1
-***
-How many people must there be in a room before the probability that someone has the same birthday as you do is at least 1/2? How many people must there be before the probability that at least two people have a birthday on July 4 is greater than 1/2?
-
-### `Answer`
-^n \\ge \\frac{1}{2} \\rightarrow n \\ge 253 )
-
-\(\\frac{364}{365}\)^{n-1} - C^0_n\(\\frac{364}{365}\)^n \\ge \\frac{1}{2} \\rightarrow n \\ge 613 )
-
-
-### Exercises 5.4-2
-***
+### Exercises 5.4-1
+***
+How many people must there be in a room before the probability that someone has the same birthday as you do is at least 1/2? How many people must there be before the probability that at least two people have a birthday on July 4 is greater than 1/2?
+
+
+### `Answer`
+^n \\ge \\frac{1}{2} \\rightarrow n \\ge 253 )
+
+\(\\frac{364}{365}\)^{n-1} - C^0_n\(\\frac{364}{365}\)^n \\ge \\frac{1}{2} \\rightarrow n \\ge 613 )
+
+
+### Exercises 5.4-2
+***
Suppose that balls are tossed into b bins. Each toss is independent, and each ball is equally likely to end up in any bin. What is the expected number of ball tosses before at least one of the bins contains two balls?
-
-### `Answer`
-This is a rewording of the Birthday Problem. The answer is the following:
-
- = 1 + \\sum_{k = 1}^{B} \\frac{B!}{\(B-k\)!B^k} )
-
-check [Quora](http://www.quora.com/What-is-the-expected-number-of-ball-tosses-until-some-bin-contains-two-balls) and [wiki](https://en.wikipedia.org/wiki/Birthday_problem#Average_number_of_people)
-### Exercises 5.4-3
-***
+
+### `Answer`
+This is a rewording of the Birthday Problem. The answer is the following:
+
+ = 1 + \\sum_{k = 1}^{B} \\frac{B!}{\(B-k\)!B^k} )
+
+check [Quora](http://www.quora.com/What-is-the-expected-number-of-ball-tosses-until-some-bin-contains-two-balls) and [wiki](https://en.wikipedia.org/wiki/Birthday_problem#Average_number_of_people)
+### Exercises 5.4-3
+***
For the analysis of the birthday paradox, is it important that the birthdays be mutually independent, or is pairwise independence sufficient? Justify your answer.
-
-### `Answer`
-Pairwise independence is sufficient.
-
-### Exercises 5.4-4
-***
-How many people should be invited to a party in order to make it likely that there are three people with the same birthday?
-
-### `Answer`
-If n=365 and k is the number of people at the party:
-
-
-
-
-### Exercises 5.4-5
-***
-What is the probability that a k-string over a set of size n is actually a k-permutation? How does this question relate to the birthday paradox?
-
-### `Answer`
-
-
-To be a k-permutation, there can be no repeated letters, so this is the birthday problem where k is the number of people and n is the number of days.
-
-### Exercises 5.4-6
-***
-Suppose that n balls are tossed into n bins, where each toss is independent and the ball is equally likely to end up in any bin. What is the expected number of empty bins? What is the expected number of bins with exactly one ball?
-
-### `Answer`
-
-^n = \(1-\\frac{1}{n}\)^n \\approx \\frac{1}{e} \\\\
-E[X] = \\sum_{1}^{n}E[X_i] = \\frac{n}{e} \\\\
-Pr\\{Y_i\\} \\quad\\text{is the probability that ith has one ball} \\\\
- P_r\\{Y_i\\} = n \\cdot \\frac{1}{n} \(\\frac{n-1}{n}\)^{n-1} \\approx \\frac{1}{e} \\\\E[Y] = \\sum_{1}^{n}E[Y_i] = \\frac{n}{e} \\\\)
-
-
-### Exercises 5.4-7
-***
-Sharpen the lower bound on streak length by showing that in n flips of a fair coin, the
probability is less than 1/n that no streak longer than lg n-2 lg lg n consecutive heads occurs.
-### `Answer`
-**UNSOLVED**
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+Pairwise independence is sufficient.
+
+### Exercises 5.4-4
+***
+How many people should be invited to a party in order to make it likely that there are three people with the same birthday?
+
+### `Answer`
+If n=365 and k is the number of people at the party:
+
+
+
+
+### Exercises 5.4-5
+***
+What is the probability that a k-string over a set of size n is actually a k-permutation? How does this question relate to the birthday paradox?
+
+### `Answer`
+
+
+To be a k-permutation, there can be no repeated letters, so this is the birthday problem where k is the number of people and n is the number of days.
+
+### Exercises 5.4-6
+***
+Suppose that n balls are tossed into n bins, where each toss is independent and the ball is equally likely to end up in any bin. What is the expected number of empty bins? What is the expected number of bins with exactly one ball?
+
+### `Answer`
+
+^n = \(1-\\frac{1}{n}\)^n \\approx \\frac{1}{e} \\\\
+E[X] = \\sum_{1}^{n}E[X_i] = \\frac{n}{e} \\\\
+Pr\\{Y_i\\} \\quad\\text{is the probability that ith has one ball} \\\\
+ P_r\\{Y_i\\} = n \\cdot \\frac{1}{n} \(\\frac{n-1}{n}\)^{n-1} \\approx \\frac{1}{e} \\\\E[Y] = \\sum_{1}^{n}E[Y_i] = \\frac{n}{e} \\\\)
+
+
+### Exercises 5.4-7
+***
+Sharpen the lower bound on streak length by showing that in n flips of a fair coin, the
+probability is less than 1/n that no streak longer than lg n-2 lg lg n consecutive heads occurs.
+### `Answer`
+**UNSOLVED**
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/problem.md b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/problem.md
index f39bada5..57a0cc91 100644
--- a/C05-Probabilistic-Analysis-and-Randomized-Algorithms/problem.md
+++ b/C05-Probabilistic-Analysis-and-Randomized-Algorithms/problem.md
@@ -1,80 +1,116 @@
-### Problems 1 : Probabilistic counting
-***
-With a b-bit counter, we can ordinarily only count up to 2b - 1. With R. Morris's probabilistic counting, we can count up to a much larger value at the expense of some loss of precision.

-We let a counter value of i represent a count of ni for i = 0, 1,..., 2b -1, where the ni form an increasing sequence of nonnegative values. We assume that the initial value of the counter is 0, representing a count of n0 = 0. The INCREMENT operation works on a counter containing the value i in a probabilistic manner. If i = 2b - 1, then an overflow error is reported. Otherwise, the counter is increased by 1 with probability 1/(ni+1 - ni), and it remains unchanged with probability 1 - 1/(ni+1 - ni).
-
If we select ni = i for all i ≥ 0, then the counter is an ordinary one. More interesting situations arise if we select, say, ni = 2i-1 for i > 0 or ni = Fi (the ith Fibonacci number-see Section 3.2).
-
For this problem, assume that n_(2^b-1) is large enough that the probability of an overflow error is negligible.
-
a. Show that the expected value represented by the counter after n INCREMENT operations have been performed is exactly n.
-
b. The analysis of the variance of the count represented by the counter depends on the sequence of the ni. Let us consider a simple case: ni = 100i for all i ≥ 0. Estimate the variance in the value represented by the register after n INCREMENT operations have been performed.
-
-### `Answer`
-**a.**
-每一次递增操作增加的期望为
-
- + 1\\cdot \(n_{i+1}-n_i\) \\cdot \\frac{1}{n_{i+1}-n_i} = 1 )
-
-**b.**
-
- - 1^2 = 99 \\\\
-Var[X] = \\sum_{i= 1}^{n}Var[X_i] = 99n)
-
-
-### Problems 2 : Searching an unsorted array
-***
-Thus problem examines three algorithms for searching for a value x in an unsorted array A consisting of n elements.
-
Consider the following randomized strategy: pick a random index i into A. If A[i] = x, then we terminate; otherwise, we continue the search by picking a new random index into A. We continue picking random indices into A until we find an index j such that A[j] = x or until we have checked every element of A. Note that we pick from the whole set of indices each time, so that we may examine a given element more than once.
-
**a.** Write pseudocode for a procedure RANDOM-SEARCH to implement the strategy above. Be sure that your algorithm terminates when all indices into A have been picked.
-
**b.** Suppose that there is exactly one index i such that A[i] = x. What is the expected number of indices into A that must be picked before x is found and RANDOM- SEARCH terminates?
-
**c.** Generalizing your solution to part (b), suppose that there are k ≥ 1 indices i such that A[i] = x. What is the expected number of indices into A that must be picked before x is found and RANDOM-SEARCH terminates? Your answer should be a function of n and k.
-
**d.** Suppose that there are no indices i such that A[i] = x. What is the expected number of indices into A that must be picked before all elements of A have been checked and RANDOM-SEARCH terminates?
-
Now consider a deterministic linear search algorithm, which we refer to as DETERMINISTIC-SEARCH. Specifically, the algorithm searches A for x in order,
considering A[1], A[2], A[3],..., A[n] until either A[i] = x is found or the end of the array is reached. Assume that all possible permutations of the input array are equally likely.
-
**e.** Suppose that there is exactly one index i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH?
-
**f.** Generalizing your solution to part (e), suppose that there are k ≥ 1 indices i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH? Your answer should be a function of n and k.
-
**g.** Suppose that there are no indices i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH?
-
Finally, consider a randomized algorithm SCRAMBLE-SEARCH that works by first randomly permuting the input array and then running the deterministic linear search given above on the resulting permuted array.
-
**h.** Letting k be the number of indices i such that A[i] = x, give the worst-case and expected running times of SCRAMBLE-SEARCH for the cases in which k = 0 and k = 1. Generalize your solution to handle the case in which k ≥ 1.
-
**i.** Which of the three searching algorithms would you use? Explain your answer.
-
### `Answer`
-
**a.**
-
RANDOM-SEARCH(A, v):
- B = new array[n]
- count = 0
- while(count < n):
- r = RANDOM(1, n)
- if A[r] == v:
- return r
- if B[r] == false:
- count += 1
- B[r] = true
- return false
-
-**b.**
-就是几何分布~n
-
-**c.**
-还是几何分布~n/k
-
-**d.**
-Section5.4.2,在每个盒子里至少有一个球前,要投多少个球.
-
-n(lnn+O(1))
-
-**e.**
-平均查找时间是n/2,最坏查找时间是n
-
-**f.**
-最坏运行时间是n-k+1.平均运行时间是n/(k+1)
-
-**g.**
-都是n
-
-**h.**
-跟DETERMINISTIC-SEARCH是一样的,这时候的期望就是平均.
-
-**i.**
-自然是**DETERMINISTIC-SEARCH**
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### Problems 1 : Probabilistic counting
+***
+With a b-bit counter, we can ordinarily only count up to 2b - 1. With R. Morris's probabilistic counting, we can count up to a much larger value at the expense of some loss of precision.
+
+We let a counter value of i represent a count of ni for i = 0, 1,..., 2b -1, where the ni form an increasing sequence of nonnegative values. We assume that the initial value of the counter is 0, representing a count of n0 = 0. The INCREMENT operation works on a counter containing the value i in a probabilistic manner. If i = 2b - 1, then an overflow error is reported. Otherwise, the counter is increased by 1 with probability 1/(ni+1 - ni), and it remains unchanged with probability 1 - 1/(ni+1 - ni).
+
+If we select ni = i for all i ≥ 0, then the counter is an ordinary one. More interesting situations arise if we select, say, ni = 2i-1 for i > 0 or ni = Fi (the ith Fibonacci number-see Section 3.2).
+
+
+For this problem, assume that n_(2^b-1) is large enough that the probability of an overflow error is negligible.
+
+
+a. Show that the expected value represented by the counter after n INCREMENT operations have been performed is exactly n.
+
+
+b. The analysis of the variance of the count represented by the counter depends on the sequence of the ni. Let us consider a simple case: ni = 100i for all i ≥ 0. Estimate the variance in the value represented by the register after n INCREMENT operations have been performed.
+
+### `Answer`
+**a.**
+每一次递增操作增加的期望为
+
+ + 1\\cdot \(n_{i+1}-n_i\) \\cdot \\frac{1}{n_{i+1}-n_i} = 1 )
+
+**b.**
+
+ - 1^2 = 99 \\\\
+Var[X] = \\sum_{i= 1}^{n}Var[X_i] = 99n)
+
+
+### Problems 2 : Searching an unsorted array
+***
+Thus problem examines three algorithms for searching for a value x in an unsorted array A consisting of n elements.
+
+Consider the following randomized strategy: pick a random index i into A. If A[i] = x, then we terminate; otherwise, we continue the search by picking a new random index into A. We continue picking random indices into A until we find an index j such that A[j] = x or until we have checked every element of A. Note that we pick from the whole set of indices each time, so that we may examine a given element more than once.
+
+**a.** Write pseudocode for a procedure RANDOM-SEARCH to implement the strategy above. Be sure that your algorithm terminates when all indices into A have been picked.
+
+
+**b.** Suppose that there is exactly one index i such that A[i] = x. What is the expected number of indices into A that must be picked before x is found and RANDOM- SEARCH terminates?
+
+
+**c.** Generalizing your solution to part (b), suppose that there are k ≥ 1 indices i such that A[i] = x. What is the expected number of indices into A that must be picked before x is found and RANDOM-SEARCH terminates? Your answer should be a function of n and k.
+
+
+**d.** Suppose that there are no indices i such that A[i] = x. What is the expected number of indices into A that must be picked before all elements of A have been checked and RANDOM-SEARCH terminates?
+
+
+Now consider a deterministic linear search algorithm, which we refer to as DETERMINISTIC-SEARCH. Specifically, the algorithm searches A for x in order,
+considering A[1], A[2], A[3],..., A[n] until either A[i] = x is found or the end of the array is reached. Assume that all possible permutations of the input array are equally likely.
+
+
+**e.** Suppose that there is exactly one index i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH?
+
+
+**f.** Generalizing your solution to part (e), suppose that there are k ≥ 1 indices i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH? Your answer should be a function of n and k.
+
+
+**g.** Suppose that there are no indices i such that A[i] = x. What is the expected running time of DETERMINISTIC-SEARCH? What is the worst-case running time of DETERMINISTIC-SEARCH?
+
+
+Finally, consider a randomized algorithm SCRAMBLE-SEARCH that works by first randomly permuting the input array and then running the deterministic linear search given above on the resulting permuted array.
+
+**h.** Letting k be the number of indices i such that A[i] = x, give the worst-case and expected running times of SCRAMBLE-SEARCH for the cases in which k = 0 and k = 1. Generalize your solution to handle the case in which k ≥ 1.
+
+
+**i.** Which of the three searching algorithms would you use? Explain your answer.
+
+
+### `Answer`
+
+**a.**
+
+
+ RANDOM-SEARCH(A, v):
+ B = new array[n]
+ count = 0
+ while(count < n):
+ r = RANDOM(1, n)
+ if A[r] == v:
+ return r
+ if B[r] == false:
+ count += 1
+ B[r] = true
+ return false
+
+**b.**
+就是几何分布~n
+
+**c.**
+还是几何分布~n/k
+
+**d.**
+Section5.4.2,在每个盒子里至少有一个球前,要投多少个球.
+
+n(lnn+O(1))
+
+**e.**
+平均查找时间是n/2,最坏查找时间是n
+
+**f.**
+最坏运行时间是n-k+1.平均运行时间是n/(k+1)
+
+**g.**
+都是n
+
+**h.**
+跟DETERMINISTIC-SEARCH是一样的,这时候的期望就是平均.
+
+**i.**
+自然是**DETERMINISTIC-SEARCH**
+
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C06-Heapsort/6.3.md b/C06-Heapsort/6.3.md
index e1bcfa71..c287ba89 100644
--- a/C06-Heapsort/6.3.md
+++ b/C06-Heapsort/6.3.md
@@ -1,35 +1,38 @@
-### Exercises 6.3-1
-***
-Using Figure 6.3 as a model, illustrate the operation of BUILD-MAX-HEAP on the array A = [5, 3, 17, 10, 84, 19, 6, 22, 9].
-
-### `Answer`
-
-
-
-### Exercises 6.3-2
-***
-Why do we want the loop index i in line 2 of BUILD-MAX-HEAP to decrease from ⌞length[A]/2⌟ to 1 rather than increase from 1 to ⌞length[A]/2⌟?
-
-### `Answer`
-如果先从1开始,它的子树并不是最大堆,肯定不能这样迭代.
-
-If we start from 1, because its subtree is not a maximum heap, we can't follow this order.
-
-### Exercises 6.3-3
-***
+### Exercises 6.3-1
+***
+Using Figure 6.3 as a model, illustrate the operation of BUILD-MAX-HEAP on the array A = [5, 3, 17, 10, 84, 19, 6, 22, 9].
+
+
+
+### `Answer`
+
+
+
+### Exercises 6.3-2
+***
+Why do we want the loop index i in line 2 of BUILD-MAX-HEAP to decrease from ⌞length[A]/2⌟ to 1 rather than increase from 1 to ⌞length[A]/2⌟?
+
+
+### `Answer`
+如果先从1开始,它的子树并不是最大堆,肯定不能这样迭代.
+
+If we start from 1, because its subtree is not a maximum heap, we can't follow this order.
+
+### Exercises 6.3-3
+***
Show that there are at most  \\rceil) nodes of height h in any n-element heap.
-
-### `Answer`
-According to [6.1.1](./6.1.md)we have
-
-
-
-Mark h0 as the height of tree.
-
- \\rceil \\le \\lceil \(2^{h_0+1}-1\)/\(2^{h+1}\) \\rceil = 2^{h_0-h})
-
-If the current layer is full, then we have equal. If in the leaf node and not full, we have less.
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+According to [6.1.1](./6.1.md)we have
+
+
+
+Mark h0 as the height of tree.
+
+ \\rceil \\le \\lceil \(2^{h_0+1}-1\)/\(2^{h+1}\) \\rceil = 2^{h_0-h})
+
+If the current layer is full, then we have equal. If in the leaf node and not full, we have less.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C06-Heapsort/6.4.md b/C06-Heapsort/6.4.md
index 42973d63..6a3bb133 100644
--- a/C06-Heapsort/6.4.md
+++ b/C06-Heapsort/6.4.md
@@ -1,45 +1,49 @@
-### Exercises 6.4-1
-***
-Using Figure 6.4 as a model, illustrate the operation of HEAPSORT on the array A = [5, 13, 2, 25, 7, 17, 20, 8, 4].
-
-### `Answer`
-
-
-
-### Exercises 6.4-2
-***
-Argue the correctness of HEAPSORT using the following loop invariant:
-
• At the start of each iteration of the for loop of lines 2-5, the subarray A[1...i] is a max-heap containing the i smallest elements of A[1...n], and the subarray A[i + 1...n] contains the n - i largest elements of A[1...n], sorted.
-
-### `Answer`
-It is very obvious.
-
-### Exercises 6.4-3
-***
+### Exercises 6.4-1
+***
+Using Figure 6.4 as a model, illustrate the operation of HEAPSORT on the array A = [5, 13, 2, 25, 7, 17, 20, 8, 4].
+
+
+
+### `Answer`
+
+
+
+### Exercises 6.4-2
+***
+Argue the correctness of HEAPSORT using the following loop invariant:
+
+• At the start of each iteration of the for loop of lines 2-5, the subarray A[1...i] is a max-heap containing the i smallest elements of A[1...n], and the subarray A[i + 1...n] contains the n - i largest elements of A[1...n], sorted.
+
+
+### `Answer`
+It is very obvious.
+
+### Exercises 6.4-3
+***
What is the running time of heapsort on an array A of length n that is already sorted in increasing order? What about decreasing order?
-
-### `Answer`
-If the array is in descending order, then we have the worst case, we need
-
- )
-
-If it is in increasing order, we still need ),Because the cost of Max_heapify doesn't change.
-
-
-### Exercises 6.4-4
-***
-Show that the worst-case running time of heapsort is Ω(n lg n).
-
-### `Answer`
-Same as 6.3.3.
-
-### Exercises 6.4-5
-***
-Show that when all elements are distinct, the best-case running time of heapsort is Ω(n lg n).
-
-### `Answer`
-It is actually a hard problem, see [solution](http://stackoverflow.com/questions/4589988/lower-bound-on-heapsort)
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+If the array is in descending order, then we have the worst case, we need
+
+ )
+
+If it is in increasing order, we still need ),Because the cost of Max_heapify doesn't change.
+
+
+### Exercises 6.4-4
+***
+Show that the worst-case running time of heapsort is Ω(n lg n).
+
+### `Answer`
+Same as 6.3.3.
+
+### Exercises 6.4-5
+***
+Show that when all elements are distinct, the best-case running time of heapsort is Ω(n lg n).
+
+### `Answer`
+It is actually a hard problem, see [solution](http://stackoverflow.com/questions/4589988/lower-bound-on-heapsort)
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C06-Heapsort/problem.md b/C06-Heapsort/problem.md
index eae8471c..80bc8895 100644
--- a/C06-Heapsort/problem.md
+++ b/C06-Heapsort/problem.md
@@ -1,66 +1,98 @@
-### Problems 1 : Building a heap using insertion
-***
-The procedure BUILD-MAX-HEAP in Section 6.3 can be implemented by repeatedly using MAX-HEAP-INSERT to insert the elements into the heap. Consider the following implementation:
-
- BUILD-MAX-HEAP'(A)
heap-size[A] ← 1
for i←2 to length[A]
do MAX-HEAP-INSERT(A, A[i])
-
-a. Do the procedures BUILD-MAX-HEAP and BUILD-MAX-HEAP' always create the same heap when run on the same input array? Prove that they do, or provide a counterexample.

-b. Show that in the worst case, BUILD-MAX-HEAP' requires Θ(n lg n) time to build an n-element heap.
-
-### `Answer`
-**a.**
-不一定.对于数组[1,2,3,4,5,6].有
-
-
-
-
-**b.**
-当原数组是递增序列时,需要的时间
-
- )
-
-
-
-### Problems 2 : Analysis of d-ary heaps
-***
-A d-ary heap is like a binary heap, but (with one possible exception) non-leaf nodes have d children instead of 2 children.
-
a. How would you represent a d-ary heap in an array?
b. What is the height of a d-ary heap of n elements in terms of n and d?
c. Give an efficient implementation of EXTRACT-MAX in a d-ary max-heap. Analyze
its running time in terms of d and n.
d. Give an efficient implementation of INSERT in a d-ary max-heap. Analyze its running
time in terms of d and n.
e. Give an efficient implementation of INCREASE-KEY(A, i, k), which first sets A[i] ←
max(A[i], k) and then updates the d-ary max-heap structure appropriately. Analyze its running time in terms of d and n.
-### `Answer`
-[implementation](./d-ary-heaps.cpp)
-
-
-
-
-
-
-### Problems 3 : Young tableaus
-***
-An m × n Young tableau is an m × n matrix such that the entries of each row are in sorted order from left to right and the entries of each column are in sorted order from top to bottom. Some of the entries of a Young tableau may be ∞, which we treat as nonexistent elements. Thus, a Young tableau can be used to hold r ≤ mn finite numbers.
-
a. Draw a 4×4 Young tableau containing the elements {9, 16, 3, 2, 4, 8, 5, 14, 12}.
b. Arguethatanm×nYoungtableauYisemptyifY[1,1]=∞.ArguethatYisfull
(contains mn elements) if Y[m, n] < ∞.
c. Give an algorithm to implement EXTRACT-MIN on a nonempty m × n Young
tableau that runs in O(m + n) time. Your algorithm should use a recursive subroutine that solves an m × n problem by recursively solving either an (m - 1) × n or an m × (n - 1) subproblem. (Hint: Think about MAX-HEAPIFY.) Define T(p), where p = m + n, to be the maximum running time of EXTRACT-MIN on any m × n Young tableau. Give and solve a recurrence for T(p) that yields the O(m + n) time bound.
d. Show how to insert a new element into a nonfull m × n Young tableau in O(m + n) time.
e. Using no other sorting method as a subroutine, show how to use an n × n Young tableau to sort n^2 numbers in O(n^3) time.
f. Give an O(m+n)-time algorithm to determine whether a given number is stored in a given m × n Young tableau.
-
### `Answer`
-
[implementation](./young.cpp)
-
**a.**
-
-
-
**b.**
-
这是显然的~
-
**c.**
-T(p) = T(p-1) + O(1) = O(p)
-
+### Problems 1 : Building a heap using insertion
+***
+The procedure BUILD-MAX-HEAP in Section 6.3 can be implemented by repeatedly using MAX-HEAP-INSERT to insert the elements into the heap. Consider the following implementation:
+
+ BUILD-MAX-HEAP'(A)
+ heap-size[A] ← 1
+ for i←2 to length[A]
+ do MAX-HEAP-INSERT(A, A[i])
+
+
+a. Do the procedures BUILD-MAX-HEAP and BUILD-MAX-HEAP' always create the same heap when run on the same input array? Prove that they do, or provide a counterexample.
+
+b. Show that in the worst case, BUILD-MAX-HEAP' requires Θ(n lg n) time to build an n-element heap.
+
+### `Answer`
+**a.**
+不一定.对于数组[1,2,3,4,5,6].有
+
+
+
+
+**b.**
+当原数组是递增序列时,需要的时间
+
+ )
+
+
+
+### Problems 2 : Analysis of d-ary heaps
+***
+A d-ary heap is like a binary heap, but (with one possible exception) non-leaf nodes have d children instead of 2 children.
+
+a. How would you represent a d-ary heap in an array?
+b. What is the height of a d-ary heap of n elements in terms of n and d?
+c. Give an efficient implementation of EXTRACT-MAX in a d-ary max-heap. Analyze
+its running time in terms of d and n.
+d. Give an efficient implementation of INSERT in a d-ary max-heap. Analyze its running
+time in terms of d and n.
+e. Give an efficient implementation of INCREASE-KEY(A, i, k), which first sets A[i] ←
+max(A[i], k) and then updates the d-ary max-heap structure appropriately. Analyze its running time in terms of d and n.
+
+### `Answer`
+[implementation](./d-ary-heaps.cpp)
+
+
+
+
+
+
+### Problems 3 : Young tableaus
+***
+An m × n Young tableau is an m × n matrix such that the entries of each row are in sorted order from left to right and the entries of each column are in sorted order from top to bottom. Some of the entries of a Young tableau may be ∞, which we treat as nonexistent elements. Thus, a Young tableau can be used to hold r ≤ mn finite numbers.
+
+a. Draw a 4×4 Young tableau containing the elements {9, 16, 3, 2, 4, 8, 5, 14, 12}.
+b. Arguethatanm×nYoungtableauYisemptyifY[1,1]=∞.ArguethatYisfull
+(contains mn elements) if Y[m, n] < ∞.
+c. Give an algorithm to implement EXTRACT-MIN on a nonempty m × n Young
+tableau that runs in O(m + n) time. Your algorithm should use a recursive subroutine that solves an m × n problem by recursively solving either an (m - 1) × n or an m × (n - 1) subproblem. (Hint: Think about MAX-HEAPIFY.) Define T(p), where p = m + n, to be the maximum running time of EXTRACT-MIN on any m × n Young tableau. Give and solve a recurrence for T(p) that yields the O(m + n) time bound.
+d. Show how to insert a new element into a nonfull m × n Young tableau in O(m + n) time.
+e. Using no other sorting method as a subroutine, show how to use an n × n Young tableau to sort n^2 numbers in O(n^3) time.
+f. Give an O(m+n)-time algorithm to determine whether a given number is stored in a given m × n Young tableau.
+
+
+### `Answer`
+
+[implementation](./young.cpp)
+
+**a.**
+
+
+
+
+**b.**
+
+这是显然的~
+
+
+**c.**
+T(p) = T(p-1) + O(1) = O(p)
+
**d.**
-跟c是一个相反的操作,具体见代码.
-
-**e.**
- = O\(n^3\))
-
-**f.**
-实现见代码.
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+跟c是一个相反的操作,具体见代码.
+
+**e.**
+ = O\(n^3\))
+
+**f.**
+实现见代码.
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C07-Quicksort/problem.md b/C07-Quicksort/problem.md
index ba81fe76..2055d5a3 100644
--- a/C07-Quicksort/problem.md
+++ b/C07-Quicksort/problem.md
@@ -1,232 +1,265 @@
-### Problems 1 : Hoare partition correctness
-***
-The version of PARTITION given in this chapter is not the original partitioning algorithm. Here is the original partition algorithm, which is due to T. Hoare:
-
- HOARE-PARTITION(A, p, r):
x <- A[p]
- i <- p - 1
- j <- r + 1
- while TRUE:
- do repeat j <- j - 1
- until A[j] <= x
- repeat i <- i + 1
- until A[i] >= x
- if i < j:
- then exchange A[i] <-> A[j]
- else return j
-
-
-**a.** Demonstrate the operation of HOARE-PARTITION on the array A = [13, 19, 9, 5, 12, 8, 7, 4, 11, 2, 6, 21], showing the values of the array and auxiliary values after each iteration of the for loop in lines 4-11.
-
-The next three questions ask you to give a careful argument that the procedure HOARE- PARTITION is correct. Prove the following:
-
-**b.** The indices i and j are such that we never access an element of A outside the subarray A[p...r].
-
**c.** When HOARE-PARTITION terminates, it returns a value j such that p ≤ j < r.
-
**d.** Every element of A[p...j] is less than or equal to every element of A[j+1...r] when
HOARE-PARTITION terminates.
-
The PARTITION procedure in Section 7.1 separates the pivot value (originally in A[r]) from the two partitions it forms. The HOARE-PARTITION procedure, on the other hand, always places the pivot value (originally in A[p]) into one of the two partitions A[p...j] and A[j + 1...r]. Since p ≤ j < r, this split is always nontrivial.
-
**e.** Rewrite the QUICKSORT procedure to use HOARE-PARTITION.
-### `Answer`
-**a.**
-
-
-
-
-**b.**
-
-这是肯定的,因为i,j是往中间靠拢的.
-
-**c.**
-j至少会减2次. 若第一次进入while,j只减了1次,那么会做一次swap.然后继续进入while.
-
-**d.**
-
-很显然,小于x的放前面了,大于等于x的在后面.
-
-**e.**
-
-[implementation](./exercise_code/hoare.py)
-
-
-### Problems 2 : Alternative quicksort analysis
-***
-An alternative analysis of the running time of randomized quicksort focuses on the expected running time of each individual recursive call to QUICKSORT, rather than on the number of comparisons performed.
-
**a.** Argue that, given an array of size n, the probability that any particular element is chosen as the pivot is 1/n. Use this to define indicator random variables Xi = I{ith smallest element is chosen as the pivot}. What is E [Xi]?
-
**b.** Let T (n) be a random variable denoting the running time of quicksort on an array of size n. Argue that
-] = E\\bigg[\\sum_{q=1}^nX_q\(T\(q-1\) + T\(n-q\) + \\Theta\(n\)\)\\bigg] )
-
**c.**
Show that equation (7.5) simplifies to
-
-] = \\frac{2}{n}\\sum_{q=2}^{n-1}E[T\(q\)] + \\Theta\(n\) )
-
-**d.**
-Show that
-
-
-
-**e.**
-
-Using the bound from equation (7.7), show that the recurrence in equation (7.6) has
the solution E [T (n)] = Θ(n lg n). (Hint: Show, by substitution, that E[T (n)] ≤ an log n - bn for some positive constants a and b.)
-
-
### `Answer`
**a.**
-
E[Xi]=1/n.
-
**b.**
-
-这个算式的本质和之前分析快速排序的算式是一样的.
-
-**c.**
-
-就是简单的化简
-
-**d.**
-
- + \\sum_{k=n/2 + 1}^{n}k\\lg{n} \\\\ ~ \\hspace{22 mm}
- = \\lg\(n/2\)\\sum_{k=2}^{n/2}k + \\lg{n}\\sum_{k=n/2 + 1}^{n}k \\\\ ~ \\hspace{22 mm}
- = \(\\lg{n} - \\lg{2}\)\\bigg\(\\frac{\(n/2\)\(n/2 + 1\)}{2}\\bigg\) + \\lg{n}\\bigg\(\\frac{n\(n+1\)}{2} - \\frac{\(n/2\)\(n/2 + 1\)}{2}\\bigg\) \\\\ ~ \\hspace{22 mm}
- = \\lg{n}\\frac{n\(n+1\)}{2} - \\frac{\(n/2\)\(n/2 + 1\)}{2} \\\\ ~ \\hspace{22 mm}
- = \\frac{1}{2}\\lg{n}\(n^2 + 2n + 1\) - \\frac{1}{8}\(n^2 + 2n + 1/8\) \\\\ ~ \\hspace{22 mm}
- = \\frac{1}{2}n^2\\lg{n} - \\frac{1}{8}n^2 - \\frac{8n\\lg{n} + 4\\lg{n} - 2n - 1/8}{8} \\\\ ~ \\hspace{22 mm}
- \\le \\frac{1}{2}n^2\\lg{n} - \\frac{1}{8}n^2)
-
-**e.**
-
-我们猜想 E[T(n)] ≤ anlgn
-
-] = \\frac{2}{n}\\sum_{q=2}^{n-1}E[T\(q\)] + \\Theta\(n\) \\\\ ~ \\hspace{21 mm}
- \\le \\frac{2}{n}\\sum_{q=2}^{n-1}an\\lg{n} + \\Theta\(n\) \\\\ ~ \\hspace{21 mm}
- \\le \\frac{2a}{n}\\bigg\(\\frac{1}{2}n^2\\lg{n} - \\frac{1}{8}n^2\\bigg\)
- + \\Theta\(n\) \\\\\ ~ \\hspace{21 mm}
- = an\\lg{n} - \\frac{a}{4}n + \\Theta\(n\) \\\\ ~ \\hspace{21 mm}
+### Problems 1 : Hoare partition correctness
+***
+The version of PARTITION given in this chapter is not the original partitioning algorithm. Here is the original partition algorithm, which is due to T. Hoare:
+
+ HOARE-PARTITION(A, p, r):
+ x <- A[p]
+ i <- p - 1
+ j <- r + 1
+ while TRUE:
+ do repeat j <- j - 1
+ until A[j] <= x
+ repeat i <- i + 1
+ until A[i] >= x
+ if i < j:
+ then exchange A[i] <-> A[j]
+ else return j
+
+
+**a.** Demonstrate the operation of HOARE-PARTITION on the array A = [13, 19, 9, 5, 12, 8, 7, 4, 11, 2, 6, 21], showing the values of the array and auxiliary values after each iteration of the for loop in lines 4-11.
+
+The next three questions ask you to give a careful argument that the procedure HOARE- PARTITION is correct. Prove the following:
+
+**b.** The indices i and j are such that we never access an element of A outside the subarray A[p...r].
+
+**c.** When HOARE-PARTITION terminates, it returns a value j such that p ≤ j < r.
+
+**d.** Every element of A[p...j] is less than or equal to every element of A[j+1...r] when
+HOARE-PARTITION terminates.
+
+The PARTITION procedure in Section 7.1 separates the pivot value (originally in A[r]) from the two partitions it forms. The HOARE-PARTITION procedure, on the other hand, always places the pivot value (originally in A[p]) into one of the two partitions A[p...j] and A[j + 1...r]. Since p ≤ j < r, this split is always nontrivial.
+
+**e.** Rewrite the QUICKSORT procedure to use HOARE-PARTITION.
+
+
+### `Answer`
+**a.**
+
+
+
+
+**b.**
+
+这是肯定的,因为i,j是往中间靠拢的.
+
+**c.**
+j至少会减2次. 若第一次进入while,j只减了1次,那么会做一次swap.然后继续进入while.
+
+**d.**
+
+很显然,小于x的放前面了,大于等于x的在后面.
+
+**e.**
+
+[implementation](./exercise_code/hoare.py)
+
+
+### Problems 2 : Alternative quicksort analysis
+***
+An alternative analysis of the running time of randomized quicksort focuses on the expected running time of each individual recursive call to QUICKSORT, rather than on the number of comparisons performed.
+
+**a.** Argue that, given an array of size n, the probability that any particular element is chosen as the pivot is 1/n. Use this to define indicator random variables Xi = I{ith smallest element is chosen as the pivot}. What is E [Xi]?
+
+**b.** Let T (n) be a random variable denoting the running time of quicksort on an array of size n. Argue that
+] = E\\bigg[\\sum_{q=1}^nX_q\(T\(q-1\) + T\(n-q\) + \\Theta\(n\)\)\\bigg] )
+
+**c.**
+Show that equation (7.5) simplifies to
+
+] = \\frac{2}{n}\\sum_{q=2}^{n-1}E[T\(q\)] + \\Theta\(n\) )
+
+**d.**
+Show that
+
+
+
+**e.**
+
+Using the bound from equation (7.7), show that the recurrence in equation (7.6) has
+the solution E [T (n)] = Θ(n lg n). (Hint: Show, by substitution, that E[T (n)] ≤ an log n - bn for some positive constants a and b.)
+
+
+### `Answer`
+**a.**
+
+E[Xi]=1/n.
+
+
+**b.**
+
+这个算式的本质和之前分析快速排序的算式是一样的.
+
+**c.**
+
+就是简单的化简
+
+**d.**
+
+ + \\sum_{k=n/2 + 1}^{n}k\\lg{n} \\\\ ~ \\hspace{22 mm}
+ = \\lg\(n/2\)\\sum_{k=2}^{n/2}k + \\lg{n}\\sum_{k=n/2 + 1}^{n}k \\\\ ~ \\hspace{22 mm}
+ = \(\\lg{n} - \\lg{2}\)\\bigg\(\\frac{\(n/2\)\(n/2 + 1\)}{2}\\bigg\) + \\lg{n}\\bigg\(\\frac{n\(n+1\)}{2} - \\frac{\(n/2\)\(n/2 + 1\)}{2}\\bigg\) \\\\ ~ \\hspace{22 mm}
+ = \\lg{n}\\frac{n\(n+1\)}{2} - \\frac{\(n/2\)\(n/2 + 1\)}{2} \\\\ ~ \\hspace{22 mm}
+ = \\frac{1}{2}\\lg{n}\(n^2 + 2n + 1\) - \\frac{1}{8}\(n^2 + 2n + 1/8\) \\\\ ~ \\hspace{22 mm}
+ = \\frac{1}{2}n^2\\lg{n} - \\frac{1}{8}n^2 - \\frac{8n\\lg{n} + 4\\lg{n} - 2n - 1/8}{8} \\\\ ~ \\hspace{22 mm}
+ \\le \\frac{1}{2}n^2\\lg{n} - \\frac{1}{8}n^2)
+
+**e.**
+
+我们猜想 E[T(n)] ≤ anlgn
+
+] = \\frac{2}{n}\\sum_{q=2}^{n-1}E[T\(q\)] + \\Theta\(n\) \\\\ ~ \\hspace{21 mm}
+ \\le \\frac{2}{n}\\sum_{q=2}^{n-1}an\\lg{n} + \\Theta\(n\) \\\\ ~ \\hspace{21 mm}
+ \\le \\frac{2a}{n}\\bigg\(\\frac{1}{2}n^2\\lg{n} - \\frac{1}{8}n^2\\bigg\)
+ + \\Theta\(n\) \\\\\ ~ \\hspace{21 mm}
+ = an\\lg{n} - \\frac{a}{4}n + \\Theta\(n\) \\\\ ~ \\hspace{21 mm}
\\le an\\lg{n} )
-
-
-### Problems 3 : Stooge sort
-***
-Professors Howard, Fine, and Howard have proposed the following "elegant" sorting algorithm:
-
- STOOGE-SORT(A, i, j):
- if A[i] > A[j]
- then exchange A[i] <-> A[j]
- if i + 1 >= j
- then return
- k <- ⌊(j-i+1)/3⌋
- STOOGE-SORT(A, i, j-k)
- STOOGE-SORT(A, i+k, j)
- STOOGE-SORT(A, i, j-k)
-
-a. Argue that, if n = length[A], then STOOGE-SORT(A, 1, length[A]) correctly sorts the input array A[1...n].
-
b. Give a recurrence for the worst-case running time of STOOGE-SORT and a tight asymptotic (Θ-notation) bound on the worst-case running time.
-
c. Compare the worst-case running time of STOOGE-SORT with that of insertion sort, merge sort, heapsort, and quicksort. Do the professors deserve tenure?
-### `Answer`
-
-**a.**
-
-分三次进行排序,先将前2/3排好,再排后2/3,那么这时候最大的1/3已经在后面了。最后再对前面的2/3进行排序。是正确的。
-
-**b.**
-
-T(n) = 3T(2n/3) + O(1)
-
-根据主定理最坏运行时间是)
-
-**c.**
-
-当然不会!
-
-
-### Problems 4 : Stack depth for quicksort
-***
-The QUICKSORT algorithm of Section 7.1 contains two recursive calls to itself. After the call to PARTITION, the left subarray is recursively sorted and then the right subarray is recursively sorted. The second recursive call in QUICKSORT is not really necessary; it can be avoided by using an iterative control structure. This technique, called tail recursion, is provided automatically by good compilers. Consider the following version of quicksort, which simulates tail recursion.
-
- QUICKSORT'(A, p, r):
- while p < r:
- do Partition and sort left subarray.
- q <- PARTITION(A, p, r)
- QUICKSORT'(A, p, q-1)
- p <- q + 1
-
-**a.** Argue that QUICKSORT'(A, 1, length[A]) correctly sorts the array A.
-
-Compilers usually execute recursive procedures by using a stack that contains pertinent information, including the parameter values, for each recursive call. The information for the most recent call is at the top of the stack, and the information for the initial call is at the bottom. When a procedure is invoked, its information is pushed onto the stack; when it terminates, its information is popped. Since we assume that array parameters are represented by pointers, the information for each procedure call on the stack requires O(1) stack space. The stack depth is the maximum amount of stack space used at any time during a computation.
-
-**b.** Describe a scenario in which the stack depth of QUICKSORT' is Θ(n) on an n-element input array.
-
-**c.**
-Modify the code for QUICKSORT' so that the worst-case stack depth is Θ(lg n). Maintain the O(n lg n) expected running time of the algorithm.
-
-### `Answer`
-**a.**
-
-这个递推式总是先把左边的排好序,再排右边的. 顺序上和以前的版本是一样的.
-
-**b.**
-
-当运气比较差的时候,每次PARTITION都return r,会产生O(n)的堆栈深度.
-
-**c.**
-
-key idea : 先选range小的那一边迭代
-
-[implementation](./exercise_code/tailrecursive.py)
-
-
+
+
+### Problems 3 : Stooge sort
+***
+Professors Howard, Fine, and Howard have proposed the following "elegant" sorting algorithm:
+
+ STOOGE-SORT(A, i, j):
+ if A[i] > A[j]
+ then exchange A[i] <-> A[j]
+ if i + 1 >= j
+ then return
+ k <- ⌊(j-i+1)/3⌋
+ STOOGE-SORT(A, i, j-k)
+ STOOGE-SORT(A, i+k, j)
+ STOOGE-SORT(A, i, j-k)
+
+a. Argue that, if n = length[A], then STOOGE-SORT(A, 1, length[A]) correctly sorts the input array A[1...n].
+
+b. Give a recurrence for the worst-case running time of STOOGE-SORT and a tight asymptotic (Θ-notation) bound on the worst-case running time.
+
+c. Compare the worst-case running time of STOOGE-SORT with that of insertion sort, merge sort, heapsort, and quicksort. Do the professors deserve tenure?
+
+### `Answer`
+
+**a.**
+
+分三次进行排序,先将前2/3排好,再排后2/3,那么这时候最大的1/3已经在后面了。最后再对前面的2/3进行排序。是正确的。
+
+**b.**
+
+T(n) = 3T(2n/3) + O(1)
+
+根据主定理最坏运行时间是)
+
+**c.**
+
+当然不会!
+
+
+### Problems 4 : Stack depth for quicksort
+***
+The QUICKSORT algorithm of Section 7.1 contains two recursive calls to itself. After the call to PARTITION, the left subarray is recursively sorted and then the right subarray is recursively sorted. The second recursive call in QUICKSORT is not really necessary; it can be avoided by using an iterative control structure. This technique, called tail recursion, is provided automatically by good compilers. Consider the following version of quicksort, which simulates tail recursion.
+
+ QUICKSORT'(A, p, r):
+ while p < r:
+ do Partition and sort left subarray.
+ q <- PARTITION(A, p, r)
+ QUICKSORT'(A, p, q-1)
+ p <- q + 1
+
+**a.** Argue that QUICKSORT'(A, 1, length[A]) correctly sorts the array A.
+
+Compilers usually execute recursive procedures by using a stack that contains pertinent information, including the parameter values, for each recursive call. The information for the most recent call is at the top of the stack, and the information for the initial call is at the bottom. When a procedure is invoked, its information is pushed onto the stack; when it terminates, its information is popped. Since we assume that array parameters are represented by pointers, the information for each procedure call on the stack requires O(1) stack space. The stack depth is the maximum amount of stack space used at any time during a computation.
+
+**b.** Describe a scenario in which the stack depth of QUICKSORT' is Θ(n) on an n-element input array.
+
+**c.**
+Modify the code for QUICKSORT' so that the worst-case stack depth is Θ(lg n). Maintain the O(n lg n) expected running time of the algorithm.
+
+### `Answer`
+**a.**
+
+这个递推式总是先把左边的排好序,再排右边的. 顺序上和以前的版本是一样的.
+
+**b.**
+
+当运气比较差的时候,每次PARTITION都return r,会产生O(n)的堆栈深度.
+
+**c.**
+
+key idea : 先选range小的那一边迭代
+
+[implementation](./exercise_code/tailrecursive.py)
+
+
### Problems 5 : Median-of-3 partition
-***
-One way to improve the RANDOMIZED-QUICKSORT procedure is to partition around a pivot that is chosen more carefully than by picking a random element from the subarray. One common approach is the **median-of-3** method: choose the pivot as the median (middle element) of a set of 3 elements randomly selected from the subarray. (See Exercise 7.4-6.) For this problem, let us assume that the elements in the input array A[1...n] are distinct and that n ≥ 3. We denote the sorted output array by A'[1...n]. Using the median-of-3 method to choose the pivot element x, define pi = Pr{x = A'[i]}.
-
-**a.** Give an exact formula for pi as a function of n and i for i=2,3,...,n-1.(Note that p1 = pn = 0.)
-
-**b.** By what amount have we increased the likelihood of choosing the pivot as x = A'[⌊(n
+ 1/2⌋], the median of A[1...n], compared to the ordinary implementation? Assume that n → ∞, and give the limiting ratio of these probabilities.
-
**c.** If we define a "good" split to mean choosing the pivot as x = A'[i], where n/ ≤ i ≤ 2n/3, by what amount have we increased the likelihood of getting a good split compared to the ordinary implementation? (Hint: Approximate the sum by an integral.)
-
**d.** Argue that in the Ω(n lg n) running time of quicksort, the median-of-3 method affects only the constant factor.
-
-### `Answer`
-**a.**
-
-\(n-i\)}{n\(n-1\)\(n-2\)} )
-
-**b.**
-
-\(n-i\)}{n\(n-1\)\(n-2\)}/\\frac{1}{n}
- = \\lim_{n \\to \\infty}\\frac{6n\(n/2 - 1\)\(n/2\)}{\(n-1\)\(n-2\)} = 1.5 )
-
-**c.**
-
-\(n-i\)}{n\(n-1\)\(n-2\)} =
-\\lim_{n \\to \\infty}\\frac{6}{n\(n-1\)\(n-2\)}\\sum_{i=n/3}^{2n/3}\(i-1\)\(n-i\) =
-\\frac{13}{27})
-
-**d.**
-这种方法无法保证能取最优划分点,依然是概率问题,而且比普通的提升并没有很大.
-
-
-### Problems 6 : Fuzzy sorting of intervals
-Consider a sorting problem in which the numbers are not known exactly. Instead, for each number, we know an interval on the real line to which it belongs. That is, we are given n closed intervals of the form [ai, bi], where ai ≤ bi. The goal is to **fuzzy-sort** these intervals, i.e., produce a permutation [i1, i2,..., in] of the intervals such that there exist
-, satisfying c1 ≤c2 ≤···≤cn.
**a.** Design an algorithm for fuzzy-sorting n intervals. Your algorithm should have the general structure of an algorithm that quicksorts the left endpoints (the ai 's), but it should take advantage of overlapping intervals to improve the running time. (As the intervals overlap more and more, the problem of fuzzy-sorting the intervals gets easier and easier. Your algorithm should take advantage of such overlapping, to the extent that it exists.)
-
### `Answer`
-
[implementation](./exercise_code/fuzzy_sort.py)
-
类似于quicksort,只是当重叠区域越多,pivot内的区别就越多~~
-
-### Problems 2 (3rd Edition): Quicksort with equal element values
-The analysis of the expected running time of randomized quicksort in Section 7.4.2 assumes that all element values are distinct. In this problem, we examine what happens when they are not.
-
-**a.** Suppose that all element values are equal. What would be randomized quick-sort's running time in this case?
-If the algorithm uses Lumuto Partition, then running time is O(n^2)
-If the algorithm uses modified Hoare partition that stops scanning at equal case, then the worst case can be avoided.
-
-**b.** Write a 3-way partition algorithm
-**c.** Implement randomized-3-way-partition
-
-[implementation](./exercise_code/quickSortWithEqualElements.cpp)
-
-**d.** Using 3-way-partition-qsort, adjust the analysis in Section 7.4.2 to avoid the assumpton that all elements are equal.
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+***
+One way to improve the RANDOMIZED-QUICKSORT procedure is to partition around a pivot that is chosen more carefully than by picking a random element from the subarray. One common approach is the **median-of-3** method: choose the pivot as the median (middle element) of a set of 3 elements randomly selected from the subarray. (See Exercise 7.4-6.) For this problem, let us assume that the elements in the input array A[1...n] are distinct and that n ≥ 3. We denote the sorted output array by A'[1...n]. Using the median-of-3 method to choose the pivot element x, define pi = Pr{x = A'[i]}.
+
+**a.** Give an exact formula for pi as a function of n and i for i=2,3,...,n-1.(Note that p1 = pn = 0.)
+
+**b.** By what amount have we increased the likelihood of choosing the pivot as x = A'[⌊(n
++ 1/2⌋], the median of A[1...n], compared to the ordinary implementation? Assume that n → ∞, and give the limiting ratio of these probabilities.
+
+**c.** If we define a "good" split to mean choosing the pivot as x = A'[i], where n/ ≤ i ≤ 2n/3, by what amount have we increased the likelihood of getting a good split compared to the ordinary implementation? (Hint: Approximate the sum by an integral.)
+
+**d.** Argue that in the Ω(n lg n) running time of quicksort, the median-of-3 method affects only the constant factor.
+
+### `Answer`
+**a.**
+
+\(n-i\)}{n\(n-1\)\(n-2\)} )
+
+**b.**
+
+\(n-i\)}{n\(n-1\)\(n-2\)}/\\frac{1}{n}
+ = \\lim_{n \\to \\infty}\\frac{6n\(n/2 - 1\)\(n/2\)}{\(n-1\)\(n-2\)} = 1.5 )
+
+**c.**
+
+\(n-i\)}{n\(n-1\)\(n-2\)} =
+\\lim_{n \\to \\infty}\\frac{6}{n\(n-1\)\(n-2\)}\\sum_{i=n/3}^{2n/3}\(i-1\)\(n-i\) =
+\\frac{13}{27})
+
+**d.**
+这种方法无法保证能取最优划分点,依然是概率问题,而且比普通的提升并没有很大.
+
+
+### Problems 6 : Fuzzy sorting of intervals
+Consider a sorting problem in which the numbers are not known exactly. Instead, for each number, we know an interval on the real line to which it belongs. That is, we are given n closed intervals of the form [ai, bi], where ai ≤ bi. The goal is to **fuzzy-sort** these intervals, i.e., produce a permutation [i1, i2,..., in] of the intervals such that there exist
+, satisfying c1 ≤c2 ≤···≤cn.
+
+
+**a.** Design an algorithm for fuzzy-sorting n intervals. Your algorithm should have the general structure of an algorithm that quicksorts the left endpoints (the ai 's), but it should take advantage of overlapping intervals to improve the running time. (As the intervals overlap more and more, the problem of fuzzy-sorting the intervals gets easier and easier. Your algorithm should take advantage of such overlapping, to the extent that it exists.)
+
+
+### `Answer`
+
+[implementation](./exercise_code/fuzzy_sort.py)
+
+
+类似于quicksort,只是当重叠区域越多,pivot内的区别就越多~~
+
+### Problems 2 (3rd Edition): Quicksort with equal element values
+The analysis of the expected running time of randomized quicksort in Section 7.4.2 assumes that all element values are distinct. In this problem, we examine what happens when they are not.
+
+**a.** Suppose that all element values are equal. What would be randomized quick-sort's running time in this case?
+If the algorithm uses Lumuto Partition, then running time is O(n^2)
+If the algorithm uses modified Hoare partition that stops scanning at equal case, then the worst case can be avoided.
+
+**b.** Write a 3-way partition algorithm
+**c.** Implement randomized-3-way-partition
+
+[implementation](./exercise_code/quickSortWithEqualElements.cpp)
+
+**d.** Using 3-way-partition-qsort, adjust the analysis in Section 7.4.2 to avoid the assumpton that all elements are equal.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C08-Sorting-in-Linear-Time/8.2.md b/C08-Sorting-in-Linear-Time/8.2.md
index 9d00b42b..99b1fe87 100644
--- a/C08-Sorting-in-Linear-Time/8.2.md
+++ b/C08-Sorting-in-Linear-Time/8.2.md
@@ -1,37 +1,38 @@
-### Exercises 8.2-1
-***
+### Exercises 8.2-1
+***
Using Figure 8.2 as a model, illustrate the operation of COUNTING-SORT on the array A = [6, 0, 2, 0, 1, 3, 4, 6, 1, 3, 2].
-### `Answer`
-
-
-
-### Exercises 8.2-2
-***
+### `Answer`
+
+
+
+### Exercises 8.2-2
+***
Prove that COUNTING-SORT is stable.
-
-### `Answer`
-COUNTING-SORT最后是从后面往前面扫,并且把遇到的每一个item放在同大小(key)的最后面的位子.所以不改变相对顺序.
-
-### Exercises 8.2-3
-***
-Suppose that the for loop header in line 9 of the COUNTING-SORT procedure is rewritten
-
-as 9 for j ← 1 to length[A]
-
Show that the algorithm still works properly. Is the modified algorithm stable?
-
-### `Answer`
-可以正常工作,只是不stable.
-
-### Exercises 8.2-4
-***
+
+### `Answer`
+COUNTING-SORT最后是从后面往前面扫,并且把遇到的每一个item放在同大小(key)的最后面的位子.所以不改变相对顺序.
+
+### Exercises 8.2-3
+***
+Suppose that the for loop header in line 9 of the COUNTING-SORT procedure is rewritten
+
+as 9 for j ← 1 to length[A]
+
+Show that the algorithm still works properly. Is the modified algorithm stable?
+
+### `Answer`
+可以正常工作,只是不stable.
+
+### Exercises 8.2-4
+***
Describe an algorithm that, given n integers in the range 0 to k, preprocesses its input and then answers any query about how many of the n integers fall into a range [a...b] in O(1) time. Your algorithm should use Θ(n + k) preprocessing time.
-
-### `Answer`
-利用数组C,[a,b]间的个数是C[b]-C[a-1].(C[-1] = 0)
-
-[implementation](./exercise_code/integerQuery.cpp)
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+利用数组C,[a,b]间的个数是C[b]-C[a-1].(C[-1] = 0)
+
+[implementation](./exercise_code/integerQuery.cpp)
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C08-Sorting-in-Linear-Time/problem.md b/C08-Sorting-in-Linear-Time/problem.md
index 4266f821..7c7e76e0 100644
--- a/C08-Sorting-in-Linear-Time/problem.md
+++ b/C08-Sorting-in-Linear-Time/problem.md
@@ -134,8 +134,8 @@ For the nubers, we can do this:
- Group the nunbers by number of digits and order groups.
- RADIX sort each group.
-We let the `Gi` be the group of numbers with i digits and ci = |Gi|, thus: we can multiply the `n*Ci` with `i`, then sum from `i = 1` to `i = highest digit`. We can get the
-
+We let the `Gi` be the group of numbers with i digits and ci = |Gi|, thus: we can multiply the `n*Ci` with `i`, then sum from `i = 1` to `i = highest digit`. We can get the
+
= \\sum_{i = 1}nc_i \\cdot i = n )
@@ -146,14 +146,14 @@ reverse所有的字符串,用RADIX-SORT.当当遍历到某一个字符串超
假设我们要排序字符串d,c,b,bcd,bc,bd,bdc.过程如下:
-0 | 1 | 2 | 3 | 4 | result | reverse
-:----: | :----: | :----: | :----: | :----: | :----: | :----:
-d | **b** | b | | | b | b
-c | dc**b** | d**c**b | cb | | cb | bc
-b | c**b** | **c**b | **d**cb | dcb | dcb | bcd
-dcb | d**b** | **d**b | db | | db | bd
-cb | cd**b** | c**d**b | **c**db | cdb |cdb | bdc
-db | **c** | c | | | c | c
+0 | 1 | 2 | 3 | 4 | result | reverse
+:----: | :----: | :----: | :----: | :----: | :----: | :----:
+d | **b** | b | | | b | b
+c | dc**b** | d**c**b | cb | | cb | bc
+b | c**b** | **c**b | **d**cb | dcb | dcb | bcd
+dcb | d**b** | **d**b | db | | db | bd
+cb | cd**b** | c**d**b | **c**db | cdb |cdb | bdc
+db | **c** | c | | | c | c
cdb | **d** | d | | | d | d
### Problems 4 : Water jugs
diff --git a/C09-Medians-and-Order-Statistics/9.3.md b/C09-Medians-and-Order-Statistics/9.3.md
index 8d79521c..383fd02e 100644
--- a/C09-Medians-and-Order-Statistics/9.3.md
+++ b/C09-Medians-and-Order-Statistics/9.3.md
@@ -1,111 +1,116 @@
-### Exercises 9.3-1
-***
-In the algorithm SELECT, the input elements are divided into groups of 5. Will the algorithm work in linear time if they are divided into groups of 7? Argue that SELECT does not run in linear time if groups of 3 are used.
-### `Answer`
-Assuming each group has k elements.
-
-The number that less(or greater) then median of median is at least n/4-k,In the worst case, next call to SELECT will recursive call 3n/4+k elements.
-
-so
-
-
-Assuming for all n,T(n) <= cn
-
-
-
-So according to 1/k+3/4 <= 1 wo get k >= 4
-
-### Exercises 9.3-2
-***
-Analyze SELECT to show that if n ≥ 140, then at least ⌈n/4⌉ elements are greater than the median-of-medians x and at least ⌈n/4⌉ elements are less than x.
-
-### `Answer`
-
-
-### Exercises 9.3-3
-***
Show how quicksort can be made to run in O() time in the worst case.
-
-### `Answer`
-比较直观,我们先利用线性时间去找到中位数,再用这个中位数去做partition.
-
-It is obvious, we first use O(n) time to find median, then use median to do partition.
-
-
-### Exercises 9.3-4
-***
-Suppose that an algorithm uses only comparisons to find the ith smallest element in a set of n elements. Show that it can also find the i - 1 smaller elements and the n - i larger elements without performing any additional comparisons.
-
+### Exercises 9.3-1
+***
+In the algorithm SELECT, the input elements are divided into groups of 5. Will the algorithm work in linear time if they are divided into groups of 7? Argue that SELECT does not run in linear time if groups of 3 are used.
+### `Answer`
+Assuming each group has k elements.
+
+The number that less(or greater) then median of median is at least n/4-k,In the worst case, next call to SELECT will recursive call 3n/4+k elements.
+
+so
+
+
+Assuming for all n,T(n) <= cn
+
+
+
+So according to 1/k+3/4 <= 1 wo get k >= 4
+
+### Exercises 9.3-2
+***
+Analyze SELECT to show that if n ≥ 140, then at least ⌈n/4⌉ elements are greater than the median-of-medians x and at least ⌈n/4⌉ elements are less than x.
+
+### `Answer`
+
+
+### Exercises 9.3-3
+***
+Show how quicksort can be made to run in O() time in the worst case.
+
### `Answer`
-只用比较来确定的话,就跟这讲的方法是一样的. 我们既然找到了第i小元素,那么比i大和比i小的都已经被我们分类分好了.
-
-We can find ith element, then the number greater than i and the number less than i have been already partitioned.
-
-### Exercises 9.3-5
-***
-Suppose that you have a "black-box" worst-case linear-time median subroutine. Give a simple, linear-time algorithm that solves the selection problem for an arbitrary order statistic.
-
+比较直观,我们先利用线性时间去找到中位数,再用这个中位数去做partition.
+
+It is obvious, we first use O(n) time to find median, then use median to do partition.
+
+
+### Exercises 9.3-4
+***
+Suppose that an algorithm uses only comparisons to find the ith smallest element in a set of n elements. Show that it can also find the i - 1 smaller elements and the n - i larger elements without performing any additional comparisons.
+
### `Answer`
-[code](./exercise_code/black-box.py) tells everything. Thanks original code [here](http://clrs.skanev.com/09/03/05.html).
-
-Find the median, and recursve half of the elements.
-
-
-### Exercises 9.3-6
-***
-The *k*th **quantiles** of an n-element set are the *k* - 1 order statistics that divide the sorted set into *k* equal-sized sets (to within 1). Give an O(n lg k)-time algorithm to list the *k*th quantiles of a set.
+只用比较来确定的话,就跟这讲的方法是一样的. 我们既然找到了第i小元素,那么比i大和比i小的都已经被我们分类分好了.
+
+We can find ith element, then the number greater than i and the number less than i have been already partitioned.
+
+### Exercises 9.3-5
+***
+Suppose that you have a "black-box" worst-case linear-time median subroutine. Give a simple, linear-time algorithm that solves the selection problem for an arbitrary order statistic.
+
### `Answer`
-[code](./exercise_code/k-quantile.py) tells everything. Thanks original code [here](http://clrs.skanev.com/09/03/06.html).
-
-- 如果k是偶数,那么取中间一个,再对左右两边进行递归.
-- 如果k是奇数,取最接近中间的两个数,再对左右两边进行递归.
-
-- If k is even, then choose the middle one, recursive call left part and right part.
-- If k is odd,choose two index numbers most close to median,then recursive call the left part and right part.
-
-
-
-### Exercises 9.3-7
-***
-Describe an O(n)-time algorithm that, given a set S of n distinct numbers and a positive
integer k ≤ n, determines the k numbers in S that are closest to the median of S.
-
### `Answer`
-[code](./exercise_code/k-close2median.py)
-
-1. 计算出中位数median
-2. 将所有数减去median,再取绝对值
-3. 用SELECT计算出第k小数字y
-4. 遍历数组,取出所有绝对值小于等于y的
-
-代码的局限性在于只能接收绝对值不含有相同元素的.
-
-1. Find the median
-2. For all the numbers, minus median then get the absolute value
-3. use SELECT to find the kth smallest number y
-4. Iterate the array choose all the absolute value that less than y
-
-### Exercises 9.3-8
-***
-Let [1 .. n] and Y [1 .. n] be two arrays, each containing n numbers already in sorted order. Give an O(lg n)-time algorithm to find the median of all 2n elements in arrays X and Y.
-### `Answer`
-Divide and conquer
-
+[code](./exercise_code/black-box.py) tells everything. Thanks original code [here](http://clrs.skanev.com/09/03/05.html).
+
+Find the median, and recursve half of the elements.
+
+
+### Exercises 9.3-6
+***
+The *k*th **quantiles** of an n-element set are the *k* - 1 order statistics that divide the sorted set into *k* equal-sized sets (to within 1). Give an O(n lg k)-time algorithm to list the *k*th quantiles of a set.
+### `Answer`
+[code](./exercise_code/k-quantile.py) tells everything. Thanks original code [here](http://clrs.skanev.com/09/03/06.html).
+
+- 如果k是偶数,那么取中间一个,再对左右两边进行递归.
+- 如果k是奇数,取最接近中间的两个数,再对左右两边进行递归.
+
+- If k is even, then choose the middle one, recursive call left part and right part.
+- If k is odd,choose two index numbers most close to median,then recursive call the left part and right part.
+
+
+
+### Exercises 9.3-7
+***
+Describe an O(n)-time algorithm that, given a set S of n distinct numbers and a positive
+integer k ≤ n, determines the k numbers in S that are closest to the median of S.
+
+### `Answer`
+[code](./exercise_code/k-close2median.py)
+
+1. 计算出中位数median
+2. 将所有数减去median,再取绝对值
+3. 用SELECT计算出第k小数字y
+4. 遍历数组,取出所有绝对值小于等于y的
+
+代码的局限性在于只能接收绝对值不含有相同元素的.
+
+1. Find the median
+2. For all the numbers, minus median then get the absolute value
+3. use SELECT to find the kth smallest number y
+4. Iterate the array choose all the absolute value that less than y
+
+### Exercises 9.3-8
+***
+Let [1 .. n] and Y [1 .. n] be two arrays, each containing n numbers already in sorted order. Give an O(lg n)-time algorithm to find the median of all 2n elements in arrays X and Y.
+### `Answer`
+Divide and conquer
+
[code](https://github.com/gzc/leetcode/blob/master/001-010/Median%20of%20Two%20Sorted%20Arrays.cpp)
-
### Exercises 9.3-9
+
+
+### Exercises 9.3-9
+***
+Professor Olay is consulting for an oil company, which is planning a large pipeline running east to west through an oil field of n wells. From each well, a spur pipeline is to be connected directly to the main pipeline along a shortest path (either north or south), as shown in [Figure 9.2](#oil). Given x- and y-coordinates of the wells, how should the professor pick the optimal location of the main pipeline (the one that minimizes the total length of the spurs)? Show that the optimal location can be determined in linear time.
+
+
+
+Figure 9.2: Professor Olay needs to determine the position of the east-west oil pipeline that minimizes the total length of the north-south spurs.
+### `Answer`
+
+Find the median of y.
+
+
***
-Professor Olay is consulting for an oil company, which is planning a large pipeline running east to west through an oil field of n wells. From each well, a spur pipeline is to be connected directly to the main pipeline along a shortest path (either north or south), as shown in [Figure 9.2](#oil). Given x- and y-coordinates of the wells, how should the professor pick the optimal location of the main pipeline (the one that minimizes the total length of the spurs)? Show that the optimal location can be determined in linear time.
-
-
-
-Figure 9.2: Professor Olay needs to determine the position of the east-west oil pipeline that minimizes the total length of the north-south spurs.
-###`Answer`
-
-Find the median of y.
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
-
-
-
-
-
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
+
+
+
+
+
diff --git a/C09-Medians-and-Order-Statistics/problem.md b/C09-Medians-and-Order-Statistics/problem.md
index 4c3d0e47..e7f4cec5 100644
--- a/C09-Medians-and-Order-Statistics/problem.md
+++ b/C09-Medians-and-Order-Statistics/problem.md
@@ -1,93 +1,103 @@
-### Problems 1 : Largest i numbers in sorted order
-***
-
Given a set of *n* numbers, we wish to find the *i* largest in sorted order using a comparison- based algorithm. Find the algorithm that implements each of the following methods with the best asymptotic worst-case running time, and analyze the running times of the algorithms in terms of *n* and *i*.
-
a. Sort the numbers, and list the *i* largest.
b. Build a max-priority queue from the numbers, and call EXTRACT-MAX *i* times.
c. Use an order-statistic algorithm to find the *i*th largest number, partition around that number, and sort the *i* largest numbers.
-
-### `Answer`
-a和b的代码在这里.[code](./problems/i-largest.py).
-如果先排序的话,就需要O(nlgn)+O(i)的时间.
-用堆的话,需要O(n)+O(ilogn)的时间.
-
-对于c,[code](./problems/i-largest.cpp)
-利用顺序统计量的话,找到这个值需要O(n)的时间,然后需要对i个数排序需要O(ilogi)时间.
-
-
-### Problems 2 : Weighted median
-***
-For n distinct elements  with positive weights  such that
-
-,**the weighted (lower)** median is the element 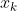 satisfying
-
-
-
-and
-
-
-
-a. Argue that the median of x1, x2, ..., xn is the weighted median of the xi with weights wi = 1/n for i = 1,2, ..., n.
-
b. Show how to compute the weighted median of n elements in O(n lg n) worst-case time using sorting.
-
-c. Show how to compute the weighted median in Θ(n) worst-case time using a linear- time median algorithm such as SELECT from Section 9.3.
-
-The **post-office location problem** is defined as follows. We are given *n* points p1, p2, ..., pn with associated weights w1, w2, ..., wn. We wish to find a point p (not necessarily one of the input points) that minimizes the sum
-
-
-)
-where *d*(a, b) is the distance between points a and b.
d. Argue that the weighted median is a best solution for the 1-dimensional post-office location problem, in which points are simply real numbers and the distance between points a and b is *d*(a, b) = |a - b|.
-
e. Find the best solution for the 2-dimensional post-office location problem, in which the points are (x, y) coordinate pairs and the distance between points a = (x1, y1) and b = (x2, y2) is the **Manhattan distance** given by d(a, b) = |x1 - x2| + |y1 - y2|.
-
-
-### `Answer`
-a. 好显然TAT.
-
-b. 先排序,然后开始遍历,直到加上某一个数字的权重 ≥ 1/2.
-
-c. [code](./problems/weighted_median.py)
-
-d. 假设p是带权中位数,只要偏离p,距离就会越来越大
-
-e. 分别找x和y方向的带权中位数,因为用的是曼哈顿距离,x和y是独立的,所以可以分开对待.
-
-
-### Problems 3 : Small order statistics
-***
-The worst-case number T(n) of comparisons used by SELECT to select the ith order statistic from n numbers was shown to satisfy T(n) = Θ(n), but the constant hidden by the Θ-notation is rather large. When i is small relative to n, we can implement a different procedure that uses SELECT as a subroutine but makes fewer comparisons in the worst case.
-
-a. Describe an algorithm that uses Ui(n) comparisons to find the ith smallest of n elements, where
-(Hint: Begin with
-
-disjoint pairwise comparisons, and recurse on the set containing the smaller element from each pair.)
-
-b. Show that, if i < n/2, then Ui(n) = n + O(T (2i) lg(n/i)).
-
-c. Show that if i is a constant less than n/2, then Ui(n) = n + O(lg n).
-
d. Show that if *i* = n/k for k≥2,then Ui(n) = n+O(T(2n/k)lgk).
-
-### `Answer`
-a.
- 1. 如果i ≥ n/2,直接调用SELECT(n, i)
- 2. 如果i < n/2,那么就两个两个比较,生成了小的一组,同时也记录大的一组(比如可以用map映射起来)
- 3. 对小的一组递归调用这个函数
- 4. 当调用回来时,能找到这小的一组的第i个数,这个数左边都是比它小的数字,再从map中找到这i个数字对应的数字,这样总共有2i个数字,再对这2i个数字调用SELECT.
- 很tricky的一点是为什么最后要调用T(2i),看下面这个数字[1,2,3,4],order-2是2,可是分组完后较小元素是[1,3],所以还要对另外i个数字进行比较.
-
-b.  = \\lfloor n/2 \\rfloor + U_i\(\\lceil n/2 \\rceil\) + T\(2i\) \\nonumber \\\\ ~
-\\hspace{16 mm} = \\lfloor n/2 \\rfloor + \\lceil n/2 \\rceil + O\(T\(2i\)\\lg\(\\lfloor n/2 \\rfloor / i\)\)+T\(2i\) \\\\ ~
-\\hspace{16 mm} = n + O\(T\(2i\)\\lg\(n / i\)\) + T\(2i\) \\\\ ~
-\\hspace{16 mm}= n + O\(T\(2i\)\\lg\(n / i\)\)
-)
-
-c.  = n + O\(T\(2i\)\\lg\(n / i\)\) \\\\ ~\\hspace{16 mm} = n + O\(O\(1\)\\lg\(n / i\)\) \\\\ ~
-\\hspace{16 mm} = n + O\(\\lg\(n\) - \\lg\(i\)\) \\\\ ~
-\\hspace{16 mm} = n + O\(\\lg\(n\) - O\(1\)\) \\\\ ~
-\\hspace{16 mm} = n + O\(\\lg\(n\)\) \\\\ ~
-)
-
-d.  = n + O\(T\(2i\)\\lg\(n / i\)\) \\\\ ~\\hspace{16 mm} = n + O\(T\(2n/k\)\\lg\(n / \(n/k\)\)\) \\\\ ~
-\\hspace{16 mm} = n + O\(T\(2n/k\)\\lg\(k\)\)
-)
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+### Problems 1 : Largest i numbers in sorted order
+***
+
+Given a set of *n* numbers, we wish to find the *i* largest in sorted order using a comparison- based algorithm. Find the algorithm that implements each of the following methods with the best asymptotic worst-case running time, and analyze the running times of the algorithms in terms of *n* and *i*.
+
+
+a. Sort the numbers, and list the *i* largest.
+b. Build a max-priority queue from the numbers, and call EXTRACT-MAX *i* times.
+c. Use an order-statistic algorithm to find the *i*th largest number, partition around that number, and sort the *i* largest numbers.
+
+### `Answer`
+a和b的代码在这里.[code](./problems/i-largest.py).
+如果先排序的话,就需要O(nlgn)+O(i)的时间.
+用堆的话,需要O(n)+O(ilogn)的时间.
+
+对于c,[code](./problems/i-largest.cpp)
+利用顺序统计量的话,找到这个值需要O(n)的时间,然后需要对i个数排序需要O(ilogi)时间.
+
+
+### Problems 2 : Weighted median
+***
+For n distinct elements  with positive weights  such that
+
+,**the weighted (lower)** median is the element 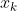 satisfying
+
+
+
+and
+
+
+
+a. Argue that the median of x1, x2, ..., xn is the weighted median of the xi with weights wi = 1/n for i = 1,2, ..., n.
+
+b. Show how to compute the weighted median of n elements in O(n lg n) worst-case time using sorting.
+
+c. Show how to compute the weighted median in Θ(n) worst-case time using a linear- time median algorithm such as SELECT from Section 9.3.
+
+The **post-office location problem** is defined as follows. We are given *n* points p1, p2, ..., pn with associated weights w1, w2, ..., wn. We wish to find a point p (not necessarily one of the input points) that minimizes the sum
+
+
+)
+where *d*(a, b) is the distance between points a and b.
+
+d. Argue that the weighted median is a best solution for the 1-dimensional post-office location problem, in which points are simply real numbers and the distance between points a and b is *d*(a, b) = |a - b|.
+
+e. Find the best solution for the 2-dimensional post-office location problem, in which the points are (x, y) coordinate pairs and the distance between points a = (x1, y1) and b = (x2, y2) is the **Manhattan distance** given by d(a, b) = |x1 - x2| + |y1 - y2|.
+
+
+### `Answer`
+a. 好显然TAT.
+
+b. 先排序,然后开始遍历,直到加上某一个数字的权重 ≥ 1/2.
+
+c. [code](./problems/weighted_median.py)
+
+d. 假设p是带权中位数,只要偏离p,距离就会越来越大
+
+e. 分别找x和y方向的带权中位数,因为用的是曼哈顿距离,x和y是独立的,所以可以分开对待.
+
+
+### Problems 3 : Small order statistics
+***
+The worst-case number T(n) of comparisons used by SELECT to select the ith order statistic from n numbers was shown to satisfy T(n) = Θ(n), but the constant hidden by the Θ-notation is rather large. When i is small relative to n, we can implement a different procedure that uses SELECT as a subroutine but makes fewer comparisons in the worst case.
+
+a. Describe an algorithm that uses Ui(n) comparisons to find the ith smallest of n elements, where
+(Hint: Begin with
+
+disjoint pairwise comparisons, and recurse on the set containing the smaller element from each pair.)
+
+b. Show that, if i < n/2, then Ui(n) = n + O(T (2i) lg(n/i)).
+
+c. Show that if i is a constant less than n/2, then Ui(n) = n + O(lg n).
+
+d. Show that if *i* = n/k for k≥2,then Ui(n) = n+O(T(2n/k)lgk).
+
+### `Answer`
+a.
+ 1. 如果i ≥ n/2,直接调用SELECT(n, i)
+ 2. 如果i < n/2,那么就两个两个比较,生成了小的一组,同时也记录大的一组(比如可以用map映射起来)
+ 3. 对小的一组递归调用这个函数
+ 4. 当调用回来时,能找到这小的一组的第i个数,这个数左边都是比它小的数字,再从map中找到这i个数字对应的数字,这样总共有2i个数字,再对这2i个数字调用SELECT.
+ 很tricky的一点是为什么最后要调用T(2i),看下面这个数字[1,2,3,4],order-2是2,可是分组完后较小元素是[1,3],所以还要对另外i个数字进行比较.
+
+b.  = \\lfloor n/2 \\rfloor + U_i\(\\lceil n/2 \\rceil\) + T\(2i\) \\nonumber \\\\ ~
+\\hspace{16 mm} = \\lfloor n/2 \\rfloor + \\lceil n/2 \\rceil + O\(T\(2i\)\\lg\(\\lfloor n/2 \\rfloor / i\)\)+T\(2i\) \\\\ ~
+\\hspace{16 mm} = n + O\(T\(2i\)\\lg\(n / i\)\) + T\(2i\) \\\\ ~
+\\hspace{16 mm}= n + O\(T\(2i\)\\lg\(n / i\)\)
+)
+
+c.  = n + O\(T\(2i\)\\lg\(n / i\)\) \\\\ ~\\hspace{16 mm} = n + O\(O\(1\)\\lg\(n / i\)\) \\\\ ~
+\\hspace{16 mm} = n + O\(\\lg\(n\) - \\lg\(i\)\) \\\\ ~
+\\hspace{16 mm} = n + O\(\\lg\(n\) - O\(1\)\) \\\\ ~
+\\hspace{16 mm} = n + O\(\\lg\(n\)\) \\\\ ~
+)
+
+d.  = n + O\(T\(2i\)\\lg\(n / i\)\) \\\\ ~\\hspace{16 mm} = n + O\(T\(2n/k\)\\lg\(n / \(n/k\)\)\) \\\\ ~
+\\hspace{16 mm} = n + O\(T\(2n/k\)\\lg\(k\)\)
+)
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C10-Elementary-Data-Structures/10.2.md b/C10-Elementary-Data-Structures/10.2.md
index c88eec17..59ee1cb0 100644
--- a/C10-Elementary-Data-Structures/10.2.md
+++ b/C10-Elementary-Data-Structures/10.2.md
@@ -1,72 +1,76 @@
-### Exercises 10.2-1
-***
-Can the dynamic-set operation INSERT be implemented on a singly linked list in O(1) time? How about DELETE?
-
-### `Answer`
-插入的话可以直接插入在开头,删除的话需要遍历.
-
-
-### Exercises 10.2-2
-***
-Implement a stack using a singly linked list L. The operations PUSH and POP should still
take O(1) time.
-
-### `Answer`
-PUSH插入到链表头,POP从链表头操作,都是O(1)的.
-
-### Exercises 10.2-3
-***
-Implement a queue by a singly linked list L. The operations ENQUEUE and DEQUEUE
should still take O(1) time.
-
-### `Answer`
-
-* ENQUEUE插入到链表尾
-* DEQUEUE从链表头取出
-
-### Exercises 10.2-4
-***
-As written, each loop iteration in the LIST-SEARC′ procedure requires two tests: one for x ≠
nil[L] and one for key[x] ≠ k. Show how to eliminate the test for x ≠ nil[L] in each iteration.
-
-### `Answer`
-
- LIST-SEARC′(L, k):
- key[nil[L]] = k
- x ← next[nil[L]]
- while(key[x] != k):
- x ← next[x]
- if x == nil[L]:
- return NULL
- return x
-
-
-### Exercises 10.2-5
-***
-Implement the dictionary operations INSERT, DELETE, and SEARCH using singly linked, circular lists. What are the running times of your procedures?
-
-### `Answer`
-[implementation](./exercise_code/dict.cpp)
-
-### Exercises 10.2-6
-***
+### Exercises 10.2-1
+***
+Can the dynamic-set operation INSERT be implemented on a singly linked list in O(1) time? How about DELETE?
+
+
+### `Answer`
+插入的话可以直接插入在开头,删除的话需要遍历.
+
+
+### Exercises 10.2-2
+***
+Implement a stack using a singly linked list L. The operations PUSH and POP should still
+take O(1) time.
+
+### `Answer`
+PUSH插入到链表头,POP从链表头操作,都是O(1)的.
+
+### Exercises 10.2-3
+***
+Implement a queue by a singly linked list L. The operations ENQUEUE and DEQUEUE
+should still take O(1) time.
+
+### `Answer`
+
+* ENQUEUE插入到链表尾
+* DEQUEUE从链表头取出
+
+### Exercises 10.2-4
+***
+As written, each loop iteration in the LIST-SEARC′ procedure requires two tests: one for x ≠
+nil[L] and one for key[x] ≠ k. Show how to eliminate the test for x ≠ nil[L] in each iteration.
+
+### `Answer`
+
+ LIST-SEARC′(L, k):
+ key[nil[L]] = k
+ x ← next[nil[L]]
+ while(key[x] != k):
+ x ← next[x]
+ if x == nil[L]:
+ return NULL
+ return x
+
+
+### Exercises 10.2-5
+***
+Implement the dictionary operations INSERT, DELETE, and SEARCH using singly linked, circular lists. What are the running times of your procedures?
+
+### `Answer`
+[implementation](./exercise_code/dict.cpp)
+
+### Exercises 10.2-6
+***
The dynamic-set operation UNION takes two disjoint sets S1 and S2 as input, and it returns a set S = S1 U S2 consisting of all the elements of S1 and S2. The sets S1 and S2 are usually destroyed by the operation. Show how to support UNION in O(1) time using a suitable list data structure.
-
-### `Answer`
-如果用链表实现,可以将第二个list连接到第一个list上.
-
-### Exercises 10.2-7
-***
-Give a Θ(n)-time nonrecursive procedure that reverses a singly linked list of n elements. The procedure should use no more than constant storage beyond that needed for the list itself.
-
-### `Answer`
-[solution](https://github.com/gzc/leetcode/blob/master/cpp/201-210/Reverse%20Linked%20List.cpp)
-
-### Exercises 10.2-8
-***
-Explain how to implement doubly linked lists using only one pointer value np[x] per item instead of the usual two (next and prev). Assume that all pointer values can be interpreted as k-bit integers, and define np[x] to be np[x] = next[x] XOR prev[x], the k-bit "exclusive-or" of next[x] and prev[x]. (The value NIL is represented by 0.) Be sure to describe what information is needed to access the head of the list. Show how to implement the SEARCH, INSERT, and DELETE operations on such a list. Also show how to reverse such a list in O(1) time.
-
-### `Answer`
-为了访问下一个元素,只需要XOR(np,prev).为了访问前一个元素,只需要XOR(np,next).
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+如果用链表实现,可以将第二个list连接到第一个list上.
+
+### Exercises 10.2-7
+***
+Give a Θ(n)-time nonrecursive procedure that reverses a singly linked list of n elements. The procedure should use no more than constant storage beyond that needed for the list itself.
+
+### `Answer`
+[solution](https://github.com/gzc/leetcode/blob/master/cpp/201-210/Reverse%20Linked%20List.cpp)
+
+### Exercises 10.2-8
+***
+Explain how to implement doubly linked lists using only one pointer value np[x] per item instead of the usual two (next and prev). Assume that all pointer values can be interpreted as k-bit integers, and define np[x] to be np[x] = next[x] XOR prev[x], the k-bit "exclusive-or" of next[x] and prev[x]. (The value NIL is represented by 0.) Be sure to describe what information is needed to access the head of the list. Show how to implement the SEARCH, INSERT, and DELETE operations on such a list. Also show how to reverse such a list in O(1) time.
+
+### `Answer`
+为了访问下一个元素,只需要XOR(np,prev).为了访问前一个元素,只需要XOR(np,next).
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C10-Elementary-Data-Structures/10.3.md b/C10-Elementary-Data-Structures/10.3.md
index 3cb6fb1c..d940bb72 100644
--- a/C10-Elementary-Data-Structures/10.3.md
+++ b/C10-Elementary-Data-Structures/10.3.md
@@ -1,80 +1,82 @@
-### Exercises 10.3-1
-***
-Draw a picture of the sequence[13, 4, 8, 19, 5, 11]stored as a doubly linked list using the multiple-array representation. Do the same for the single-array representation.
-
-### `Answer`
-+---+
-| L |-------------------------------------------+
-+---+ V
- 1 2 3 4 5 6 7 8 9 10 11 12
- +----+----+----+----+----+----+----+----+----+----+----+----+
-next | | | 5 | 7 | 10 | | / | | 3 | 4 | | |
- +----+----+----+----+----+----+----+----+----+----+----+----+
- key | | | 4 | 5 | 8 | | 11 | | 13 | 19 | | |
- +----+----+----+----+----+----+----+----+----+----+----+----+
-prev | | | 8 | 10 | 2 | | 4 | | / | 5 | | |
- +----+----+----+----+----+----+----+----+----+----+----+----+
-
-
-
-+----+----+----+
-| key|next|prev|
-+----+----+----+
-
-13 is head.
-
- 1 2 3 4 5 6 7 8 9 10 11 12
-+----+----+----++----+----+----++----+----+----++----+----+----++--
-| 4 | 7 | 13 || 5 | 10 | 16 || 8 | 16 | 1 || 11 | / | 4 ||
-+----+----+----++----+----+----++----+----+----++----+----+----++--
-
- 13 14 15 16 17 18
- --++----+----+----++----+----+----+
- || 13 | 1 | / || 19 | 4 | 7 |
- --++----+----+----++----+----+----+
-
-
-
-
-### Exercises 10.3-2
-***
+### Exercises 10.3-1
+***
+Draw a picture of the sequence[13, 4, 8, 19, 5, 11]stored as a doubly linked list using the multiple-array representation. Do the same for the single-array representation.
+
+
+### `Answer`
++---+
+| L |-------------------------------------------+
++---+ V
+ 1 2 3 4 5 6 7 8 9 10 11 12
+ +----+----+----+----+----+----+----+----+----+----+----+----+
+next | | | 5 | 7 | 10 | | / | | 3 | 4 | | |
+ +----+----+----+----+----+----+----+----+----+----+----+----+
+ key | | | 4 | 5 | 8 | | 11 | | 13 | 19 | | |
+ +----+----+----+----+----+----+----+----+----+----+----+----+
+prev | | | 8 | 10 | 2 | | 4 | | / | 5 | | |
+ +----+----+----+----+----+----+----+----+----+----+----+----+
+
+
+
++----+----+----+
+| key|next|prev|
++----+----+----+
+
+13 is head.
+
+ 1 2 3 4 5 6 7 8 9 10 11 12
++----+----+----++----+----+----++----+----+----++----+----+----++--
+| 4 | 7 | 13 || 5 | 10 | 16 || 8 | 16 | 1 || 11 | / | 4 ||
++----+----+----++----+----+----++----+----+----++----+----+----++--
+
+ 13 14 15 16 17 18
+ --++----+----+----++----+----+----+
+ || 13 | 1 | / || 19 | 4 | 7 |
+ --++----+----+----++----+----+----+
+
+
+
+
+### Exercises 10.3-2
+***
Write the procedures ALLOCATE-OBJECT and FREE-OBJECT for a homogeneous collection of objects implemented by the single-array representation.
-
-### `Answer`
-[implementation](./exercise_code/af-obj.c)
-
-### Exercises 10.3-3
-***
-Why don't we need to set or reset the prev fields of objects in the implementation of the ALLOCATE-OBJECT and FREE-OBJECT procedures?
-
-### `Answer`
-
-因为这类似于一个栈,没有prev.
-
-### Exercises 10.3-4
-***
-It is often desirable to keep all elements of a doubly linked list compact in storage, using, for example, the first m index locations in the multiple-array representation. (This is the case in a paged, virtual-memory computing environment.) Explain how the procedures ALLOCATE>- OBJECT and FREE-OBJECT can be implemented so that the representation is compact. Assume that there are no pointers to elements of the linked list outside the list itself. (Hint: Use the array implementation of a stack.)
-
-### `Answer`
-
-* ALLOCATE:选free_list的head.
-* FREE-OBJECT:不是直接变成head,而是按sorted的方式插入.
-
-这样可以保证每次分配的时候取排在最前面的空位置
-
-
-
-### Exercises 10.3-5
-***
-Let L be a doubly linked list of length m stored in arrays key, prev, and next of length n. Suppose that these arrays are managed by ALLOCATE-OBJECT and FREE-OBJECT procedures that keep a doubly linked free list F. Suppose further that of the n items, exactly m are on list L and n-m are on the free list. Write a procedure COMPACTIFY-LIST(L, F) that, given the list L and the free list F, moves the items in L so that they occupy array positions 1, 2,..., m and adjusts the free list F so that it remains correct, occupying array positions m + 1, m + 2,..., n. The running time of your procedure should be Θ(n), and it should use only a constant amount of extra space. Give a careful argument for the correctness of your procedure.
-
-### `Answer`
-
-* 先遍历free_list,给每个item的prev标记一下,用来区别L中的item.
-* 两根指针,一根p1在array的头,另一个p2在尾巴.p1向右移动知道遇到free item,p2向左移动直到遇到used item,然后交换p1和p2的内容.遍历一直到p1,p2遇到为止.
-* 重新整理free_list中的元素.
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+[implementation](./exercise_code/af-obj.c)
+
+### Exercises 10.3-3
+***
+Why don't we need to set or reset the prev fields of objects in the implementation of the ALLOCATE-OBJECT and FREE-OBJECT procedures?
+
+### `Answer`
+
+因为这类似于一个栈,没有prev.
+
+### Exercises 10.3-4
+***
+It is often desirable to keep all elements of a doubly linked list compact in storage, using, for example, the first m index locations in the multiple-array representation. (This is the case in a paged, virtual-memory computing environment.) Explain how the procedures ALLOCATE>- OBJECT and FREE-OBJECT can be implemented so that the representation is compact. Assume that there are no pointers to elements of the linked list outside the list itself. (Hint: Use the array implementation of a stack.)
+
+
+### `Answer`
+
+* ALLOCATE:选free_list的head.
+* FREE-OBJECT:不是直接变成head,而是按sorted的方式插入.
+
+这样可以保证每次分配的时候取排在最前面的空位置
+
+
+
+### Exercises 10.3-5
+***
+Let L be a doubly linked list of length m stored in arrays key, prev, and next of length n. Suppose that these arrays are managed by ALLOCATE-OBJECT and FREE-OBJECT procedures that keep a doubly linked free list F. Suppose further that of the n items, exactly m are on list L and n-m are on the free list. Write a procedure COMPACTIFY-LIST(L, F) that, given the list L and the free list F, moves the items in L so that they occupy array positions 1, 2,..., m and adjusts the free list F so that it remains correct, occupying array positions m + 1, m + 2,..., n. The running time of your procedure should be Θ(n), and it should use only a constant amount of extra space. Give a careful argument for the correctness of your procedure.
+
+### `Answer`
+
+* 先遍历free_list,给每个item的prev标记一下,用来区别L中的item.
+* 两根指针,一根p1在array的头,另一个p2在尾巴.p1向右移动知道遇到free item,p2向左移动直到遇到used item,然后交换p1和p2的内容.遍历一直到p1,p2遇到为止.
+* 重新整理free_list中的元素.
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C11-Hash-Tables/11.2.md b/C11-Hash-Tables/11.2.md
index 0911eb10..b0b147d5 100644
--- a/C11-Hash-Tables/11.2.md
+++ b/C11-Hash-Tables/11.2.md
@@ -1,42 +1,46 @@
-### Exercises 11.2-1
-***
-Suppose we use a hash function h to hash n distinct keys into an array T of length m. Assuming simple uniform hashing, what is the expected number of collisions? More precisely, what is the expected cardinality of {{k, l} : k ≠ l and h(k) = h(l)}?
-
-### `Answer`
-
-
-
-### Exercises 11.2-2
-***
+### Exercises 11.2-1
+***
+Suppose we use a hash function h to hash n distinct keys into an array T of length m. Assuming simple uniform hashing, what is the expected number of collisions? More precisely, what is the expected cardinality of {{k, l} : k ≠ l and h(k) = h(l)}?
+
+
+### `Answer`
+
+
+
+### Exercises 11.2-2
+***
Demonstrate the insertion of the keys 5, 28, 19, 15, 20, 33, 12, 17, 10 into a hash table with collisions resolved by chaining. Let the table have 9 slots, and let the hash function be h(k) = k mod 9.
-
-### `Answer`
-
-
-### Exercises 11.2-3
-***
+
+### `Answer`
+
+
+### Exercises 11.2-3
+***
Professor Marley hypothesizes that substantial performance gains can be obtained if we modify the chaining scheme so that each list is kept in sorted order. How does the professor's modification affect the running time for successful searches, unsuccessful searches, insertions, and deletions?
-
-### `Answer`
-* successful searches:没有影响
-* unsuccessful searches:当数据量大可以加速,可以提前判断元素是否在区间内
-* insertions:降低了插入的速度,需要遍历链表插入在合适的位置
-* deletions:没有影响
-
-### Exercises 11.2-4
-***
-Suggest how storage for elements can be allocated and deallocated within the hash table itself by linking all unused slots into a free list. Assume that one slot can store a flag and either one element plus a pointer or two pointers. All dictionary and free-list operations should run in O(1) expected time. Does the free list need to be doubly linked, or does a singly linked free list suffice?
-
-### `Answer`
-需要双链表.每个slot有一个标识标识是否已分配,如果没有分配指针指向free list的属于自己的那个位置. 删除的时候将标志位清一下,将自己加入链表头,指针指向头;插入时根据指针去取.
-
-### Exercises 11.2-5
-***
-Show that if |U| > nm, there is a subset of U of size n consisting of keys that all hash to the
same slot, so that the worst-case searching time for hashing with chaining is Θ(n).
-
### `Answer`
+
+### `Answer`
+* successful searches:没有影响
+* unsuccessful searches:当数据量大可以加速,可以提前判断元素是否在区间内
+* insertions:降低了插入的速度,需要遍历链表插入在合适的位置
+* deletions:没有影响
+
+### Exercises 11.2-4
+***
+Suggest how storage for elements can be allocated and deallocated within the hash table itself by linking all unused slots into a free list. Assume that one slot can store a flag and either one element plus a pointer or two pointers. All dictionary and free-list operations should run in O(1) expected time. Does the free list need to be doubly linked, or does a singly linked free list suffice?
+
+### `Answer`
+需要双链表.每个slot有一个标识标识是否已分配,如果没有分配指针指向free list的属于自己的那个位置. 删除的时候将标志位清一下,将自己加入链表头,指针指向头;插入时根据指针去取.
+
+### Exercises 11.2-5
+***
+Show that if |U| > nm, there is a subset of U of size n consisting of keys that all hash to the
+same slot, so that the worst-case searching time for hashing with chaining is Θ(n).
+
+
+### `Answer`
如果|U| = nm,假设U的全集要均匀分到m个位置上,每个位置期望就有n个元素,因此至少有一个位置是有至少n个元素的,我们选取这个集合,查找操作需要的时间就是Θ(n).
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C11-Hash-Tables/problem.md b/C11-Hash-Tables/problem.md
index f859142c..dd67c797 100644
--- a/C11-Hash-Tables/problem.md
+++ b/C11-Hash-Tables/problem.md
@@ -1,50 +1,62 @@
### Problems 1 : Longest-probe bound for hashing
-***
-A hash table of size m is used to store n items, with n ≤ m/2. Open addressing is used for collision resolution.
-
**a.**Assuming uniform hashing, show that for i=1,2,…,n, the probability is at most 2^−k that the ith insertion requires strictly more than k probes.
-
**b.**Show that for i=1,2,…,n, the probability is O(1/n^2) that the ith insertion requires more than 2lgn probes.
-
Let the random variable Xi denote the number of probes required by the ith insertion. You have shown in part (b) that
- )
. Let the random variable
-
denote the maximum number of probes required by any of the n insertions.
-
**c.**Show that Pr{X > 2lgn}=O(1/n).
-
**d.**Show that the expected length E[X] of the longest probe sequence is O(lgn).
-### `Answer`
-**a.**
-
-P = (n/m)^k < (1/2)^k = 2^-k
-
-**b.**
-
-代入a中的结论即可
-
-**c.**
-
- )
-
-**d.**
-
-该题可以参考5.4.2节的关于**球与盒子**的结论和5.4.3节的关于**序列**的结论.
-
-我们把每次的概率放大为1/2(实际上是≤ 1/2的)
-
-所以是O(lgn)
-
-
-
+***
+A hash table of size m is used to store n items, with n ≤ m/2. Open addressing is used for collision resolution.
+
+**a.**Assuming uniform hashing, show that for i=1,2,…,n, the probability is at most 2^−k that the ith insertion requires strictly more than k probes.
+
+
+**b.**Show that for i=1,2,…,n, the probability is O(1/n^2) that the ith insertion requires more than 2lgn probes.
+
+Let the random variable Xi denote the number of probes required by the ith insertion. You have shown in part (b) that
+ )
+. Let the random variable
+
+denote the maximum number of probes required by any of the n insertions.
+
+**c.**Show that Pr{X > 2lgn}=O(1/n).
+
+**d.**Show that the expected length E[X] of the longest probe sequence is O(lgn).
+
+### `Answer`
+**a.**
+
+P = (n/m)^k < (1/2)^k = 2^-k
+
+**b.**
+
+代入a中的结论即可
+
+**c.**
+
+ )
+
+**d.**
+
+该题可以参考5.4.2节的关于**球与盒子**的结论和5.4.3节的关于**序列**的结论.
+
+我们把每次的概率放大为1/2(实际上是≤ 1/2的)
+
+所以是O(lgn)
+
+
+
### Problems 2 : Slot-size bound for chaining
-***
-Suppose that we have a hash table with n slots, with collisions resolved by chaining, and suppose that n keys are inserted into the table. Each key is equally likely to be hashed to each slot. Let M be the maximum number of keys in any slot after all the keys have been inserted. Your mission is to prove an O(lg n/lg lg n) upper bound on E[M], the expected value of M.
-
-**a.**
-Argue that the probability Qk that exactly k keys hash to a particular slot is given by
-
- \(1-\\frac{1}{n}\)^{n-k} C_k^n)
-
-### `Answer`
-
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+***
+Suppose that we have a hash table with n slots, with collisions resolved by chaining, and suppose that n keys are inserted into the table. Each key is equally likely to be hashed to each slot. Let M be the maximum number of keys in any slot after all the keys have been inserted. Your mission is to prove an O(lg n/lg lg n) upper bound on E[M], the expected value of M.
+
+**a.**
+Argue that the probability Qk that exactly k keys hash to a particular slot is given by
+
+ \(1-\\frac{1}{n}\)^{n-k} C_k^n)
+
+
+### `Answer`
+
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C12-Binary-Search-Trees/12.3.md b/C12-Binary-Search-Trees/12.3.md
index 8fd927f7..0a33c3e5 100644
--- a/C12-Binary-Search-Trees/12.3.md
+++ b/C12-Binary-Search-Trees/12.3.md
@@ -1,59 +1,59 @@
-### Exercises 12.3-1
-***
-Give a recursive version of the TREE-INSERT procedure.
-
-### `Answer`
-
-
-
-### Exercises 12.3-2
-***
-Suppose that a binary search tree is constructed by repeatedly inserting distinct values into the tree. Argue that the number of nodes examined in searching for a value in the tree is one plus the number of nodes examined when the value was first inserted into the tree.
-
-### `Answer`
-多检查一次是否相等.
-
-We should check one more time of this node, obviously.
-
-### Exercises 12.3-3
-***
-We can sort a given set of n numbers by first building a binary search tree containing these numbers (using TREE-INSERT repeatedly to insert the numbers one by one) and then printing the numbers by an inorder tree walk. What are the worst-case and best-case running times for this sorting algorithm?
-
-### `Answer`
-退化成链表就是最坏情况.
-
-If it's Degenerated into a list, then the worst situation.
-
-
-### Exercises 12.3-4
+### Exercises 12.3-1
+***
+Give a recursive version of the TREE-INSERT procedure.
+
+### `Answer`
+
+
+
+### Exercises 12.3-2
+***
+Suppose that a binary search tree is constructed by repeatedly inserting distinct values into the tree. Argue that the number of nodes examined in searching for a value in the tree is one plus the number of nodes examined when the value was first inserted into the tree.
+
+### `Answer`
+多检查一次是否相等.
+
+We should check one more time of this node, obviously.
+
+### Exercises 12.3-3
+***
+We can sort a given set of n numbers by first building a binary search tree containing these numbers (using TREE-INSERT repeatedly to insert the numbers one by one) and then printing the numbers by an inorder tree walk. What are the worst-case and best-case running times for this sorting algorithm?
+
+### `Answer`
+退化成链表就是最坏情况.
+
+If it's Degenerated into a list, then the worst situation.
+
+
+### Exercises 12.3-4
Suppose that another data structure contains a pointer to a node y in a binary search tree, and suppose that y's predecessor z is deleted from the tree by the procedure TREE-DELETE. What problem can arise? How can TREE-DELETE be rewritten to solve this problem?
-### `Answer`
-当要删除的节点有两个子节点时,节点y会被删除. 如果指向的是节点y,那么就出问题的.在这种情况下应该修改成指向节点z.
-
-If the node being deleted has two child nodes, then y will be deleted. If the pointer point to y, there will be problem. Under such situation, the pointer should point to node z.
-
-
-### Exercises 12.3-5
-***
+### `Answer`
+当要删除的节点有两个子节点时,节点y会被删除. 如果指向的是节点y,那么就出问题的.在这种情况下应该修改成指向节点z.
+
+If the node being deleted has two child nodes, then y will be deleted. If the pointer point to y, there will be problem. Under such situation, the pointer should point to node z.
+
+
+### Exercises 12.3-5
+***
Is the operation of deletion "commutative" in the sense that deleting x and then y from a binary search tree leaves the same tree as deleting y and then x? Argue why it is or give a counterexample.
-
-### `Answer`
-NO.
-
-
-
-### Exercises 12.3-6
-***
+
+### `Answer`
+NO.
+
+
+
+### Exercises 12.3-6
+***
When node z in TREE-DELETE has two children, we could splice out its predecessor rather than its successor. Some have argued that a fair strategy, giving equal priority to predecessor and successor, yields better empirical performance. How might TREE-DELETE be changed to implement such a fair strategy?
-
-### `Answer`
-
-* Randomly choose one
-* Assign each node with an attribute **height**, choose the higher one.
-
-
-
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+
+* Randomly choose one
+* Assign each node with an attribute **height**, choose the higher one.
+
+
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C13-Red-Black-Trees/13.1.md b/C13-Red-Black-Trees/13.1.md
index 54d5a7dd..eae0f7ef 100644
--- a/C13-Red-Black-Trees/13.1.md
+++ b/C13-Red-Black-Trees/13.1.md
@@ -1,63 +1,64 @@
-### Exercises 13.1-1
-***
+### Exercises 13.1-1
+***
In the style of Figure 13.1(a), draw the complete binary search tree of height 3 on the keys {1, 2, ..., 15}. Add the NIL leaves and color the nodes in three different ways such that the black- heights of the resulting red-black trees are 2, 3, and 4.
-
-### `Answer`
-因为是一颗完全二叉树,超级平衡,所以填色很容易. 感谢[psu](http://test.scripts.psu.edu/users/d/j/djh300/cmpsc465/notes-4985903869437/solutions-to-some-homework-exercises-as-shared-with-students/3-solutions-clrs-13.pdf)提供的图片
-
-
-
-### Exercises 13.1-2
-***
-Draw the red-black tree that results after TREE-INSERT is called on the tree in Figure 13.1 with key 36. If the inserted node is colored red, is the resulting tree a red-black tree? What if it is colored black?
-
-### `Answer`
-插入后如何上红色,那么违反了红节点的儿子节点是黑色这个规则.
-
-
-插入后如何上黑色,那么违反了路径上包含相同黑节点数这个规则.
-
-
-
-### Exercises 13.1-3
-***
-Let us define a **relaxed red-black tree** as a binary search tree that satisfies red- black properties 1, 3, 4, and 5. In other words, the root may be either red or black. Consider a relaxed red-black tree *T* whose root is red. If we color the root of *T* black but make no other changes to *T*, is the resulting tree a red-black tree?
-
-### `Answer`
-当然还是~
-
-### Exercises 13.1-4
-***
-Suppose that we "absorb" every red node in a red-black tree into its black parent, so that the children of the red node become children of the black parent. (Ignore what happens to the keys.) What are the possible degrees of a black node after all its red children are absorbed? What can you say about the depths of the leaves of the resulting tree?
-### `Answer`
-* 2, 如果该节点的两个子结点都是黑的.
-* 3, 如果仅有一个子结点是红的.
-* 4, 如果两个子结点都是红的.
-
-所有的叶子节点都有相同的高度.
-
-### Exercises 13.1-5
-***
-Show that the longest simple path from a node *x* in a red-black tree to a descendant leaf has
length at most twice that of the shortest simple path from node x to a descendant leaf.
-### `Answer`
-根据性质5,最长和最短路径都有相同的黑节点数. 根据性质4可知路径上红节点数目不会超过黑节点,可得.
-
-### Exercises 13.1-6
-***
-What is the largest possible number of internal nodes in a red-black tree with black-height *k*? What is the smallest possible number?
-
-### `Answer`
-假如有一颗完美二叉树,如果每个节点都是黑的,那么总的节点个数是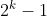
-假如是一黑一红交替,那么总高度就是2k-1,总节点个数是
-
-
-### Exercises 13.1-7
-***
-Describe a red-black tree on *n* keys that realizes the largest possible ratio of red internal nodes to black internal nodes. What is this ratio? What tree has the smallest possible ratio, and what is the ratio?
-
-* 最大的比值是2,根节点是黑色,两个子节点是红色.
-* 最小的比值是0,比如只有一个黑色的根节点.
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+因为是一颗完全二叉树,超级平衡,所以填色很容易. 感谢[psu](http://test.scripts.psu.edu/users/d/j/djh300/cmpsc465/notes-4985903869437/solutions-to-some-homework-exercises-as-shared-with-students/3-solutions-clrs-13.pdf)提供的图片
+
+
+
+### Exercises 13.1-2
+***
+Draw the red-black tree that results after TREE-INSERT is called on the tree in Figure 13.1 with key 36. If the inserted node is colored red, is the resulting tree a red-black tree? What if it is colored black?
+
+### `Answer`
+插入后如何上红色,那么违反了红节点的儿子节点是黑色这个规则.
+
+
+插入后如何上黑色,那么违反了路径上包含相同黑节点数这个规则.
+
+
+
+### Exercises 13.1-3
+***
+Let us define a **relaxed red-black tree** as a binary search tree that satisfies red- black properties 1, 3, 4, and 5. In other words, the root may be either red or black. Consider a relaxed red-black tree *T* whose root is red. If we color the root of *T* black but make no other changes to *T*, is the resulting tree a red-black tree?
+
+### `Answer`
+当然还是~
+
+### Exercises 13.1-4
+***
+Suppose that we "absorb" every red node in a red-black tree into its black parent, so that the children of the red node become children of the black parent. (Ignore what happens to the keys.) What are the possible degrees of a black node after all its red children are absorbed? What can you say about the depths of the leaves of the resulting tree?
+### `Answer`
+* 2, 如果该节点的两个子结点都是黑的.
+* 3, 如果仅有一个子结点是红的.
+* 4, 如果两个子结点都是红的.
+
+所有的叶子节点都有相同的高度.
+
+### Exercises 13.1-5
+***
+Show that the longest simple path from a node *x* in a red-black tree to a descendant leaf has
+length at most twice that of the shortest simple path from node x to a descendant leaf.
+### `Answer`
+根据性质5,最长和最短路径都有相同的黑节点数. 根据性质4可知路径上红节点数目不会超过黑节点,可得.
+
+### Exercises 13.1-6
+***
+What is the largest possible number of internal nodes in a red-black tree with black-height *k*? What is the smallest possible number?
+
+### `Answer`
+假如有一颗完美二叉树,如果每个节点都是黑的,那么总的节点个数是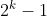
+假如是一黑一红交替,那么总高度就是2k-1,总节点个数是
+
+
+### Exercises 13.1-7
+***
+Describe a red-black tree on *n* keys that realizes the largest possible ratio of red internal nodes to black internal nodes. What is this ratio? What tree has the smallest possible ratio, and what is the ratio?
+
+* 最大的比值是2,根节点是黑色,两个子节点是红色.
+* 最小的比值是0,比如只有一个黑色的根节点.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C13-Red-Black-Trees/problem.md b/C13-Red-Black-Trees/problem.md
index 6fd545d7..d7000b4f 100644
--- a/C13-Red-Black-Trees/problem.md
+++ b/C13-Red-Black-Trees/problem.md
@@ -1,98 +1,137 @@
-### Problems 1 : Persistent dynamic sets
-***
-
a. For a general persistent binary search tree, identify the nodes that need to be changed to insert a key k or delete a node y.
-
b. Write a procedure PERSISTENT-TREE-INSERT that, given a persistent tree T and a key k to insert, returns a new persistent tree T′ that is the result of inserting k into T.
-
c. If the height of the persistent binary search tree T is h, what are the time and space requirements of your implementation of PERSISTENT-TREE-INSERT? (The space requirement is proportional to the number of new nodes allocated.)
-
d. Suppose that we had included the parent field in each node. In this case, PERSISTENT-TREE-INSERT would need to perform additional copying. Prove that PERSISTENT-TREE-INSERT would then require Ω(n) time and space, where n is the number of nodes in the tree.
-
e. Show how to use red-black trees to guarantee that the worst-case running time and space are O(lg n) per insertion or deletion.
-
-### `Answer`
-a. 插入的时候,需要改变根节点到这个叶子节点路径上的所有节点. BST删除有3种情况,如果删除的是根节点,那么需要改变根节点到这个叶子节点路径上的所有节点; 如果删除的节点只有一个子节点,那么需要改变根节点到这个删除节点路径之间的所有节点; 如果删除的节点有两个子节点,那么也是需要修改被影响的路径.只有一条路径被影响,因为某个节点和其后继肯定是同一条路径的.
-
-b. 先定义两个操作. MAKE-NEW-NODE(k) 创建一个键值为k的新节点,左儿子和右儿子默认为NIL,并返回这个节点;COPY-NODE(x) 创建一个和x一模一样的节点并返回.
-r是根节点
-
-
-c. O(h)的时间和空间
-
-d. 很好理解,因为根节点变了,所以子节点要指向新的节点,必然也要创建新的子节点.
-
-e. 首先要认识到最重要的两点. 1. 根据d可知节点不能有parent属性,因此我们在RB-INSERT的时候需要用stack去保存从根到叶子节点,然后将这个stack作为参数传到RB-INSERT-FIXUP或者RB-DELETE. 2. 旋转或重新着色不会改变超过O(lgn)的节点.
-INSERT : 首先和BST一样,最后插入了红节点. 有3种case,第一种节点z上升两层,修改了z的父亲节点(INSERT的时候已经创建),爷爷节点(INSERT的时候已经创建)和叔父节点(调用COPY-NODE创建并修改颜色),所以这种情况只创建了一个新节点和修改3次颜色. 而case2和case3执行后是不会再次循环的,最多旋转两次. case2和case3只对6个节点进行操作,而且这6个节点都已经创建出来,只是简单的修改指针和颜色.
-DELETE : 4个case,只有case2会进入循环,最多会执行3次rotation结束. case1会创建新节点D;case2也会创建新节点D,然后节点x往上移动一层;case3会创建新节点C和D;case4会创建新节点D和E(注意,不一定会创建,如果一个case是从其他来的有些节点就已经创建好了).
-
-
-
-
-### Problems 2 : Join operation on red-black trees
-***
-a. Given a red-black tree T, we store its black-height as the field bh[T]. Argue that this field can be maintained by RB-INSERT and RB-DELETE without requiring extra storage in the nodes of the tree and without increasing the asymptotic running times. Show that while descending through T, we can determine the black-height of each node we visit in O(1) time per node visited.
b. Assume that bh[T1] ≥ bh[T2]. Describe an O(lg n)-time algorithm that finds a black node y in T1 with the largest key from among those nodes whose black-height is bh[T2].
-
c. Let Ty be the subtree rooted at y. Describe how

can replace  in O(1) time without destroying the binary-search-tree property.
-
d. What color should we make x so that red-black properties 1, 3, and 5 are maintained? Describe how properties 2 and 4 can be enforced in O(lg n) time.
-
e. Argue that no generality is lost by making the assumption in part (b). Describe the symmetric situation that arises when bh[T1] = bh[T2].
-
f. Argue that the running time of RB-JOIN is O(lg n).
-
-### `Answer`
-a. 在insert时,如果迭代回到根节点并修改了颜色,那么黑高度就+1;在delete时,如果迭代回到根节点,那么黑高度就-1;当T沿高度下降时,每遇到一个黑节点就将黑高度-1,自然是O(1)的.
-
-b. 从T1往下迭代,有右节点就走右节点;碰到黑节点黑高度就-1,一直到黑高度为bh[T2].
-
-c. 构造子树以x为根,左儿子是右儿子是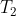,将x挂到y的父节点下面,并将x设为RED(保持性质5).
-
-d. RED.当y的父节点是红色时需要调整,根INSERT-FIXUP的case1类似,是O(lgn).
-
-e. 情况反一下而已~
-
-f. 根据前面的分析,是log(n)的.
-
-
-### Problems 3 : AVL trees
-***
-An **AVL tree** is a binary search tree that is **height balanced**: for each node x, the heights of the left and right subtrees of x differ by at most 1. To implement an AVL tree, we maintain an extra field in each node: h[x] is the height of node x. As for any other binary search tree T, we assume that root[T] points to the root node.
-
a. Prove that an AVL tree with n nodes has height O(lg n). (Hint: Prove that in an AVL tree of height h, there are at least Fh nodes, where Fh is the hth Fibonacci number.)
-
b. To insert into an AVL tree, a node is first placed in the appropriate place in binary
search tree order. After this insertion, the tree may no longer be height balanced. Specifically, the heights of the left and right children of some node may differ by 2. Describe a procedure BALANCE(x), which takes a subtree rooted at x whose left and right children are height balanced and have heights that differ by at most 2, i.e., |h[right[x]] - h[left[x]]| ≤ 2, and alters the subtree rooted at x to be height balanced. (Hint: Use rotations.)
-
c. Using part (b), describe a recursive procedure AVL-INSERT(x, z), which takes a node x within an AVL tree and a newly created node z (whose key has already been filled in), and adds z to the subtree rooted at x, maintaining the property that x is the root of an AVL tree. As in TREE-INSERT from Section 12.3, assume that key[z] has already been filled in and that left[z] = NIL and right[z] = NIL; also assume that h[z] = 0. Thus, to insert the node z into the AVL tree T, we call AVL-INSERT(root[T], z).
-
d. Show that AVL-INSERT,run on an n-node AVL tree,takes O(lgn) time and performs O(1) rotations.
-
-### `Answer`
-a. 对于斐波那契数列有F(0) = 1, F(1) = 1, F(2) = 2,...,F(n) = F(n-1)+F(n-2).
-设T(n)为高度h的AVL树的最少节点数. 我们尝试证明 \\ge F\(n\)) .
-一开始,有\\ge F\(1\)) 和\\ge F\(2\))
-\\ge T\(n-1\) + T\(n-2\) + 1 \\\\ ~\\hspace{15 mm} \\ge F\(n-1\) + F\(n-2\) + 1 \\\\ ~\\hspace{15 mm}
- \> F\(n\)
-)
-
-并且有 \\le 1.6^n),
-因此 = O\( \\lg\(n\) \) ).
-
-b. thanks [mit](http://courses.csail.mit.edu/6.046/spring04/handouts/ps5-sol.pdf) for this picture. 只画出了右边大于左边的情况.
-
-
-
-c.
-
-
-
-d. 因为AVL树的高度是lg(h),所以AVL-INSERT需要P(lgn)的时间.因为BALANCE操作会将不平衡的子树的高度减掉1,所以不会影响到其他地方.
-
-
-### Problems 4 : Treaps
-***
-a. Show that given a set of nodes x1, x2, ..., xn, with associated keys and priorities (all distinct), there is a unique treap associated with these nodes.
-
b. Show that the expected height of a treap is Θ(lg n), and hence the time to search for a value in the treap is Θ(lg n).
-
c. Explain how TREAP-INSERT works. Explain the idea in English and give pseudocode. (Hint: Execute the usual binary-search-tree insertion procedure and then perform rotations to restore the min-heap order property.)
-
d. Show that the expected running time of TREAP-INSERT is Θ(lg n).
-
e. Consider the treap T immediately after x is inserted using TREAP-INSERT. Let C be the length of the right spine of the left subtree of x. Let D be the length of the left spine of the right subtree of x. Prove that the total number of rotations that were performed during the insertion of x is equal to C + D.
-
### `Answer`
-
a. Treap会将结点以它们的优先级的顺序插入一颗正常的二叉树. 假如n-1个节点的Treap是确定的,因为INSERT算法是确定性算法,可以得到n个节点的Treap也是确定的.
-
b. 采取随机分配优先级的方法和随机构造的BST是等价的,因此是O(lg n)的.
-
c.

-
-d. 比较明显就不证明了.
-
-e. 每一次旋转, C+D都会增加1;画张图出来会很明显的.
-
-这题剩下的[答案](http://www2.myoops.org/twocw/mit/NR/rdonlyres/Electrical-Engineering-and-Computer-Science/6-046JFall-2005/760259F8-457D-4895-AFDC-8CE9C73D18A5/0/ps4sol.pdf)
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+### Problems 1 : Persistent dynamic sets
+***
+
+a. For a general persistent binary search tree, identify the nodes that need to be changed to insert a key k or delete a node y.
+
+
+b. Write a procedure PERSISTENT-TREE-INSERT that, given a persistent tree T and a key k to insert, returns a new persistent tree T′ that is the result of inserting k into T.
+
+
+c. If the height of the persistent binary search tree T is h, what are the time and space requirements of your implementation of PERSISTENT-TREE-INSERT? (The space requirement is proportional to the number of new nodes allocated.)
+
+
+d. Suppose that we had included the parent field in each node. In this case, PERSISTENT-TREE-INSERT would need to perform additional copying. Prove that PERSISTENT-TREE-INSERT would then require Ω(n) time and space, where n is the number of nodes in the tree.
+
+
+e. Show how to use red-black trees to guarantee that the worst-case running time and space are O(lg n) per insertion or deletion.
+
+### `Answer`
+a. 插入的时候,需要改变根节点到这个叶子节点路径上的所有节点. BST删除有3种情况,如果删除的是根节点,那么需要改变根节点到这个叶子节点路径上的所有节点; 如果删除的节点只有一个子节点,那么需要改变根节点到这个删除节点路径之间的所有节点; 如果删除的节点有两个子节点,那么也是需要修改被影响的路径.只有一条路径被影响,因为某个节点和其后继肯定是同一条路径的.
+
+b. 先定义两个操作. MAKE-NEW-NODE(k) 创建一个键值为k的新节点,左儿子和右儿子默认为NIL,并返回这个节点;COPY-NODE(x) 创建一个和x一模一样的节点并返回.
+r是根节点
+
+
+c. O(h)的时间和空间
+
+d. 很好理解,因为根节点变了,所以子节点要指向新的节点,必然也要创建新的子节点.
+
+e. 首先要认识到最重要的两点. 1. 根据d可知节点不能有parent属性,因此我们在RB-INSERT的时候需要用stack去保存从根到叶子节点,然后将这个stack作为参数传到RB-INSERT-FIXUP或者RB-DELETE. 2. 旋转或重新着色不会改变超过O(lgn)的节点.
+INSERT : 首先和BST一样,最后插入了红节点. 有3种case,第一种节点z上升两层,修改了z的父亲节点(INSERT的时候已经创建),爷爷节点(INSERT的时候已经创建)和叔父节点(调用COPY-NODE创建并修改颜色),所以这种情况只创建了一个新节点和修改3次颜色. 而case2和case3执行后是不会再次循环的,最多旋转两次. case2和case3只对6个节点进行操作,而且这6个节点都已经创建出来,只是简单的修改指针和颜色.
+DELETE : 4个case,只有case2会进入循环,最多会执行3次rotation结束. case1会创建新节点D;case2也会创建新节点D,然后节点x往上移动一层;case3会创建新节点C和D;case4会创建新节点D和E(注意,不一定会创建,如果一个case是从其他来的有些节点就已经创建好了).
+
+
+
+
+### Problems 2 : Join operation on red-black trees
+***
+a. Given a red-black tree T, we store its black-height as the field bh[T]. Argue that this field can be maintained by RB-INSERT and RB-DELETE without requiring extra storage in the nodes of the tree and without increasing the asymptotic running times. Show that while descending through T, we can determine the black-height of each node we visit in O(1) time per node visited.
+
+b. Assume that bh[T1] ≥ bh[T2]. Describe an O(lg n)-time algorithm that finds a black node y in T1 with the largest key from among those nodes whose black-height is bh[T2].
+
+
+c. Let Ty be the subtree rooted at y. Describe how
+
+can replace  in O(1) time without destroying the binary-search-tree property.
+
+
+d. What color should we make x so that red-black properties 1, 3, and 5 are maintained? Describe how properties 2 and 4 can be enforced in O(lg n) time.
+
+
+e. Argue that no generality is lost by making the assumption in part (b). Describe the symmetric situation that arises when bh[T1] = bh[T2].
+
+
+f. Argue that the running time of RB-JOIN is O(lg n).
+
+### `Answer`
+a. 在insert时,如果迭代回到根节点并修改了颜色,那么黑高度就+1;在delete时,如果迭代回到根节点,那么黑高度就-1;当T沿高度下降时,每遇到一个黑节点就将黑高度-1,自然是O(1)的.
+
+b. 从T1往下迭代,有右节点就走右节点;碰到黑节点黑高度就-1,一直到黑高度为bh[T2].
+
+c. 构造子树以x为根,左儿子是右儿子是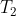,将x挂到y的父节点下面,并将x设为RED(保持性质5).
+
+d. RED.当y的父节点是红色时需要调整,根INSERT-FIXUP的case1类似,是O(lgn).
+
+e. 情况反一下而已~
+
+f. 根据前面的分析,是log(n)的.
+
+
+### Problems 3 : AVL trees
+***
+An **AVL tree** is a binary search tree that is **height balanced**: for each node x, the heights of the left and right subtrees of x differ by at most 1. To implement an AVL tree, we maintain an extra field in each node: h[x] is the height of node x. As for any other binary search tree T, we assume that root[T] points to the root node.
+
+a. Prove that an AVL tree with n nodes has height O(lg n). (Hint: Prove that in an AVL tree of height h, there are at least Fh nodes, where Fh is the hth Fibonacci number.)
+
+b. To insert into an AVL tree, a node is first placed in the appropriate place in binary
+search tree order. After this insertion, the tree may no longer be height balanced. Specifically, the heights of the left and right children of some node may differ by 2. Describe a procedure BALANCE(x), which takes a subtree rooted at x whose left and right children are height balanced and have heights that differ by at most 2, i.e., |h[right[x]] - h[left[x]]| ≤ 2, and alters the subtree rooted at x to be height balanced. (Hint: Use rotations.)
+
+c. Using part (b), describe a recursive procedure AVL-INSERT(x, z), which takes a node x within an AVL tree and a newly created node z (whose key has already been filled in), and adds z to the subtree rooted at x, maintaining the property that x is the root of an AVL tree. As in TREE-INSERT from Section 12.3, assume that key[z] has already been filled in and that left[z] = NIL and right[z] = NIL; also assume that h[z] = 0. Thus, to insert the node z into the AVL tree T, we call AVL-INSERT(root[T], z).
+
+d. Show that AVL-INSERT,run on an n-node AVL tree,takes O(lgn) time and performs O(1) rotations.
+
+### `Answer`
+a. 对于斐波那契数列有F(0) = 1, F(1) = 1, F(2) = 2,...,F(n) = F(n-1)+F(n-2).
+设T(n)为高度h的AVL树的最少节点数. 我们尝试证明 \\ge F\(n\)) .
+一开始,有\\ge F\(1\)) 和\\ge F\(2\))
+\\ge T\(n-1\) + T\(n-2\) + 1 \\\\ ~\\hspace{15 mm} \\ge F\(n-1\) + F\(n-2\) + 1 \\\\ ~\\hspace{15 mm}
+ \> F\(n\)
+)
+
+并且有 \\le 1.6^n),
+因此 = O\( \\lg\(n\) \) ).
+
+b. thanks [mit](http://courses.csail.mit.edu/6.046/spring04/handouts/ps5-sol.pdf) for this picture. 只画出了右边大于左边的情况.
+
+
+
+c.
+
+
+
+d. 因为AVL树的高度是lg(h),所以AVL-INSERT需要P(lgn)的时间.因为BALANCE操作会将不平衡的子树的高度减掉1,所以不会影响到其他地方.
+
+
+### Problems 4 : Treaps
+***
+a. Show that given a set of nodes x1, x2, ..., xn, with associated keys and priorities (all distinct), there is a unique treap associated with these nodes.
+
+b. Show that the expected height of a treap is Θ(lg n), and hence the time to search for a value in the treap is Θ(lg n).
+
+
+c. Explain how TREAP-INSERT works. Explain the idea in English and give pseudocode. (Hint: Execute the usual binary-search-tree insertion procedure and then perform rotations to restore the min-heap order property.)
+
+
+d. Show that the expected running time of TREAP-INSERT is Θ(lg n).
+
+
+e. Consider the treap T immediately after x is inserted using TREAP-INSERT. Let C be the length of the right spine of the left subtree of x. Let D be the length of the left spine of the right subtree of x. Prove that the total number of rotations that were performed during the insertion of x is equal to C + D.
+
+
+### `Answer`
+
+a. Treap会将结点以它们的优先级的顺序插入一颗正常的二叉树. 假如n-1个节点的Treap是确定的,因为INSERT算法是确定性算法,可以得到n个节点的Treap也是确定的.
+
+
+b. 采取随机分配优先级的方法和随机构造的BST是等价的,因此是O(lg n)的.
+
+c.

+
+d. 比较明显就不证明了.
+
+e. 每一次旋转, C+D都会增加1;画张图出来会很明显的.
+
+这题剩下的[答案](http://www2.myoops.org/twocw/mit/NR/rdonlyres/Electrical-Engineering-and-Computer-Science/6-046JFall-2005/760259F8-457D-4895-AFDC-8CE9C73D18A5/0/ps4sol.pdf)
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C14-Augmenting-Data-Structures/problem.md b/C14-Augmenting-Data-Structures/problem.md
index 93f5e1dc..c1d74bfd 100644
--- a/C14-Augmenting-Data-Structures/problem.md
+++ b/C14-Augmenting-Data-Structures/problem.md
@@ -1,61 +1,68 @@
### Problems 1 : Point of Maximum Overlap
-***
-Suppose that we wish to keep track of a **point of maximum overlap** in a set of intervals—a point that has the largest number of intervals in the database overlapping it.
-
a. Show that there will always be a point of maximum overlap which is an endpoint of one of the segments.
b. Design a data structure that efficiently supports the operations INTERVAL-INSERT, INTERVAL-DELETE, and FIND-POM, which returns a point of maximum overlap. (Hint: Keep a red-black tree of all the endpoints. Associate a value of +1 with each left endpoint, and associate a value of -1 with each right endpoint. Augment each node of the tree with some extra information to maintain the point of maximum overlap.)
-### `Answer`
-**a.**
-
-端点上的区间不会比其他地方的要少.
-
-**b.**
-
-[stackoverflow](http://stackoverflow.com/questions/14780324/point-of-maximum-overlap)
-
-a bit tricky!
-
-
-down vote
-accepted
-quote:http://ripcrixalis.blog.com/2011/02/08/clrs-chapter-14/
-
-Keep a RB-tree of all the endpoints. We insert endpoints one by one as a sweep line scaning from left to right. With each left endpoint e, associate a value p[e] = +1 (increasing the overlap by 1). With each right endpoint e associate a value p[e] = −1 (decreasing the overlap by 1). When multiple endpoints have the same value, insert all the left endpoints with that value before inserting any of the right endpoints with that value.
-
-Here is some intuition. Let e1, e2, . . . , en be the sorted sequence of endpoints corresponding to our intervals. Let s(i, j) denote the sum p[ei] + p[ei+1] + · · · + p[ej] for 1 ≤ i ≤ j ≤ n. We wish to find an i maximizing s(1, i ). Each node x stores three new attributes. We store v[x] = s(l[x], r [x]), the sum of the values of all nodes in x’s subtree. We also store m[x], the maximum value obtained by the expression s(l[x], i) for any i. We store o[x] as the value of i for which m[x] achieves its maximum. For the sentinel, we define v[nil[T]] = m[nil[T]] = 0.
-
-We can compute these attributes in a bottom-up fashion so as to satisfy the requirements of Theorem 14.1:
-
- v[x] = v[left[x]] + p[x] + v[right[x]] ,
- m[x] = max{
- m[left[x]] (max is in x’s left subtree),
- v[left[x]] + p[x] (max is at x),
- v[left[x]] + p[x] + m[right[x]] (max is in x’s right subtree). }
-Once we understand how to compute m[x], it is straightforward to compute o[x] from the information in x and its two children.
-
-FIND-POM: return the interval whose endpoint is represented by o[root[T]]. Because of how we have deÞned the new attributes, Theorem 14.1 says that each operation runs in O(lg n) time. In fact, FIND-POM takes only O(1) time.
-
-
+***
+Suppose that we wish to keep track of a **point of maximum overlap** in a set of intervals—a point that has the largest number of intervals in the database overlapping it.
+
+a. Show that there will always be a point of maximum overlap which is an endpoint of one of the segments.
+b. Design a data structure that efficiently supports the operations INTERVAL-INSERT, INTERVAL-DELETE, and FIND-POM, which returns a point of maximum overlap. (Hint: Keep a red-black tree of all the endpoints. Associate a value of +1 with each left endpoint, and associate a value of -1 with each right endpoint. Augment each node of the tree with some extra information to maintain the point of maximum overlap.)
+
+### `Answer`
+**a.**
+
+端点上的区间不会比其他地方的要少.
+
+**b.**
+
+[stackoverflow](http://stackoverflow.com/questions/14780324/point-of-maximum-overlap)
+
+a bit tricky!
+
+
+down vote
+accepted
+quote:http://ripcrixalis.blog.com/2011/02/08/clrs-chapter-14/
+
+Keep a RB-tree of all the endpoints. We insert endpoints one by one as a sweep line scaning from left to right. With each left endpoint e, associate a value p[e] = +1 (increasing the overlap by 1). With each right endpoint e associate a value p[e] = −1 (decreasing the overlap by 1). When multiple endpoints have the same value, insert all the left endpoints with that value before inserting any of the right endpoints with that value.
+
+Here is some intuition. Let e1, e2, . . . , en be the sorted sequence of endpoints corresponding to our intervals. Let s(i, j) denote the sum p[ei] + p[ei+1] + · · · + p[ej] for 1 ≤ i ≤ j ≤ n. We wish to find an i maximizing s(1, i ). Each node x stores three new attributes. We store v[x] = s(l[x], r [x]), the sum of the values of all nodes in x’s subtree. We also store m[x], the maximum value obtained by the expression s(l[x], i) for any i. We store o[x] as the value of i for which m[x] achieves its maximum. For the sentinel, we define v[nil[T]] = m[nil[T]] = 0.
+
+We can compute these attributes in a bottom-up fashion so as to satisfy the requirements of Theorem 14.1:
+
+ v[x] = v[left[x]] + p[x] + v[right[x]] ,
+ m[x] = max{
+ m[left[x]] (max is in x’s left subtree),
+ v[left[x]] + p[x] (max is at x),
+ v[left[x]] + p[x] + m[right[x]] (max is in x’s right subtree). }
+Once we understand how to compute m[x], it is straightforward to compute o[x] from the information in x and its two children.
+
+FIND-POM: return the interval whose endpoint is represented by o[root[T]]. Because of how we have deÞned the new attributes, Theorem 14.1 says that each operation runs in O(lg n) time. In fact, FIND-POM takes only O(1) time.
+
+
### Problems 2 : Josephus Permutation
-***
-The Josephus problem is defined as follows. Suppose that n people are arranged in a circle and that we are given a positive integer m ≤ n. Beginning with a designated first person, we proceed around the circle, removing every mth person. After each person is removed, counting continues around the circle that remains. This process continues until all n people have been removed. The order in which the people are removed from the circle defines the (n, m)-Josephus permutation of the integers 1, 2,..., n. For example, the (7, 3)-Josephus permutation is [3, 6, 2, 7, 5, 1, 4].
-
a. Suppose that m is a constant. Describe an O(n)-time algorithm that, given an integer n, outputs the (n, m)-Josephus permutation.
b. Suppose that m is not a constant. Describe an O(n lg n)-time algorithm that, given integers n and m, outputs the (n, m)-Josephus permutation.
-### `Answer`
-
-**a.** 使用循环列表. [implementation](./exercise_code/m-Josephus.cpp)
-
-**b.**
-
- JOSEPHUS(n,m)
- initialize T to be empty
- for j ← 1 to n
- do create a node x with key[x] = j
- OS-INSERT(T, x)
- j ← 1
- for k ← n downto 1
- do j ← (( j + m − 2) mod k) + 1
- x ← OS-SELECT(root[T ], j )
- print key[x]
+***
+The Josephus problem is defined as follows. Suppose that n people are arranged in a circle and that we are given a positive integer m ≤ n. Beginning with a designated first person, we proceed around the circle, removing every mth person. After each person is removed, counting continues around the circle that remains. This process continues until all n people have been removed. The order in which the people are removed from the circle defines the (n, m)-Josephus permutation of the integers 1, 2,..., n. For example, the (7, 3)-Josephus permutation is [3, 6, 2, 7, 5, 1, 4].
+
+a. Suppose that m is a constant. Describe an O(n)-time algorithm that, given an integer n, outputs the (n, m)-Josephus permutation.
+b. Suppose that m is not a constant. Describe an O(n lg n)-time algorithm that, given integers n and m, outputs the (n, m)-Josephus permutation.
+
+
+### `Answer`
+
+**a.** 使用循环列表. [implementation](./exercise_code/m-Josephus.cpp)
+
+**b.**
+
+ JOSEPHUS(n,m)
+ initialize T to be empty
+ for j ← 1 to n
+ do create a node x with key[x] = j
+ OS-INSERT(T, x)
+ j ← 1
+ for k ← n downto 1
+ do j ← (( j + m − 2) mod k) + 1
+ x ← OS-SELECT(root[T ], j )
+ print key[x]
OS-DELETE(T, x)
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C15-Dynamic-Programming/15.1.md b/C15-Dynamic-Programming/15.1.md
index 31eb437f..0afdf629 100644
--- a/C15-Dynamic-Programming/15.1.md
+++ b/C15-Dynamic-Programming/15.1.md
@@ -1,51 +1,57 @@
-### Exercises 15.1-1
-***
-Show how to modify the PRINT-STATIONS procedure to print out the stations in increasing order of station number. (Hint: Use recursion.)
-### `Answer`
-It's very easy.see my [implementation](./Assembly-line-sche.c)
-
-### Exercises 15.1-2
-***
+### Exercises 15.1-1
+***
+Show how to modify the PRINT-STATIONS procedure to print out the stations in increasing order of station number. (Hint: Use recursion.)
+
+### `Answer`
+It's very easy.see my [implementation](./Assembly-line-sche.c)
+
+### Exercises 15.1-2
+***
Use equations (15.8) and (15.9) and the substitution method to show that ri(j), the number of references made to fi[j] in a recursive algorithm, equals 2^(n - j).
-
-### `Answer`
-
-1. j = n时,r(i,j) = 1 = 2^(n-n) 成立
-
-2. 假设当j = k时, r(i,k) = 2^(n-k)
-当j = k -1时, r(i,k-1) = r(1,k)+r(2,k) = 2^(n-k) + 2^(n-k) = 2^(n-(k-1))
-
-3. 综上所述, 等式成立
-
-### Exercises 15.1-3
-***
-Using the result of Exercise 15.1-2, show that the total number of references to all fi[j] values, or 
-
-)
- , is exactly 2^(n+1) - 2.
-
-### `Answer`
-
-= 2\(\\sum_{j=1}^{n}2^{n-j}\) = 2\(2^n-1\) = 2^{n+1}-1)
-
-
-### Exercises 15.1-4
-***
+
+### `Answer`
+
+1. j = n时,r(i,j) = 1 = 2^(n-n) 成立
+
+2. 假设当j = k时, r(i,k) = 2^(n-k)
+当j = k -1时, r(i,k-1) = r(1,k)+r(2,k) = 2^(n-k) + 2^(n-k) = 2^(n-(k-1))
+
+3. 综上所述, 等式成立
+
+### Exercises 15.1-3
+***
+Using the result of Exercise 15.1-2, show that the total number of references to all fi[j] values, or 
+
+)
+ , is exactly 2^(n+1) - 2.
+
+
+
+### `Answer`
+
+= 2\(\\sum_{j=1}^{n}2^{n-j}\) = 2\(2^n-1\) = 2^{n+1}-1)
+
+
+### Exercises 15.1-4
+***
Together, the tables containing fi[j] and li[j] values contain a total of 4n - 2 entries. Show how to reduce the space requirements to a total of 2n + 2 entries, while still computing f* and still being able to print all the stations on a fastest way through the factory.
-
-### `Answer`
-It's simple.when we calculate f(n),we just need f(n-1).so we just alloc f1[2] and f2[2].
-
-
-### Exercises 15.1-5
-***
-Professor Canty conjectures that there might exist some ei, ai,j, and ti,j values for which FASTEST-WAY produces li[j] values such that l1[j] = 2 and l2[j] = 1 for some station number j. Assuming that all transfer costs ti,j are nonnegative, show that the professor is wrong.
-
### `Answer`
-if l1[j] = 2,then f1[j-1]>f2[j-1]+t(2,j-1) ------ @1
-
-if l2[j] = 1,then f2[j-1]>f1[j-1]+t(1,j-1) ------ @2
-
-we add @1 and @2,find that t(1,j-1)+t(2,j-1) < 0 wrong !!!!!!
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+It's simple.when we calculate f(n),we just need f(n-1).so we just alloc f1[2] and f2[2].
+
+
+### Exercises 15.1-5
+***
+Professor Canty conjectures that there might exist some ei, ai,j, and ti,j values for which FASTEST-WAY produces li[j] values such that l1[j] = 2 and l2[j] = 1 for some station number j. Assuming that all transfer costs ti,j are nonnegative, show that the professor is wrong.
+
+
+### `Answer`
+if l1[j] = 2,then f1[j-1]>f2[j-1]+t(2,j-1) ------ @1
+
+if l2[j] = 1,then f2[j-1]>f1[j-1]+t(1,j-1) ------ @2
+
+we add @1 and @2,find that t(1,j-1)+t(2,j-1) < 0 wrong !!!!!!
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C15-Dynamic-Programming/15.2.md b/C15-Dynamic-Programming/15.2.md
index c409e842..ae1e7e34 100644
--- a/C15-Dynamic-Programming/15.2.md
+++ b/C15-Dynamic-Programming/15.2.md
@@ -1,56 +1,63 @@
-### Exercises 15.2-1
-***
-Find an optimal parenthesization of a matrix-chain product whose sequence of dimensions is [5, 10, 3, 12, 5, 50, 6].
-### `Answer`
-It's very easy.see my [implementation](./Matrix-chain-multiplication.c)
-
-### Exercises 15.2-2
-***
-Give a recursive algorithm MATRIX-CHAIN-MULTIPLY(A, s, i, j) that actually performs the optimal matrix-chain multiplication, given the sequence of matrices [A1, A2, ..., An], the s table computed by MATRIX-CHAIN-ORDER, and the indices i and j. (The initial call would be MATRIX-CHAIN-MULTIPLY(A, s, 1, n).)
-
-### `Answer`
-we should modify PRINT_OPTIMAL_PARENS.
-
- MATRIX_CHAIN_MULTIPLY(A,s,i,j)
- if(i == j)
- return A[i]
- if(j == i+1)
- return A[i]*A[j];
- else
- B1 = MATRIX_CHAIN_MULTIPLY(A,s,i,S[i,j])
- B2 = MATRIX_CHAIN_MULTIPLY(A,s,S[i,j]+1,j)
- return B1*B2
-
-### Exercises 15.2-3
-***
-Use the substitution method to show that the solution to the recurrence (15.11) is Ω(2^n).
### `Answer`
-当n = 1时, 有p(n) = 1成立
-
-假设对任意的k < n都成立,即p(k) >= c2^k,则有
-
- = \\sum_{k=1}^{n-1}p\(k\)p\(n-k\) \\ge \\sum_{k=1}^{n-1}c2^kc2^{n-k} = c^2\(n-1\)2^n)
-
-因此,对于任意的c总有N0 = 1/c+1,使得当n > N0时, 有p(n) >= c2^n.
-
-### Exercises 15.2-4
-***
-Let R(i, j) be the number of times that table entry m[i, j] is referenced while computing other table entries in a call of MATRIX-CHAIN-ORDER. Show that the total number of references for the entire table is
-
-= \\frac{n^3-n}{3})
-
+### Exercises 15.2-1
+***
+Find an optimal parenthesization of a matrix-chain product whose sequence of dimensions is [5, 10, 3, 12, 5, 50, 6].
+
+### `Answer`
+It's very easy.see my [implementation](./Matrix-chain-multiplication.c)
+
+### Exercises 15.2-2
+***
+Give a recursive algorithm MATRIX-CHAIN-MULTIPLY(A, s, i, j) that actually performs the optimal matrix-chain multiplication, given the sequence of matrices [A1, A2, ..., An], the s table computed by MATRIX-CHAIN-ORDER, and the indices i and j. (The initial call would be MATRIX-CHAIN-MULTIPLY(A, s, 1, n).)
+
+
+### `Answer`
+we should modify PRINT_OPTIMAL_PARENS.
+
+ MATRIX_CHAIN_MULTIPLY(A,s,i,j)
+ if(i == j)
+ return A[i]
+ if(j == i+1)
+ return A[i]*A[j];
+ else
+ B1 = MATRIX_CHAIN_MULTIPLY(A,s,i,S[i,j])
+ B2 = MATRIX_CHAIN_MULTIPLY(A,s,S[i,j]+1,j)
+ return B1*B2
+
+### Exercises 15.2-3
+***
+Use the substitution method to show that the solution to the recurrence (15.11) is Ω(2^n).
+
+### `Answer`
+当n = 1时, 有p(n) = 1成立
+
+假设对任意的k < n都成立,即p(k) >= c2^k,则有
+
+ = \\sum_{k=1}^{n-1}p\(k\)p\(n-k\) \\ge \\sum_{k=1}^{n-1}c2^kc2^{n-k} = c^2\(n-1\)2^n)
+
+因此,对于任意的c总有N0 = 1/c+1,使得当n > N0时, 有p(n) >= c2^n.
+
+### Exercises 15.2-4
+***
+Let R(i, j) be the number of times that table entry m[i, j] is referenced while computing other table entries in a call of MATRIX-CHAIN-ORDER. Show that the total number of references for the entire table is
+
+= \\frac{n^3-n}{3})
+
(Hint: You may find equation (A.3) useful.)
-
-### `Answer`
- = \\sum_{l = 2}^{n}\(n-l+1\)\(l-1\)2 = 2\\sum_{l=1}^{n-1}l\(n-l\)= \\frac{n^3-n}{3})
-
-### Exercises 15.2-5
-***
-Show that a full parenthesization of an n-element expression has exactly n - 1 pairs of parentheses.
### `Answer`
-In our previous program,wt get ((A1(A2A3))((A4A5)A6)).
-
-n = 6,and we have 5 parentheses.
-
-A pair of parentheses musts contain a operator and n elements must have n-1 operators, so a full parenthesization of an n-element expression has exactly n-1 pairs of parentheses.
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+ = \\sum_{l = 2}^{n}\(n-l+1\)\(l-1\)2 = 2\\sum_{l=1}^{n-1}l\(n-l\)= \\frac{n^3-n}{3})
+
+### Exercises 15.2-5
+***
+Show that a full parenthesization of an n-element expression has exactly n - 1 pairs of parentheses.
+
+### `Answer`
+In our previous program,wt get ((A1(A2A3))((A4A5)A6)).
+
+n = 6,and we have 5 parentheses.
+
+A pair of parentheses musts contain a operator and n elements must have n-1 operators, so a full parenthesization of an n-element expression has exactly n-1 pairs of parentheses.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C15-Dynamic-Programming/15.3.md b/C15-Dynamic-Programming/15.3.md
index 54765d0d..6277156d 100644
--- a/C15-Dynamic-Programming/15.3.md
+++ b/C15-Dynamic-Programming/15.3.md
@@ -1,68 +1,74 @@
-### Exercises 15.3-1
-***
-Which is a more efficient way to determine the optimal number of multiplications in a matrix- chain multiplication problem: enumerating all the ways of parenthesizing the product and computing the number of multiplications for each, or running RECURSIVE-MATRIX- CHAIN? Justify your answer.
-### `Answer`
-15.2节给出枚举方法的时间复杂度为
-)
-
-The following are copied from solutions made by others, sorry I do not have author's name/
-
-对于RECURSIVE-MATRIX- CHAIN
-
-
-
-
-
-### Exercises 15.3-2
-***
-Draw the recursion tree for the MERGE-SORT procedure from Section 2.3.1 on an array of 16 elements. Explain why memoization is ineffective in speeding up a good divide-and- conquer algorithm such as MERGE-SORT.
-### `Answer`
-因为并没有重叠子问题,只能用并行去优化.
-
-### Exercises 15.3-3
-***
-Consider a variant of the matrix-chain multiplication problem in which the goal is to parenthesize the sequence of matrices so as to maximize, rather than minimize, the number of scalar multiplications. Does this problem exhibit optimal substructure?
### `Answer`
-是的.
-
-### Exercises 15.3-4
-***
+### Exercises 15.3-1
+***
+Which is a more efficient way to determine the optimal number of multiplications in a matrix- chain multiplication problem: enumerating all the ways of parenthesizing the product and computing the number of multiplications for each, or running RECURSIVE-MATRIX- CHAIN? Justify your answer.
+
+### `Answer`
+15.2节给出枚举方法的时间复杂度为
+)
+
+The following are copied from solutions made by others, sorry I do not have author's name/
+
+对于RECURSIVE-MATRIX- CHAIN
+
+
+
+
+
+### Exercises 15.3-2
+***
+Draw the recursion tree for the MERGE-SORT procedure from Section 2.3.1 on an array of 16 elements. Explain why memoization is ineffective in speeding up a good divide-and- conquer algorithm such as MERGE-SORT.
+
+### `Answer`
+因为并没有重叠子问题,只能用并行去优化.
+
+### Exercises 15.3-3
+***
+Consider a variant of the matrix-chain multiplication problem in which the goal is to parenthesize the sequence of matrices so as to maximize, rather than minimize, the number of scalar multiplications. Does this problem exhibit optimal substructure?
+
+### `Answer`
+是的.
+
+### Exercises 15.3-4
+***
Describe how assembly-line scheduling has overlapping subproblems.
-
-### `Answer`
-我们要求解到达S1,j最快路线,必须先知道到达S1,j-1和S2,j-1的最快路线.这就是重叠子问题.
-
-### Exercises 15.3-5
-***
-As stated, in dynamic programming we first solve the subproblems and then choose which of them to use in an optimal solution to the problem. Professor Capulet claims that it is not always necessary to solve all the subproblems in order to find an optimal solution. She suggests that an optimal solution to the matrix-chain multiplication problem can be found by always choosing the matrix Ak at which to split the subproduct Ai Ai+1 Aj (by selecting k to minimize the quantity pi-1 pk pj) before solving the subproblems. Find an instance of the matrix-chain multiplication problem for which this greedy approach yields a suboptimal solution.
### `Answer`
+
+### `Answer`
+我们要求解到达S1,j最快路线,必须先知道到达S1,j-1和S2,j-1的最快路线.这就是重叠子问题.
+
+### Exercises 15.3-5
+***
+As stated, in dynamic programming we first solve the subproblems and then choose which of them to use in an optimal solution to the problem. Professor Capulet claims that it is not always necessary to solve all the subproblems in order to find an optimal solution. She suggests that an optimal solution to the matrix-chain multiplication problem can be found by always choosing the matrix Ak at which to split the subproduct Ai Ai+1 Aj (by selecting k to minimize the quantity pi-1 pk pj) before solving the subproblems. Find an instance of the matrix-chain multiplication problem for which this greedy approach yields a suboptimal solution.
+
+### `Answer`
此处求解时用了贪心策略, 每次选取矩阵Ak分裂时,使得pi-1pkpi最小.
-
-### Exercises 15.3-6
-***
-Imagine that you wish to exchange one currency for another. You realize that
-instead of directly exchanging one currency for another, you might be better off
-making a series of trades through other currencies, winding up with the currency
-you want. Suppose that you can trade n different currencies, numbered 1,2, ... , n,
-where you start with currency 1 and wish to wind up with currency n. You are
-given, for each pair of currencies i and j , an exchange rate rij , meaning that if
-you start with d units of currency i , you can trade for drij units of currency j .
-A sequence of trades may entail a commission, which depends on the number of
-trades you make. Let ck be the commission that you are charged when you make k
-trades. Show that, if ck = 0 for all k = 1,2, ... , n, then the problem of finding the
-best sequence of exchanges from currency 1 to currency n exhibits optimal substructure.
-Then show that if commissions ck are arbitrary values, then the problem
-of finding the best sequence of exchanges from currency 1 to currency n does not
-necessarily exhibit optimal substructure.
-
-### `Answer`
-let v[1...n] be an array representing the best value of exchanged currency.
-Then v[i] = d, if i = 1
-and max(v[k] * r[k][i]) where 1 <= k < i, if i > 2
-
-if c[k] = 0, for all k = 1, 2 ... n
-As is shown in the recursion, the solution to the main problem combines the optimal solutions to subproblems. The solution of the main problem is also optimal. Therefore, the problem exhibits the optimal substructure.
-
-if c[k] is arbitrary, then the problem does not necessarily exhibit the optimal substructure because there is not guarantee that the subproblems give optimal solutions.
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### Exercises 15.3-6
+***
+Imagine that you wish to exchange one currency for another. You realize that
+instead of directly exchanging one currency for another, you might be better off
+making a series of trades through other currencies, winding up with the currency
+you want. Suppose that you can trade n different currencies, numbered 1,2, ... , n,
+where you start with currency 1 and wish to wind up with currency n. You are
+given, for each pair of currencies i and j , an exchange rate rij , meaning that if
+you start with d units of currency i , you can trade for drij units of currency j .
+A sequence of trades may entail a commission, which depends on the number of
+trades you make. Let ck be the commission that you are charged when you make k
+trades. Show that, if ck = 0 for all k = 1,2, ... , n, then the problem of finding the
+best sequence of exchanges from currency 1 to currency n exhibits optimal substructure.
+Then show that if commissions ck are arbitrary values, then the problem
+of finding the best sequence of exchanges from currency 1 to currency n does not
+necessarily exhibit optimal substructure.
+
+### `Answer`
+let v[1...n] be an array representing the best value of exchanged currency.
+Then v[i] = d, if i = 1
+and max(v[k] * r[k][i]) where 1 <= k < i, if i > 2
+
+if c[k] = 0, for all k = 1, 2 ... n
+As is shown in the recursion, the solution to the main problem combines the optimal solutions to subproblems. The solution of the main problem is also optimal. Therefore, the problem exhibits the optimal substructure.
+
+if c[k] is arbitrary, then the problem does not necessarily exhibit the optimal substructure because there is not guarantee that the subproblems give optimal solutions.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C15-Dynamic-Programming/15.5.md b/C15-Dynamic-Programming/15.5.md
index 8130fc14..68546d62 100644
--- a/C15-Dynamic-Programming/15.5.md
+++ b/C15-Dynamic-Programming/15.5.md
@@ -1,42 +1,59 @@
-### Exercises 15.5-1
-***
-
Write pseudocode for the procedure CONSTRUCT-OPTIMAL-BST(root) which, given the table root, outputs the structure of an optimal binary search tree. For the example in Figure 15.8, your procedure should print out the structure
-
* k2 is the root
* k1 is the left child of k2
* d0 is the left child of k1
* d1 is the right child of k1
* k5 is the right child of k2
* k4 is the left child of k5
* k3 is the left child of k4
* d2 is the left child of k3
* d3 is the right child of k3
* d4 is the right child of k4
* d5 is the right child of k5
-### `Answer`
-[implementation](./optimalBST.cpp)
-
-
-
-### Exercises 15.5-2
-***
-Determine the cost and structure of an optimal binary search tree for a set of n = 7 keys with the following probabilities:
-
-i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7
-:---:|:---:|:---:|:---:|:---:|:---:|:---:
-pi | | 0.04 | 0.06 | 0.08 | 0.02 | 0.10 | 0.12 | 0.14
-qi | 0.06 | 0.06 | 0.06 | 0.06 | 0.05 | 0.05 | 0.05 | 0.05
-### `Answer`
-run my [program](./optimalBST.cpp) you will get the answer.
-
-### Exercises 15.5-3
-***
-
Suppose that instead of maintaining the table w[i, j], we computed the value of w(i, j) directly from equation (15.17) in line 8 of OPTIMAL-BST and used this computed value in line 10. How would this change affect the asymptotic running time of OPTIMAL-BST?
-
-### `Answer`
-
-时间复杂度依旧是O(n^3).虽然原来的计算方法计算w只用了O(n^2),但算法有一个三重循环.
-
-### Exercises 15.5-4 *
-***
+### Exercises 15.5-1
+***
+
+Write pseudocode for the procedure CONSTRUCT-OPTIMAL-BST(root) which, given the table root, outputs the structure of an optimal binary search tree. For the example in Figure 15.8, your procedure should print out the structure
+
+
+* k2 is the root
+* k1 is the left child of k2
+* d0 is the left child of k1
+* d1 is the right child of k1
+* k5 is the right child of k2
+* k4 is the left child of k5
+* k3 is the left child of k4
+* d2 is the left child of k3
+* d3 is the right child of k3
+* d4 is the right child of k4
+* d5 is the right child of k5
+
+### `Answer`
+[implementation](./optimalBST.cpp)
+
+
+
+### Exercises 15.5-2
+***
+Determine the cost and structure of an optimal binary search tree for a set of n = 7 keys with the following probabilities:
+
+i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7
+:---:|:---:|:---:|:---:|:---:|:---:|:---:
+pi | | 0.04 | 0.06 | 0.08 | 0.02 | 0.10 | 0.12 | 0.14
+qi | 0.06 | 0.06 | 0.06 | 0.06 | 0.05 | 0.05 | 0.05 | 0.05
+
+### `Answer`
+run my [program](./optimalBST.cpp) you will get the answer.
+
+### Exercises 15.5-3
+***
+
+Suppose that instead of maintaining the table w[i, j], we computed the value of w(i, j) directly from equation (15.17) in line 8 of OPTIMAL-BST and used this computed value in line 10. How would this change affect the asymptotic running time of OPTIMAL-BST?
+
+### `Answer`
+
+时间复杂度依旧是O(n^3).虽然原来的计算方法计算w只用了O(n^2),但算法有一个三重循环.
+
+### Exercises 15.5-4 *
+***
Knuth [184] has shown that there are always roots of optimal subtrees such that root[i, j - 1] ≤ root[i, j] ≤ root[i + 1, j] for all 1 ≤ i < j ≤ n. Use this fact to modify the OPTIMAL-BST procedure to run in Θ(n2) time.
-
-### `Answer`
-第9行替换为:
-
- if i = j
- r <- j
- else
- for r <- root[i,j-1] to root[i+1,j]
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+第9行替换为:
+
+ if i = j
+ r <- j
+ else
+ for r <- root[i,j-1] to root[i+1,j]
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C16-Greedy-Algorithms/16.3.md b/C16-Greedy-Algorithms/16.3.md
index 8fb9eb69..298ebc5c 100644
--- a/C16-Greedy-Algorithms/16.3.md
+++ b/C16-Greedy-Algorithms/16.3.md
@@ -1,60 +1,63 @@
-### Exercises 16.3-1
-***
-Prove that a binary tree that is not full cannot correspond to an optimal prefix code.
-### `Answer`
-要达到最优前缀编码,必须考虑到前缀的每一种情况,故必须是满二叉树.
-
-### Exercises 16.3-2
-***
-What is an optimal Huffman code for the following set of frequencies, based on the first 8 Fibonacci numbers?
-
a:1 b:1 c:2 d:3 e:5 f:8 g:13 h:21
-
Can you generalize your answer to find the optimal code when the frequencies are the first n Fibonacci numbers?
-
-### `Answer`
-
-
-### Exercises 16.3-3
-***
+### Exercises 16.3-1
+***
+Prove that a binary tree that is not full cannot correspond to an optimal prefix code.
+
+### `Answer`
+要达到最优前缀编码,必须考虑到前缀的每一种情况,故必须是满二叉树.
+
+### Exercises 16.3-2
+***
+What is an optimal Huffman code for the following set of frequencies, based on the first 8 Fibonacci numbers?
+
+a:1 b:1 c:2 d:3 e:5 f:8 g:13 h:21
+
+Can you generalize your answer to find the optimal code when the frequencies are the first n Fibonacci numbers?
+
+### `Answer`
+
+
+### Exercises 16.3-3
+***
Prove that the total cost of a tree for a code can also be computed as the sum, over all internal nodes, of the combined frequencies of the two children of the node.
-
-### `Answer`
-straightforward
-
-### Exercises 16.3-4
-***
+
+### `Answer`
+straightforward
+
+### Exercises 16.3-4
+***
Prove that if we order the characters in an alphabet so that their frequencies are monotonically decreasing, then there exists an optimal code whose codeword lengths are monotonically increasing.
-
-### `Answer`
-straightforward
-
-### Exercises 16.3-5
-***
+
+### `Answer`
+straightforward
+
+### Exercises 16.3-5
+***
Suppose we have an optimal prefix code on a set C = {0, 1, ..., n - 1} of characters and we wish to transmit this code using as few bits as possible. Show how to represent any optimal prefix code on C using only 2n - 1 + n ⌈lg n⌉ bits. (Hint: Use 2n - 1 bits to specify the structure of the tree, as discovered by a walk of the tree.)
-
-### `Answer`
-用**2n-1**位表示树的结构,内部节点用1表示,叶子节点用0表示.用nlog(n)为表示字母序列,每个字母的二进制编码长度为log(n),总共需要nlog(n)位.
-
-### Exercises 16.3-6
-***
+
+### `Answer`
+用**2n-1**位表示树的结构,内部节点用1表示,叶子节点用0表示.用nlog(n)为表示字母序列,每个字母的二进制编码长度为log(n),总共需要nlog(n)位.
+
+### Exercises 16.3-6
+***
Generalize Huffman's algorithm to ternary codewords (i.e., codewords using the symbols 0, 1, and 2), and prove that it yields optimal ternary codes.
-
-### `Answer`
-那就推广到树的结点有三个孩子结点,证明过程同引理16.3的证明.
-
-### Exercises 16.3-7
-***
+
+### `Answer`
+那就推广到树的结点有三个孩子结点,证明过程同引理16.3的证明.
+
+### Exercises 16.3-7
+***
Suppose a data file contains a sequence of 8-bit characters such that all 256 characters are about as common: the maximum character frequency is less than twice the minimum character frequency. Prove that Huffman coding in this case is no more efficient than using an ordinary 8-bit fixed-length code.
-
-### `Answer`
-此时生成的Huffman树是一颗满二叉树,跟固定长度编码一致.
-
-### Exercises 16.3-8
-***
+
+### `Answer`
+此时生成的Huffman树是一颗满二叉树,跟固定长度编码一致.
+
+### Exercises 16.3-8
+***
Show that no compression scheme can expect to compress a file of randomly chosen 8-bit characters by even a single bit. (Hint: Compare the number of files with the number of possible encoded files.)
-
-### `Answer`
-Notice that the number of possible source files S using n bit and compressed files E using n bits is 2^**n+1** - 1. Since any compression algorithm must assign each element s ∈ S to a distinct element e ∈ E the algorithm cannot hope to actually compress the source file.
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+Notice that the number of possible source files S using n bit and compressed files E using n bits is 2^**n+1** - 1. Since any compression algorithm must assign each element s ∈ S to a distinct element e ∈ E the algorithm cannot hope to actually compress the source file.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C18-B-Trees/18.1.md b/C18-B-Trees/18.1.md
index f66c03bd..13c8bcda 100644
--- a/C18-B-Trees/18.1.md
+++ b/C18-B-Trees/18.1.md
@@ -1,50 +1,51 @@
-### Exercises 18.1-1
-***
-Why don't we allow a minimum degree of t = 1?
-### `Answer`
-According to the definition, minimum degree t means every node other than the root must have at least t – 1 keys, and every internal node other than the root thus has at least t children. So, when t = 1, it means every node other than the root must have
-at least t – 1 = 0 key, and every internal node other than the root thus has at least t = 1 child.
-
-Thus, we can see that the minimum case doesn't exist, because no node exists with 0 key, and no node exists with only 1 child
-in a B-tree.
-
-### Exercises 18.1-2
-***
+### Exercises 18.1-1
+***
+Why don't we allow a minimum degree of t = 1?
+
+### `Answer`
+According to the definition, minimum degree t means every node other than the root must have at least t – 1 keys, and every internal node other than the root thus has at least t children. So, when t = 1, it means every node other than the root must have
+at least t – 1 = 0 key, and every internal node other than the root thus has at least t = 1 child.
+
+Thus, we can see that the minimum case doesn't exist, because no node exists with 0 key, and no node exists with only 1 child
+in a B-tree.
+
+### Exercises 18.1-2
+***
For what values of t is the tree of Figure 18.1 a legal B-tree?
-
-### `Answer`
-According to property 5 of B-tree, every node other than the root must have at least t−1keys and may contain at most 2t−1 keys. In Figure 18.1, the number of keys of each node (except the root) is either 2 or 3. So to make it a legal B-tree, we need
-to guarantee that
-
-t – 1 ≤ 2 and 2 t – 1 ≥ 3,
-
-which yields 2 ≤ t ≤ 3. So t can be 2 or 3.
-
-### Exercises 18.1-3
-***
+
+### `Answer`
+According to property 5 of B-tree, every node other than the root must have at least t−1keys and may contain at most 2t−1 keys. In Figure 18.1, the number of keys of each node (except the root) is either 2 or 3. So to make it a legal B-tree, we need
+to guarantee that
+
+t – 1 ≤ 2 and 2 t – 1 ≥ 3,
+
+which yields 2 ≤ t ≤ 3. So t can be 2 or 3.
+
+### Exercises 18.1-3
+***
Show all legal B-trees of minimum degree 3 that represent {1, 2, 3, 4, 5}
-
-### `Answer`
-We know that every node except the root must have at least t – 1 = 2 keys, and at most 2t – 1 = 5 keys. Also remember that the leaves stay in the same depth. Thus, there are 2 possible legal B-trees:
-
-
-
-
-### Exercises 18.1-4
-***
+
+### `Answer`
+We know that every node except the root must have at least t – 1 = 2 keys, and at most 2t – 1 = 5 keys. Also remember that the leaves stay in the same depth. Thus, there are 2 possible legal B-trees:
+
+
+
+
+### Exercises 18.1-4
+***
As a function of the minimum degree t, what is the maximum number of keys that can be stored in a B-tree of height h?
-
-### `Answer`
-
-
-### Exercises 18.1-5
-***
+
+### `Answer`
+
+
+### Exercises 18.1-5
+***
Describe the data structure that would result if each black node in a red-black tree were to absorb its red children, incorporating their children with its own.
-
-### `Answer`
-After absorbing each red node into its black parent, each black node may contain 1, 2 (1 red child), or 3 (2 red children) keys, and all leaves of the resulting tree have the same depth, according to property 5 of red-black tree (For each node, all paths
-from the node to descendant leaves contain the same number of black nodes). Therefore, a red-black tree will become a Btree with minimum degree t = 2, i.e., a 2-3-4 tree.
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+After absorbing each red node into its black parent, each black node may contain 1, 2 (1 red child), or 3 (2 red children) keys, and all leaves of the resulting tree have the same depth, according to property 5 of red-black tree (For each node, all paths
+from the node to descendant leaves contain the same number of black nodes). Therefore, a red-black tree will become a Btree with minimum degree t = 2, i.e., a 2-3-4 tree.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C18-B-Trees/18.2.md b/C18-B-Trees/18.2.md
index 70586f31..491e9e98 100644
--- a/C18-B-Trees/18.2.md
+++ b/C18-B-Trees/18.2.md
@@ -1,81 +1,85 @@
-### Exercises 18.2-1
-***
-Show the results of inserting the keys
-
F, S, Q, K, C, L, H, T, V, W, M, R, N, P, A, B, X, Y, D, Z, E
-
in order into an empty B-tree with minimum degree 2. Only draw the configurations of the tree just before some node must split, and also draw the final configuration.
-### `Answer`
-
-
-### Exercises 18.2-2
-***
+### Exercises 18.2-1
+***
+Show the results of inserting the keys
+
+F, S, Q, K, C, L, H, T, V, W, M, R, N, P, A, B, X, Y, D, Z, E
+
+in order into an empty B-tree with minimum degree 2. Only draw the configurations of the tree just before some node must split, and also draw the final configuration.
+
+### `Answer`
+
+
+### Exercises 18.2-2
+***
Explain under what circumstances, if any, redundant DISK-READ or DISK-WRITE operations are performed during the course of executing a call to B-TREE-INSERT. (A redundant DISK-READ is a DISK-READ for a page that is already in memory. A redundant DISK-WRITE writes to disk a page of information that is identical to what is already stored there.)
-
-### `Answer`
-In order to insert the key into a full child node but without its parent being full, we need the following operations:
-
-* DISK-READ: Key placement
-* DISK-WRITE: Split nodes
-* DISK-READ: Get to the parent
-* DISK-WRITE: Fill parent
-
-If both were full, we'd have to do the same, but instead of the final step, repeat the above to split the parent node and write into the child nodes. With both considerations in mind, there should never be a redundant DISK-READ or DISK-WRITE on a B-TREE-INSERT.
-
-### Exercises 18.2-3
-***
+
+### `Answer`
+In order to insert the key into a full child node but without its parent being full, we need the following operations:
+
+* DISK-READ: Key placement
+* DISK-WRITE: Split nodes
+* DISK-READ: Get to the parent
+* DISK-WRITE: Fill parent
+
+If both were full, we'd have to do the same, but instead of the final step, repeat the above to split the parent node and write into the child nodes. With both considerations in mind, there should never be a redundant DISK-READ or DISK-WRITE on a B-TREE-INSERT.
+
+### Exercises 18.2-3
+***
Explain how to find the minimum key stored in a B-tree and how to find the predecessor of a given key stored in a B-tree.
-
-### `Answer`
-Finding the minimum in a B-tree is quite similar to finding a minimum in a binary search tree. We need to find the left most leaf for the given root, and return the first key.
-
-Finding the predecessor of a given key x.keyi is according to the following rules:
-
-* If x is not a leaf, return the maximum key in the i-th child of x, which is also the maximum key of the subtree rooted
-at x.ci
-* If x is a leaf and i > 1, return the (i–1)st key of x, i.e., x.keyi–1
-* Otherwise, look for the last node y (from the bottom up) and j > 0, such that x.keyi is the leftmost key in y.cj; if j = 1, return NIL since x.keyi is the minimum key in the tree; otherwise we return y.keyj–1.
-
-[implementation](./btree.cpp)
-
-### Exercises 18.2-4 *
-***
-Suppose that the keys {1, 2, ..., n} are inserted into an empty B-tree with minimum degree 2. How many nodes does the final B-tree have?
-### `Answer`
-I find the answer `n - 2lg(n+1)` in the Internet, but don't know why.
-
-n | node
-:----:|:----:
-1 | 1
-2 | 1
-3 | 1
-4 | 3
-5 | 3
-6 | 4
-7 | 4
-8 | 5
-9 | 7
-10 | 8
-
-### Exercises 18.2-5
-***
+
+### `Answer`
+Finding the minimum in a B-tree is quite similar to finding a minimum in a binary search tree. We need to find the left most leaf for the given root, and return the first key.
+
+Finding the predecessor of a given key x.keyi is according to the following rules:
+
+* If x is not a leaf, return the maximum key in the i-th child of x, which is also the maximum key of the subtree rooted
+at x.ci
+* If x is a leaf and i > 1, return the (i–1)st key of x, i.e., x.keyi–1
+* Otherwise, look for the last node y (from the bottom up) and j > 0, such that x.keyi is the leftmost key in y.cj; if j = 1, return NIL since x.keyi is the minimum key in the tree; otherwise we return y.keyj–1.
+
+[implementation](./btree.cpp)
+
+### Exercises 18.2-4 *
+***
+Suppose that the keys {1, 2, ..., n} are inserted into an empty B-tree with minimum degree 2. How many nodes does the final B-tree have?
+
+### `Answer`
+I find the answer `n - 2lg(n+1)` in the Internet, but don't know why.
+
+n | node
+:----:|:----:
+1 | 1
+2 | 1
+3 | 1
+4 | 3
+5 | 3
+6 | 4
+7 | 4
+8 | 5
+9 | 7
+10 | 8
+
+### Exercises 18.2-5
+***
Since leaf nodes require no pointers to children, they could conceivably use a different (larger) t value than internal nodes for the same disk page size. Show how to modify the procedures for creating and inserting into a B-tree to handle this variation.
-
-### `Answer`
-we could set the new t(name it t') value of leaf node = 1.5t.
-
-### Exercises 18.2-6
-***
+
+### `Answer`
+we could set the new t(name it t') value of leaf node = 1.5t.
+
+### Exercises 18.2-6
+***
Since leaf nodes require no pointers to children, they could conceivably use a different (larger) t value than internal nodes for the same disk page size. Show how to modify the procedures for creating and inserting into a B-tree to handle this variation.
-
-### `Answer`
-
-
-### Exercises 18.2-7
-***
+
+### `Answer`
+
+
+### Exercises 18.2-7
+***
Suppose that disk hardware allows us to choose the size of a disk page arbitrarily, but that the time it takes to read the disk page is a + bt, where a and b are specified constants and t is the minimum degree for a B-tree using pages of the selected size. Describe how to choose t so as to minimize (approximately) the B-tree search time. Suggest an optimal value of t for the case in which a = 5 milliseconds and b = 10 microseconds.
-
-### `Answer`
-Objective : minimize (5+10t)*tlog{t}{n}
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+Objective : minimize (5+10t)*tlog{t}{n}
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C18-B-Trees/18.3.md b/C18-B-Trees/18.3.md
index 01e68589..4a42211b 100644
--- a/C18-B-Trees/18.3.md
+++ b/C18-B-Trees/18.3.md
@@ -1,23 +1,24 @@
-### Exercises 18.3-1
-***
-Show the results of deleting C, P, and V , in order, from the tree of Figure 18.8(f).
-### `Answer`
- LPTX
- AEJK NO QRS UV YZ
-
- LQTX
- AEJK NO RS UV YZ
-
- LQX
- AEJK NO RSTU YZ
-
-### Exercises 18.3-2
-***
+### Exercises 18.3-1
+***
+Show the results of deleting C, P, and V , in order, from the tree of Figure 18.8(f).
+
+### `Answer`
+ LPTX
+ AEJK NO QRS UV YZ
+
+ LQTX
+ AEJK NO RS UV YZ
+
+ LQX
+ AEJK NO RSTU YZ
+
+### Exercises 18.3-2
+***
Write pseudocode for B-TREE-DELETE.
-
-### `Answer`
-[implementation](./btree.cpp)
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+[implementation](./btree.cpp)
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C19-Binomial-Heaps/19.1.md b/C19-Binomial-Heaps/19.1.md
index b1104db5..c700ac3f 100644
--- a/C19-Binomial-Heaps/19.1.md
+++ b/C19-Binomial-Heaps/19.1.md
@@ -1,24 +1,26 @@
-### Exercises 19.1-1
-***
-Suppose that x is a node in a binomial tree within a binomial heap, and assume that sibling[x] ≠ NIL. If x is not a root, how does degree[sibling[x]] compare to degree[x]? How about if x is a root?
-### `Answer`
-* If x is not a root, degree[sibling[x]] < degree[x]
-* If x is a root, degree[sibling[x]] > degree[x]
-
-### Exercises 19.1-2
-***
-If x is a nonroot node in a binomial tree within a binomial heap, how does degree[x] compare
to degree[p[x]]?
-
-### `Answer`
-degree[p[x]] > degree[x]
-
-### Exercises 19.1-3
-***
+### Exercises 19.1-1
+***
+Suppose that x is a node in a binomial tree within a binomial heap, and assume that sibling[x] ≠ NIL. If x is not a root, how does degree[sibling[x]] compare to degree[x]? How about if x is a root?
+
+### `Answer`
+* If x is not a root, degree[sibling[x]] < degree[x]
+* If x is a root, degree[sibling[x]] > degree[x]
+
+### Exercises 19.1-2
+***
+If x is a nonroot node in a binomial tree within a binomial heap, how does degree[x] compare
+to degree[p[x]]?
+
+### `Answer`
+degree[p[x]] > degree[x]
+
+### Exercises 19.1-3
+***
Suppose we label the nodes of binomial tree Bk in binary by a postorder walk, as in Figure 19.4. Consider a node x labeled l at depth i, and let j = k - i. Show that x has j 1's in its binary representation. How many binary k-strings are there that contain exactly j 1's? Show that the degree of x is equal to the number of 1's to the right of the rightmost 0 in the binary representation of l.
-
-### `Answer`
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C19-Binomial-Heaps/19.2.md b/C19-Binomial-Heaps/19.2.md
index 6b8236c1..b1d886ad 100644
--- a/C19-Binomial-Heaps/19.2.md
+++ b/C19-Binomial-Heaps/19.2.md
@@ -1,73 +1,83 @@
-### Exercises 19.2-1
-***
-Write pseudocode for BINOMIAL-HEAP-MERGE.
-### `Answer`
-[implementation](./BinomialHeap.h)
-
-### Exercises 19.2-2
-***
+### Exercises 19.2-1
+***
+Write pseudocode for BINOMIAL-HEAP-MERGE.
+
+### `Answer`
+[implementation](./BinomialHeap.h)
+
+### Exercises 19.2-2
+***
Show the binomial heap that results when a node with key 24 is inserted into the binomial heap shown in Figure 19.7(d).
-
-### `Answer`
-straightforward
-
-### Exercises 19.2-3
-***
+
+### `Answer`
+straightforward
+
+### Exercises 19.2-3
+***
Show the binomial heap that results when the node with key 28 is deleted from the binomial heap shown in Figure 19.8(c).
-
-### `Answer`
-straightforward
-
-### Exercises 19.2-4
-***
-Argue the correctness of BINOMIAL-HEAP-UNION using the following loop invariant:
At the start of each iteration of the while loop of lines 9-21, x points to a root that is one of the following:
-
1. the only root of its degree,
2. the first of the only two roots of its degree, or
3. the first or second of the only three roots of its degree.
Moreover, all roots preceding x's predecessor on the root list have unique degrees on the root list, and if x's predecessor has a degree different from that of x, its degree on the root list is unique, too. Finally, node degrees monotonically increase as we traverse the root list.
-
-### `Answer`
-straightforward
-
-### Exercises 19.2-5
-***
+
+### `Answer`
+straightforward
+
+### Exercises 19.2-4
+***
+Argue the correctness of BINOMIAL-HEAP-UNION using the following loop invariant:
+
+At the start of each iteration of the while loop of lines 9-21, x points to a root that is one of the following:
+
+1. the only root of its degree,
+2. the first of the only two roots of its degree, or
+3. the first or second of the only three roots of its degree.
+
+Moreover, all roots preceding x's predecessor on the root list have unique degrees on the root list, and if x's predecessor has a degree different from that of x, its degree on the root list is unique, too. Finally, node degrees monotonically increase as we traverse the root list.
+
+### `Answer`
+straightforward
+
+### Exercises 19.2-5
+***
Explain why the BINOMIAL-HEAP-MINIMUM procedure might not work correctly if keys can have the value ∞. Rewrite the pseudocode to make it work correctly in such cases.
-
-### `Answer`
-If keys can have the value ∞, then the initial value of min can not compare with that.
-
-So we could set min to the first value of binomial heap by default.
-
-### Exercises 19.2-6
-***
+
+### `Answer`
+If keys can have the value ∞, then the initial value of min can not compare with that.
+
+So we could set min to the first value of binomial heap by default.
+
+### Exercises 19.2-6
+***
Suppose there is no way to represent the key -∞. Rewrite the BINOMIAL-HEAP-DELETE procedure to work correctly in this situation. It should still take O(lg n) time.
-
-### `Answer`
-
-### Exercises 19.2-7
-***
+
+### `Answer`
+
+### Exercises 19.2-7
+***
Discuss the relationship between inserting into a binomial heap and incrementing a binary number and the relationship between uniting two binomial heaps and adding two binary numbers.
-
-### `Answer`
-It's similar, first we add one '1', if the original number in the position is '1' too, then we carry '1' to preceeding bit.
-
-### Exercises 19.2-8
-***
In light of Exercise 19.2-7, rewrite BINOMIAL-HEAP-INSERT to insert a node directly into a binomial heap without calling BINOMIAL-HEAP-UNION.
-
-### `Answer`
-straightforward.
-
-just do "addtion"
-
-### Exercises 19.2-9
-***
Show that if root lists are kept in strictly decreasing order by degree (instead of strictly increasing order), each of the binomial heap operations can be implemented without changing its asymptotic running time.
-
-### `Answer`
-
-### Exercises 19.2-10
-***
+
+### `Answer`
+It's similar, first we add one '1', if the original number in the position is '1' too, then we carry '1' to preceeding bit.
+
+### Exercises 19.2-8
+***
+In light of Exercise 19.2-7, rewrite BINOMIAL-HEAP-INSERT to insert a node directly into a binomial heap without calling BINOMIAL-HEAP-UNION.
+
+### `Answer`
+straightforward.
+
+just do "addtion"
+
+### Exercises 19.2-9
+***
+Show that if root lists are kept in strictly decreasing order by degree (instead of strictly increasing order), each of the binomial heap operations can be implemented without changing its asymptotic running time.
+
+### `Answer`
+
+### Exercises 19.2-10
+***
Find inputs that cause BINOMIAL-HEAP-EXTRACT-MIN, BINOMIAL-HEAP- DECREASE-KEY, and BINOMIAL-HEAP-DELETE to run in Ω(lg n) time. Explain why the worst-case running times of BINOMIAL-HEAP-INSERT, BINOMIAL-HEAP-MINIMUM, and BINOMIAL-HEAP-UNION are  but not Ω(lg n). (See Problem 3-5.)
-
-### `Answer`
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C21-Data-Structures-for-Disjoint-Sets/21.2.md b/C21-Data-Structures-for-Disjoint-Sets/21.2.md
index 25a6653e..3d1cc006 100644
--- a/C21-Data-Structures-for-Disjoint-Sets/21.2.md
+++ b/C21-Data-Structures-for-Disjoint-Sets/21.2.md
@@ -1,64 +1,68 @@
-### Exercises 21.2-1
-***
-Write pseudocode for MAKE-SET, FIND-SET, and UNION using the linked-list representation and the weighted-union heuristic. Assume that each object x has an attribute rep[x] pointing to the representative of the set containing x and that each set S has attributes head[S], tail[S], and size[S] (which equals the length of the list).
-### `Answer`
-
- MAKE-SET(x):
- Initialize a new linked list
- Insert node x
-
- FIND-SET(x):
- return rep[x]
-
- UNION(x, y):
- Let smallist,biglist be the list with less and larger list according to size[x],size[y]
- put smallist to the tail in biglist
-
-### Exercises 21.2-2
-***
Show the data structure that results and the answers returned by the FIND-SET operations in the following program. Use the linked-list representation with the weighted-union heuristic.
-
for i <- 1 to 16
- do MAKE-SET(x_i)
- for i <- 1 to 15 by 2
- do UNION(x_i,x_i+1)
- for i <- 1 to 13 by 4
- do UNION(x_i, x_i+2)
- UNION(x1,x5)
- UNION(x11,x13)
- UNION(x1,x_10)
- FIND-SET(x2)
- FIND-SET(x9)
-
+### Exercises 21.2-1
+***
+Write pseudocode for MAKE-SET, FIND-SET, and UNION using the linked-list representation and the weighted-union heuristic. Assume that each object x has an attribute rep[x] pointing to the representative of the set containing x and that each set S has attributes head[S], tail[S], and size[S] (which equals the length of the list).
+
+### `Answer`
+
+ MAKE-SET(x):
+ Initialize a new linked list
+ Insert node x
+
+ FIND-SET(x):
+ return rep[x]
+
+ UNION(x, y):
+ Let smallist,biglist be the list with less and larger list according to size[x],size[y]
+ put smallist to the tail in biglist
+
+### Exercises 21.2-2
+***
+Show the data structure that results and the answers returned by the FIND-SET operations in the following program. Use the linked-list representation with the weighted-union heuristic.
+
+ for i <- 1 to 16
+ do MAKE-SET(x_i)
+ for i <- 1 to 15 by 2
+ do UNION(x_i,x_i+1)
+ for i <- 1 to 13 by 4
+ do UNION(x_i, x_i+2)
+ UNION(x1,x5)
+ UNION(x11,x13)
+ UNION(x1,x_10)
+ FIND-SET(x2)
+ FIND-SET(x9)
+
Assume that if the sets containing xi and xj have the same size, then the operation UNION(xi, xj) appends xj's list onto xi's list.
-
-### `Answer`
-All x are in the same set, all return 1.
-
-### Exercises 21.2-3
-***
+
+### `Answer`
+All x are in the same set, all return 1.
+
+### Exercises 21.2-3
+***
Adapt the aggregate proof of Theorem 21.1 to obtain amortized time bounds of O(1) for MAKE-SET and FIND-SET and O(lg n) for UNION using the linked-list representation and the weighted-union heuristic.
-
-### `Answer`
-MAKE-SET and FIND-SET can do in O(1) time, because MAKE-SET just initialize a new linked list and FIND-SET just return the representative of a linked list.
-
-Theorem 21.1 said it took O(nlogn) time to update n objects, so in average take O(logn) time.
-
-### Exercises 21.2-4
-***
+
+### `Answer`
+MAKE-SET and FIND-SET can do in O(1) time, because MAKE-SET just initialize a new linked list and FIND-SET just return the representative of a linked list.
+
+Theorem 21.1 said it took O(nlogn) time to update n objects, so in average take O(logn) time.
+
+### Exercises 21.2-4
+***
Give a tight asymptotic bound on the running time of the sequence of operations in Figure 21.3 assuming the linked-list representation and the weighted-union heuristic.
-
-### `Answer`
-T = O(n) + O(n) = O(n)
-
-This example is the best case, because in each UNION, we only move one element.
-
-### Exercises 21.2-5
-***
Suggest a simple change to the UNION procedure for the linked-list representation that removes the need to keep the tail pointer to the last object in each list. Whether or not the weighted-union heuristic is used, your change should not change the asymptotic running time of the UNION procedure. (Hint: Rather than appending one list to another, splice them together.)
-
-### `Answer`
-Actually, I don't the meaning of doing such modifications...
-
-If you have ideas, please merge it to me.
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+### `Answer`
+T = O(n) + O(n) = O(n)
+
+This example is the best case, because in each UNION, we only move one element.
+
+### Exercises 21.2-5
+***
+Suggest a simple change to the UNION procedure for the linked-list representation that removes the need to keep the tail pointer to the last object in each list. Whether or not the weighted-union heuristic is used, your change should not change the asymptotic running time of the UNION procedure. (Hint: Rather than appending one list to another, splice them together.)
+
+### `Answer`
+Actually, I don't the meaning of doing such modifications...
+
+If you have ideas, please merge it to me.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C21-Data-Structures-for-Disjoint-Sets/21.3.md b/C21-Data-Structures-for-Disjoint-Sets/21.3.md
index 79e60b37..df0fd66a 100644
--- a/C21-Data-Structures-for-Disjoint-Sets/21.3.md
+++ b/C21-Data-Structures-for-Disjoint-Sets/21.3.md
@@ -1,46 +1,48 @@
-### Exercises 21.3-1
-***
-Do Exercise 21.2-2 using a disjoint-set forest with union by rank and path compression.
-### `Answer`
-
-
- 1
-
- / | \ \
- 2 3 5 9
-
- | / \ / / \
- 4 6 7 10 11 13
-
- | | / \
- 8 12 14 15
-
- |
- 16
-
-
-### Exercises 21.3-2
-***
Write a nonrecursive version of FIND-SET with path compression.
-
-### `Answer`
-[implementation](./uf.cpp)
-
-### Exercises 21.3-3
-***
+### Exercises 21.3-1
+***
+Do Exercise 21.2-2 using a disjoint-set forest with union by rank and path compression.
+
+### `Answer`
+
+
+ 1
+
+ / | \ \
+ 2 3 5 9
+
+ | / \ / / \
+ 4 6 7 10 11 13
+
+ | | / \
+ 8 12 14 15
+
+ |
+ 16
+
+
+### Exercises 21.3-2
+***
+Write a nonrecursive version of FIND-SET with path compression.
+
+### `Answer`
+[implementation](./uf.cpp)
+
+### Exercises 21.3-3
+***
Give a sequence of m MAKE-SET, UNION, and FIND-SET operations, n of which are MAKE-SET operations, that takes Ω(m lg n) time when we use union by rank only.
-
-### `Answer`
-[reference](http://www.cs.toronto.edu/~avner/teaching/263/A/4sol.pdf)
-
-
-
-### Exercises 21.3-4 *
-***
+
+### `Answer`
+[reference](http://www.cs.toronto.edu/~avner/teaching/263/A/4sol.pdf)
+
+
+
+### Exercises 21.3-4 *
+***
Show that any sequence of m MAKE-SET, FIND-SET, and LINK operations, where all the LINK operations appear before any of the FIND-SET operations, takes only O(m) time if both path compression and union by rank are used. What happens in the same situation if only the path-compression heuristic is used?
-
-### `Answer`
-UNSOLVED
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### `Answer`
+UNSOLVED
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C22-Elementary-Graph-Algorithms/22.2.md b/C22-Elementary-Graph-Algorithms/22.2.md
index df915176..17ad22b7 100644
--- a/C22-Elementary-Graph-Algorithms/22.2.md
+++ b/C22-Elementary-Graph-Algorithms/22.2.md
@@ -1,86 +1,111 @@
-### Exercises 22.2-1
-***
-Show the d and π values that result from running breadth-first search on the directed graph of Figure 22.2(a), using vertex 3 as the source.
-### `Answer`
-
-
-### Exercises 22.2-2
-***
-Show the d and π values that result from running breadth-first search on the undirected graph
of Figure 22.3, using vertex u as the source.
-
-### `Answer`
-
-
-### Exercises 22.2-3
-***
-What is the running time of BFS if its input graph is represented by an adjacency matrix and the algorithm is modified to handle this form of input?
-
-### `Answer`
+### Exercises 22.2-1
+***
+Show the d and π values that result from running breadth-first search on the directed graph of Figure 22.2(a), using vertex 3 as the source.
+
+
+### `Answer`
+
+
+### Exercises 22.2-2
+***
+Show the d and π values that result from running breadth-first search on the undirected graph
+of Figure 22.3, using vertex u as the source.
+
+### `Answer`
+
+
+### Exercises 22.2-3
+***
+What is the running time of BFS if its input graph is represented by an adjacency matrix and the algorithm is modified to handle this form of input?
+
+
+### `Answer`
用邻接矩阵表示的话,遍历所有的边的时间由O(E)变为O(V^2),因此总运行时间是O(V+V^2)
-
-If the graph is represented by adjancency matrix, then the time of iterating all the edge becomes O(V^2), so the running time is O(V+V^2).
-
-### Exercises 22.2-4
-***
-Argue that in a breadth-first search, the value d[u] assigned to a vertex u is independent of the order in which the vertices in each adjacency list are given. Using Figure 22.3 as an example, show that the breadth-first tree computed by BFS can depend on the ordering within adjacency lists.
-
-### `Answer`
-这些结论很明显,d[u]是最短路径的大小自然和顺序无关,而最短的路径可以有很多条自然和顺序有关.
-
-It's obvious, d[u] represents the distance, so it is of course has nothing to do with order. But the shortest path may be not unique, so it is relevant to order.
-
-
-### Exercises 22.2-5
-***
-Give an example of a directed graph G = (V, E), a source vertex s in V , and a set of tree edges Eπ in E such that for each vertex v in V,the unique path in the graph(V,Eπ) from s to v is a shortest path in G, yet the set of edges Eπ cannot be produced by running BFS on G, no matter how the vertices are ordered in each adjacency list.
-
### `Answer`
-Following is the example, the bold edges are in Eπ. Then can not be produced by BFS.
-
-
-
-### Exercises 22.2-6
-***
-There are two types of professional wrestlers: "good guys" and "bad guys." Between any pair of professional wrestlers, there may or may not be a rivalry. Suppose we have n professional wrestlers and we have a list of r pairs of wrestlers for which there are rivalries. Give an O(n + r)-time algorithm that determines whether it is possible to designate some of the wrestlers as good guys and the remainder as bad guys such that each rivalry is between a good guy and a bad guy. If is it possible to perform such a designation, your algorithm should produce it.
-
-### `Answer`
-Bipartite Graph problem.
-
-Run DFS or BFS, the start node we could mark as white. Each time, we encounter a node, if it is not currently colored, we should mark it as the opposite color of current node. Else, check the color with current node. If same, then it is not bipartite graph.
-
-
-### Exercises 22.2-7
-***
-The **diameter** of a tree T =(V, E) is given by
-
- max d(u,v)
that is, the diameter is the largest of all shortest-path distances in the tree. Give an efficient algorithm to compute the diameter of a tree, and analyze the running time of your algorithm.
-
### `Answer`
-
-#####Solution 1 :
-
-For all node v, run BFS each, choose the longest shortest path. Or use floyd algorithm to calculate all p-p shortest path.
BFS running time = O(V*(V+E))
floyd running time = O(V^3)
-
-
-
#####Solution 2:
Run BFS twice. For the first time, arbitrarily choose a vertex as the source. The second time, let the vertex with largest d[] be the source.
-
-
#####Solution 3:
-
-The diameter of a tree can computed in a bottom-up fashion using a recursive solution. If x is a node with a depth d(x) in the tree then the diameter D(x) must be:
D(x) = max{maxi{D(x.childi)}, maxij{d(x.childi) + d(x.childj)} + 2}, if x is an internal node
0 , if x is a leaf
Since the diameter must be in one of the subtrees or pass through the root and the longest path from the root must be the depth. The depth can easily be computed at the same time. Using dynamic programming we obtain a linear solution.
+
+If the graph is represented by adjancency matrix, then the time of iterating all the edge becomes O(V^2), so the running time is O(V+V^2).
+
+### Exercises 22.2-4
+***
+Argue that in a breadth-first search, the value d[u] assigned to a vertex u is independent of the order in which the vertices in each adjacency list are given. Using Figure 22.3 as an example, show that the breadth-first tree computed by BFS can depend on the ordering within adjacency lists.
+
+
+### `Answer`
+这些结论很明显,d[u]是最短路径的大小自然和顺序无关,而最短的路径可以有很多条自然和顺序有关.
+
+It's obvious, d[u] represents the distance, so it is of course has nothing to do with order. But the shortest path may be not unique, so it is relevant to order.
+
+
+### Exercises 22.2-5
+***
+Give an example of a directed graph G = (V, E), a source vertex s in V , and a set of tree edges Eπ in E such that for each vertex v in V,the unique path in the graph(V,Eπ) from s to v is a shortest path in G, yet the set of edges Eπ cannot be produced by running BFS on G, no matter how the vertices are ordered in each adjacency list.
+
+
+### `Answer`
+Following is the example, the bold edges are in Eπ. Then can not be produced by BFS.
+
+
+
+### Exercises 22.2-6
+***
+There are two types of professional wrestlers: "good guys" and "bad guys." Between any pair of professional wrestlers, there may or may not be a rivalry. Suppose we have n professional wrestlers and we have a list of r pairs of wrestlers for which there are rivalries. Give an O(n + r)-time algorithm that determines whether it is possible to designate some of the wrestlers as good guys and the remainder as bad guys such that each rivalry is between a good guy and a bad guy. If is it possible to perform such a designation, your algorithm should produce it.
+
+### `Answer`
+Bipartite Graph problem.
+
+Run DFS or BFS, the start node we could mark as white. Each time, we encounter a node, if it is not currently colored, we should mark it as the opposite color of current node. Else, check the color with current node. If same, then it is not bipartite graph.
+
+
+### Exercises 22.2-7
+***
+The **diameter** of a tree T =(V, E) is given by
+
+ max d(u,v)
+that is, the diameter is the largest of all shortest-path distances in the tree. Give an efficient algorithm to compute the diameter of a tree, and analyze the running time of your algorithm.
+
+### `Answer`
+
+##### Solution 1 :
+
+For all node v, run BFS each, choose the longest shortest path. Or use floyd algorithm to calculate all p-p shortest path.
+
+BFS running time = O(V*(V+E))
+
+floyd running time = O(V^3)
+
+
+
+##### Solution 2:
+
+Run BFS twice. For the first time, arbitrarily choose a vertex as the source. The second time, let the vertex with largest d[] be the source.
+
+
+
+##### Solution 3:
+
+The diameter of a tree can computed in a bottom-up fashion using a recursive solution. If x is a node with a depth d(x) in the tree then the diameter D(x) must be:
+
+ D(x) = max{maxi{D(x.childi)}, maxij{d(x.childi) + d(x.childj)} + 2}, if x is an internal node
+ 0 , if x is a leaf
+Since the diameter must be in one of the subtrees or pass through the root and the longest path from the root must be the depth. The depth can easily be computed at the same time. Using dynamic programming we obtain a linear solution.
+
Actually, the problem can also be solved by computing the longest shortest path from an arbi- trary node. The node farthest away will be the endpoint of a diameter and we can thus compute the longest shortest path from this node to obtain the diameter. See relevant litterature for a proof of this.
-
### Exercises 22.2-8
-***
-Let G = (V, E) be a connected, undirected graph. Give an O(V + E)-time algorithm to compute a path in G that traverses each edge in E exactly once in each direction. Describe how you can find your way out of a maze if you are given a large supply of pennies.
-
-### `Answer`
-Euler path problem.
-
-**欧拉路径**:图中经过每条边一次且仅一次的路径;
-
- You can reference [here](https://github.com/gzc/sgu/blob/master/100-199/101.cpp)
-
-一个无向图如果有一个欧拉路径,需要满足几个条件: 它的奇数度节点数要么是0要么是2(此时这两个点只能作为欧拉路径的起点和终点)
-
-If an underected graph has an Euler path, it must satisfy : its odd dgree node is either 0 or 2.(Under such circumstance, the odd degree are start node and end node).
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+
+
+### Exercises 22.2-8
+***
+Let G = (V, E) be a connected, undirected graph. Give an O(V + E)-time algorithm to compute a path in G that traverses each edge in E exactly once in each direction. Describe how you can find your way out of a maze if you are given a large supply of pennies.
+
+### `Answer`
+Euler path problem.
+
+**欧拉路径**:图中经过每条边一次且仅一次的路径;
+
+ You can reference [here](https://github.com/gzc/sgu/blob/master/100-199/101.cpp)
+
+一个无向图如果有一个欧拉路径,需要满足几个条件: 它的奇数度节点数要么是0要么是2(此时这两个点只能作为欧拉路径的起点和终点)
+
+If an underected graph has an Euler path, it must satisfy : its odd dgree node is either 0 or 2.(Under such circumstance, the odd degree are start node and end node).
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C23-Minimum-Spanning-Trees/23.1.md b/C23-Minimum-Spanning-Trees/23.1.md
index 7ef72a76..4f095532 100644
--- a/C23-Minimum-Spanning-Trees/23.1.md
+++ b/C23-Minimum-Spanning-Trees/23.1.md
@@ -1,130 +1,141 @@
-### Exercises 23.1-1
-***
-Let (u, v) be a minimum-weight edge in a graph G. Show that (u, v) belongs to some
minimum spanning tree of G.
-### `Answer`
-过程GENERIC-MST的第一步.我们可以选择这样一条割,u在割的一边,v在另一边.此时,u-v就是一条通过割的轻边,把它加进来是安全的.
-
-In the first step of GENERIC-MST, we could choose such a cut, node u is on one side, node v is on another side. Then(u, v) is a light-edge through this cut. So, it is safe to add (u, v)
-
-### Exercises 23.1-2
-***
+### Exercises 23.1-1
+***
+Let (u, v) be a minimum-weight edge in a graph G. Show that (u, v) belongs to some
+minimum spanning tree of G.
+
+### `Answer`
+过程GENERIC-MST的第一步.我们可以选择这样一条割,u在割的一边,v在另一边.此时,u-v就是一条通过割的轻边,把它加进来是安全的.
+
+In the first step of GENERIC-MST, we could choose such a cut, node u is on one side, node v is on another side. Then(u, v) is a light-edge through this cut. So, it is safe to add (u, v)
+
+### Exercises 23.1-2
+***
Professor Sabatier conjectures the following converse of Theorem 23.1. Let G = (V, E) be a connected, undirected graph with a real-valued weight function w defined on E. Let A be a subset of E that is included in some minimum spanning tree for G, let (S, V - S) be any cut of G that respects A, and let (u, v) be a safe edge for A crossing (S, V - S). Then, (u, v) is a light edge for the cut. Show that the professor's conjecture is incorrect by giving a counterexample.
-
-### `Answer`
-
-
-对于该 cut 来说, 虽然 (A, C) 是安全的, 但不是最轻边.
-
-For this cut, although (A, C) is safe, but is it not the lightest.
-
-### Exercises 23.1-3
-***
-Show that if an edge (u, v) is contained in some minimum spanning tree, then it is a light edge crossing some cut of the graph.
-### `Answer`
-
-在这个MST里边,我们先去掉u-v这条边.然后画一个只穿过u-v的割(这个割肯定存在).此时,我们的策略是选择一条轻边,既然u-v之前在这个MST里边,那么u-v就是一条轻边.
-
-In this MST, we remove (u,v) and draw a cut cross (u,v). Now, our strategy is choose a light-weight edge, because (u,v) is in this MST originally, then (u,v) is a light edge.
-
-### Exercises 23.1-4
-***
+
+### `Answer`
+
+
+对于该 cut 来说, 虽然 (A, C) 是安全的, 但不是最轻边.
+
+For this cut, although (A, C) is safe, but is it not the lightest.
+
+### Exercises 23.1-3
+***
+Show that if an edge (u, v) is contained in some minimum spanning tree, then it is a light edge crossing some cut of the graph.
+
+### `Answer`
+
+在这个MST里边,我们先去掉u-v这条边.然后画一个只穿过u-v的割(这个割肯定存在).此时,我们的策略是选择一条轻边,既然u-v之前在这个MST里边,那么u-v就是一条轻边.
+
+In this MST, we remove (u,v) and draw a cut cross (u,v). Now, our strategy is choose a light-weight edge, because (u,v) is in this MST originally, then (u,v) is a light edge.
+
+### Exercises 23.1-4
+***
Give a simple example of a graph such that the set of edges {(u, v) : there exists a cut (S, V - S) such that (u, v) is a light edge crossing (S, V - S)} does not form a minimum spanning tree.
-
-### `Answer`
-当三角形三条边权重相同时,每条边在某种 cut 中均是最轻,即结果中存在环,所以不是最小生成树.
-
-For example, if we have a triangle with equal weight. In each cut, there will be two equal edge e1 and e2. If we choose e1 into MST, though e2 is also a light weight but it is not in the MST.
-
-### Exercises 23.1-5
-***
-Let e be a maximum-weight edge on some cycle of G = (V, E). Prove that there is a minimum spanning tree of G′ = (V, E -{e}) that is also a minimum spanning tree of G. That is, there is a minimum spanning tree of G that does not include e.
### `Answer`
-因为e是该回路上的最大权边,因此选择这个回路上的其他边都优于选择e.所以G′和G肯定会有一个不含e的MST.
-
-Becase e is the weightest edge in this circle. So other edges in the circle are all better than e. As a result, G and G' must have a MST not containging e.
-
-### Exercises 23.1-6
-***
+
+### `Answer`
+当三角形三条边权重相同时,每条边在某种 cut 中均是最轻,即结果中存在环,所以不是最小生成树.
+
+For example, if we have a triangle with equal weight. In each cut, there will be two equal edge e1 and e2. If we choose e1 into MST, though e2 is also a light weight but it is not in the MST.
+
+### Exercises 23.1-5
+***
+Let e be a maximum-weight edge on some cycle of G = (V, E). Prove that there is a minimum spanning tree of G′ = (V, E -{e}) that is also a minimum spanning tree of G. That is, there is a minimum spanning tree of G that does not include e.
+
+### `Answer`
+因为e是该回路上的最大权边,因此选择这个回路上的其他边都优于选择e.所以G′和G肯定会有一个不含e的MST.
+
+Becase e is the weightest edge in this circle. So other edges in the circle are all better than e. As a result, G and G' must have a MST not containging e.
+
+### Exercises 23.1-6
+***
Show that a graph has a unique minimum spanning tree if, for every cut of the graph, there is a unique light edge crossing the cut. Show that the converse is not true by giving a counterexample.
-
-### `Answer`
-假设存在两个最小生成树 T 和 T'. 对任意一条边 e 属于 T, 如果从 T 中移除 e, 则 T 变得不连通, 形成 cut (S, V - S), 根据练习 23.1-3 可知, e 是穿过 cut(S, V - S) 最轻边. 假设边 x 属于 T', 并穿过 cut (S, V - S), 则 x 同样是最轻边. 由于穿过 cut(S, V - S) 的最轻边唯一. 既 e 和 x 是同一条边. 所以 e 也属于 T', 由于我们选择 e 是任意的, 所有在 T 中的边, 同样在 T' 中. 即最小生成树唯一.
-
-Assuming there are two MSTs called T and T'. For any edge e in T, if we refove e from T, then T becomes unconnected and we have a cut(S, V - S). According to exercise 23.1-3, e is the light edge through cut(S, V - S). If edge x is in T' and through cut(S, V - S), then x is also a light weight. Because the light edge is unique. So e and x is the same edge, e is also in T'. Because we choose e at random, of all edges in T, also in T'. As a result, the MST is unique.
-
-将条件和结论调换则不成立, 如下.
-
-If inverse, then does not hold. See the picture.
-
-
-
-### Exercises 23.1-7
-***
-Argue that if all edge weights of a graph are positive, then any subset of edges that connects all vertices and has minimum total weight must be a tree. Give an example to show that the same conclusion does not follow if we allow some weights to be nonpositive.
-
-### `Answer`
-假设边的子集 T 中存在环, 则某两点之间存在多条通路, 移除其中一条通路, 子集 A' 仍然连通所有点. 因为边的权重为正, 既 w(A') < w(A), 结论与条件矛盾, 所以 T 是树.
-
-Assuming any subset of edges contain circles, then there must be points u,v, the path from u to v is not unique. If we remove a path, subset A' also connects all the points. Because the weight is positive, w(A') < w(A). There is a confliction, because we can produce smaller graph. So no circles, it must be a tree.
-
-如果边的权重准许为负, 则子集 T 不一定是树, 图中三条边总权重最小, 如下.
-
-If some weights could be nonpositive, see picture below. It is a graph with total minimum weights.
-
-
### Exercises 23.1-8
-***
Let T be a minimum spanning tree of a graph G, and let L be the sorted list of the edge weights of T. Show that for any other minimum spanning tree T′ of G, the list L is also the sorted list of edge weights of T′.
### `Answer`
-假设最小生成树有 n 条边, 存在两个最小生成树 T 和 T', 用 w(e) 表示边的权值.
-T 权值递增排列 w(a1) <= w(a2) <= ... w(an)
-T' 权值递增排列 w(b1) <= w(b2) <= ... w(bn)
-假设 i 是两个列表中, 第一次出现边不同的位置, 既 ai ≠ bi, 先假定 w(ai) >= w(bi).
-
-情况1, 如果 T 中含有边 bi, 由于 ai 和 bi 在列表 i 位置之前都是相同的, 若含有 bi 则一定在 i 位置后, 既有 j > i 使得 w(aj) = w(bi). 得到 w(bi) = w(aj) >= w(ai) >= w(bi), 既 w(bi) = w(aj) = w(ai), 故 i 位置处边的权值相同.
-
-情况2, 如果 T 不包含边 bi, 则把 bi 加到 T 中, 会在某处形成一个圈. 由于 T 是最小生成树, 圈内任何一条边的权值都小于等于 w(bi), 另外这个圈中必定存在 aj 不在 T' 中, 得出 w(aj) <= w(bi) 且 j > i. 因此 w(bi) <= w(ai) <= w(aj) <= w(bi), 既 w(bi) = w(aj) = w(ai), 故 i 位置处边的权值仍相同.
-
-Assuming MST contains n edges, there existing two MST T and T', w(e) stand for the weight of edge e.
-For T w(a1) <= w(a2) <= ... w(an)
-For T' w(b1) <= w(b2) <= ... w(bn)
-Also assuming i is the first occuring index where ai ≠ bi, let's assume w(ai) >= w(bi).
-
-**Condition 1** : If bi is in T, because the preceeding edges befor ai and bi are same, if T containing bi then bi must after ai. So there existing j > i, w(aj) = w(bi). Which produce w(bi) = w(aj) >= w(ai) >= w(bi). So w(ai) = w(bi).
-
-**Condition 2** : If bi is not in T, then adding bi to T will produce a circle. Because T is MST, any weights of nodes in this circle will be less or equal than w(bi). Besides, in this circles, there must exiting aj which not in T' and have w(aj) <= w(bi), j > i.
-So, w(bi) <= w(ai) <= w(aj) <= w(bi), w(bi) = w(aj) = w(ai).
-
-### Exercises 23.1-9
-***
-Let T be a minimum spanning tree of a graph G = (V, E), and let V′ be a subset of V. Let T′ be the subgraph of T induced by V′, and let G′ be the subgraph of G induced by V′. Show that if T′ is connected, then T′ is a minimum spanning tree of G′.
-
-### `Answer`
-用 cut (V', V - V') 分割图 G, 该 cut 一定不影响 T', 且 T' 是 T 的子集, 所以 T' 对于 G' 是安全的. 如果 T' 是连通的, 则 T' 一定是 G' 的最小生成树.
-
-We use cut(V', V - V') to cut graph. This cut will not influence T' and T' is the subset of T, so to G', T' is safe. if T′ is connected, then T′ is a minimum spanning tree of G.
-
-### Exercises 23.1-10
-***
-Given a graph G and a minimum spanning tree T , suppose that we decrease the weight of one of the edges in T . Show that T is still a minimum spanning tree for G. More formally, let T be a minimum spanning tree for G with edge weights given by weight function w. Choose one edge (x, y) ∈ T and a positive number k, and define the weight function w' by
-
-
-
-Show that T is a minimum spanning tree for G with edge weights given by w′.
-
-### `Answer`
-We prove by cut. Originally, (x,y) is the light edge in a certain cut(V1, V2). Decreasing the weight of (x,y), (x,y) is still a light edge. So T is a minimum spanning tree for G with edge weights given by w′.
-
-### Exercises 23.1-11 *
-Given a graph G and a minimum spanning tree T , suppose that we decrease the weight of one of the edges not in T . Give an algorithm for finding the minimum spanning tree in the modified graph.
-
-### `Answer`
-假设 (u, v) 不在最小生成树 T 中, 减小 (u, v) 权值后, 形成新的最小生成树 T'. 可能的情况是 T' 包含 (u, v) 或者 T' = T 保持不变. 算法只需寻找 T 中 u -> v 路径中权值最重边 x, 如果该边权值大于 (u, v), 则 T' = T - x + (u, v). 如果 (u, v) 权值大于 x, 则 T' = T. 路径可用 DFS 算法求得, 从 u 开始 v 结束. 因为 T 是最小生成树, 所以路径唯一, 时间 O(V+E).
-
-If(u,v) is not in MST, decrease the weight of(u, v), we may form a new MST T'.
-
-**Condition 1** : if the weightest edge e in path from u->v is greater than edge(u,v).Then we can replace e with (u,v).
-
-**Condition 2** : if the weightest edge e in path from u->v is less or equal than edge(u,v).Then we need not change,
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
-本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
-
+
+### `Answer`
+假设存在两个最小生成树 T 和 T'. 对任意一条边 e 属于 T, 如果从 T 中移除 e, 则 T 变得不连通, 形成 cut (S, V - S), 根据练习 23.1-3 可知, e 是穿过 cut(S, V - S) 最轻边. 假设边 x 属于 T', 并穿过 cut (S, V - S), 则 x 同样是最轻边. 由于穿过 cut(S, V - S) 的最轻边唯一. 既 e 和 x 是同一条边. 所以 e 也属于 T', 由于我们选择 e 是任意的, 所有在 T 中的边, 同样在 T' 中. 即最小生成树唯一.
+
+Assuming there are two MSTs called T and T'. For any edge e in T, if we refove e from T, then T becomes unconnected and we have a cut(S, V - S). According to exercise 23.1-3, e is the light edge through cut(S, V - S). If edge x is in T' and through cut(S, V - S), then x is also a light weight. Because the light edge is unique. So e and x is the same edge, e is also in T'. Because we choose e at random, of all edges in T, also in T'. As a result, the MST is unique.
+
+将条件和结论调换则不成立, 如下.
+
+If inverse, then does not hold. See the picture.
+
+
+
+### Exercises 23.1-7
+***
+Argue that if all edge weights of a graph are positive, then any subset of edges that connects all vertices and has minimum total weight must be a tree. Give an example to show that the same conclusion does not follow if we allow some weights to be nonpositive.
+
+### `Answer`
+假设边的子集 T 中存在环, 则某两点之间存在多条通路, 移除其中一条通路, 子集 A' 仍然连通所有点. 因为边的权重为正, 既 w(A') < w(A), 结论与条件矛盾, 所以 T 是树.
+
+Assuming any subset of edges contain circles, then there must be points u,v, the path from u to v is not unique. If we remove a path, subset A' also connects all the points. Because the weight is positive, w(A') < w(A). There is a confliction, because we can produce smaller graph. So no circles, it must be a tree.
+
+如果边的权重准许为负, 则子集 T 不一定是树, 图中三条边总权重最小, 如下.
+
+If some weights could be nonpositive, see picture below. It is a graph with total minimum weights.
+
+
+
+### Exercises 23.1-8
+***
+Let T be a minimum spanning tree of a graph G, and let L be the sorted list of the edge weights of T. Show that for any other minimum spanning tree T′ of G, the list L is also the sorted list of edge weights of T′.
+
+### `Answer`
+假设最小生成树有 n 条边, 存在两个最小生成树 T 和 T', 用 w(e) 表示边的权值.
+T 权值递增排列 w(a1) <= w(a2) <= ... w(an)
+T' 权值递增排列 w(b1) <= w(b2) <= ... w(bn)
+假设 i 是两个列表中, 第一次出现边不同的位置, 既 ai ≠ bi, 先假定 w(ai) >= w(bi).
+
+情况1, 如果 T 中含有边 bi, 由于 ai 和 bi 在列表 i 位置之前都是相同的, 若含有 bi 则一定在 i 位置后, 既有 j > i 使得 w(aj) = w(bi). 得到 w(bi) = w(aj) >= w(ai) >= w(bi), 既 w(bi) = w(aj) = w(ai), 故 i 位置处边的权值相同.
+
+情况2, 如果 T 不包含边 bi, 则把 bi 加到 T 中, 会在某处形成一个圈. 由于 T 是最小生成树, 圈内任何一条边的权值都小于等于 w(bi), 另外这个圈中必定存在 aj 不在 T' 中, 得出 w(aj) <= w(bi) 且 j > i. 因此 w(bi) <= w(ai) <= w(aj) <= w(bi), 既 w(bi) = w(aj) = w(ai), 故 i 位置处边的权值仍相同.
+
+Assuming MST contains n edges, there existing two MST T and T', w(e) stand for the weight of edge e.
+For T w(a1) <= w(a2) <= ... w(an)
+For T' w(b1) <= w(b2) <= ... w(bn)
+Also assuming i is the first occuring index where ai ≠ bi, let's assume w(ai) >= w(bi).
+
+**Condition 1** : If bi is in T, because the preceeding edges befor ai and bi are same, if T containing bi then bi must after ai. So there existing j > i, w(aj) = w(bi). Which produce w(bi) = w(aj) >= w(ai) >= w(bi). So w(ai) = w(bi).
+
+**Condition 2** : If bi is not in T, then adding bi to T will produce a circle. Because T is MST, any weights of nodes in this circle will be less or equal than w(bi). Besides, in this circles, there must exiting aj which not in T' and have w(aj) <= w(bi), j > i.
+So, w(bi) <= w(ai) <= w(aj) <= w(bi), w(bi) = w(aj) = w(ai).
+
+### Exercises 23.1-9
+***
+Let T be a minimum spanning tree of a graph G = (V, E), and let V′ be a subset of V. Let T′ be the subgraph of T induced by V′, and let G′ be the subgraph of G induced by V′. Show that if T′ is connected, then T′ is a minimum spanning tree of G′.
+
+### `Answer`
+用 cut (V', V - V') 分割图 G, 该 cut 一定不影响 T', 且 T' 是 T 的子集, 所以 T' 对于 G' 是安全的. 如果 T' 是连通的, 则 T' 一定是 G' 的最小生成树.
+
+We use cut(V', V - V') to cut graph. This cut will not influence T' and T' is the subset of T, so to G', T' is safe. if T′ is connected, then T′ is a minimum spanning tree of G.
+
+### Exercises 23.1-10
+***
+Given a graph G and a minimum spanning tree T , suppose that we decrease the weight of one of the edges in T . Show that T is still a minimum spanning tree for G. More formally, let T be a minimum spanning tree for G with edge weights given by weight function w. Choose one edge (x, y) ∈ T and a positive number k, and define the weight function w' by
+
+
+
+Show that T is a minimum spanning tree for G with edge weights given by w′.
+
+### `Answer`
+We prove by cut. Originally, (x,y) is the light edge in a certain cut(V1, V2). Decreasing the weight of (x,y), (x,y) is still a light edge. So T is a minimum spanning tree for G with edge weights given by w′.
+
+### Exercises 23.1-11 *
+Given a graph G and a minimum spanning tree T , suppose that we decrease the weight of one of the edges not in T . Give an algorithm for finding the minimum spanning tree in the modified graph.
+
+### `Answer`
+假设 (u, v) 不在最小生成树 T 中, 减小 (u, v) 权值后, 形成新的最小生成树 T'. 可能的情况是 T' 包含 (u, v) 或者 T' = T 保持不变. 算法只需寻找 T 中 u -> v 路径中权值最重边 x, 如果该边权值大于 (u, v), 则 T' = T - x + (u, v). 如果 (u, v) 权值大于 x, 则 T' = T. 路径可用 DFS 算法求得, 从 u 开始 v 结束. 因为 T 是最小生成树, 所以路径唯一, 时间 O(V+E).
+
+If(u,v) is not in MST, decrease the weight of(u, v), we may form a new MST T'.
+
+**Condition 1** : if the weightest edge e in path from u->v is greater than edge(u,v).Then we can replace e with (u,v).
+
+**Condition 2** : if the weightest edge e in path from u->v is less or equal than edge(u,v).Then we need not change,
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
+本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
+
diff --git a/C23-Minimum-Spanning-Trees/23.2.md b/C23-Minimum-Spanning-Trees/23.2.md
index 619e0172..3b32597e 100644
--- a/C23-Minimum-Spanning-Trees/23.2.md
+++ b/C23-Minimum-Spanning-Trees/23.2.md
@@ -1,101 +1,132 @@
-### Exercises 23.2-1
-***
-Kruskal's algorithm can return different spanning trees for the same input graph G, depending on how ties are broken when the edges are sorted into order. Show that for each minimum spanning tree T of G, there is a way to sort the edges of G in Kruskal's algorithm so that the algorithm returns T.
-### `Answer`
-产生不同的MST的原因就在于当有几条相同的边时选择的顺序不一样.
-
-The reason why there may be several different MST is that we have several choices on same weighted edge.
-
-Given a minimum spanning tree T we wish to sort the edges in Kruskal’s algorithm such that it produces T. For each edge e in T simply make sure that it preceeds any other edge not in T with weight w(e).
-
-### Exercises 23.2-2
-***
-Suppose that the graph G = (V, E) is represented as an adjacency matrix. Give a simple
implementation of Prim's algorithm for this case that runs in O(V^2) time.
-
-### `Answer`
-
- MST-PRIM(G, w, r)
- for each u ∈ V[G]
- do key[u] <- ∞
- π[u] <- NIL
- key[r] <- 0
- Q <- V[G]
- while !isEmpty(Q)
- do u <- EXTRACT-MIN(Q)
- for i <- 1 to n
- do if MATRIX[u][i] == 1 and i ∈ Q and w(u,i) < key[i]
- then π[i] <- u
- key[i] <- w(u, i)
-
-### Exercises 23.2-3
-***
-Is the Fibonacci-heap implementation of Prim's algorithm asymptotically faster than the binary-heap implementation for a sparse graph G = (V, E), where |E| = Θ(V)? What about for a dense graph, where |E| = Θ(V2)? How must |E| and |V| be related for the Fibonacci-heap implementation to be asymptotically faster than the binary-heap implementation?
-### `Answer`
-Consider the running times of Prims algorithm implemented with either a binary heap or a Fibon-nacci heap. Suppose |E| = Θ(V) then the running times are:
-
-• Binary: O(ElgV) = O(V lgV)
• Fibonnacci: O(E+VlgV)=O(VlgV)
If |E| = Θ(V2) then:
• Binary:O(ElgV)=O(V2lgV)
• Fibonnacci: O(E + V lg V) = O(V2)
The Fibonnacci heap beats the binary heap implementation of Prims algorithm when |E| = ω(V) since O(E+VlgV) = O(VlgV) t for |E| = O(VlgV) but O(ElgV) = ω(VlgV) for |E| = ω(V ). For |E| = ω(V lg V ) the Fibonnacci version clearly has a better running time than the ordinary version.
-
-
-### Exercises 23.2-4
-***
+### Exercises 23.2-1
+***
+Kruskal's algorithm can return different spanning trees for the same input graph G, depending on how ties are broken when the edges are sorted into order. Show that for each minimum spanning tree T of G, there is a way to sort the edges of G in Kruskal's algorithm so that the algorithm returns T.
+
+### `Answer`
+产生不同的MST的原因就在于当有几条相同的边时选择的顺序不一样.
+
+The reason why there may be several different MST is that we have several choices on same weighted edge.
+
+Given a minimum spanning tree T we wish to sort the edges in Kruskal’s algorithm such that it produces T. For each edge e in T simply make sure that it preceeds any other edge not in T with weight w(e).
+
+### Exercises 23.2-2
+***
+Suppose that the graph G = (V, E) is represented as an adjacency matrix. Give a simple
+implementation of Prim's algorithm for this case that runs in O(V^2) time.
+
+### `Answer`
+
+ MST-PRIM(G, w, r)
+ for each u ∈ V[G]
+ do key[u] <- ∞
+ π[u] <- NIL
+ key[r] <- 0
+ Q <- V[G]
+ while !isEmpty(Q)
+ do u <- EXTRACT-MIN(Q)
+ for i <- 1 to n
+ do if MATRIX[u][i] == 1 and i ∈ Q and w(u,i) < key[i]
+ then π[i] <- u
+ key[i] <- w(u, i)
+
+### Exercises 23.2-3
+***
+Is the Fibonacci-heap implementation of Prim's algorithm asymptotically faster than the binary-heap implementation for a sparse graph G = (V, E), where |E| = Θ(V)? What about for a dense graph, where |E| = Θ(V2)? How must |E| and |V| be related for the Fibonacci-heap implementation to be asymptotically faster than the binary-heap implementation?
+
+### `Answer`
+Consider the running times of Prims algorithm implemented with either a binary heap or a Fibon-nacci heap. Suppose |E| = Θ(V) then the running times are:
+
+• Binary: O(ElgV) = O(V lgV)
+
+• Fibonnacci: O(E+VlgV)=O(VlgV)
+
+If |E| = Θ(V2) then:
+
+• Binary:O(ElgV)=O(V2lgV)
+
+• Fibonnacci: O(E + V lg V) = O(V2)
+
+The Fibonnacci heap beats the binary heap implementation of Prims algorithm when |E| = ω(V) since O(E+VlgV) = O(VlgV) t for |E| = O(VlgV) but O(ElgV) = ω(VlgV) for |E| = ω(V ). For |E| = ω(V lg V ) the Fibonnacci version clearly has a better running time than the ordinary version.
+
+
+### Exercises 23.2-4
+***
Suppose that all edge weights in a graph are integers in the range from 1 to |V|. How fast can you make Kruskal's algorithm run? What if the edge weights are integers in the range from 1 to W for some constant W?
-
-### `Answer`
-If w is a constant we can use **counting sort**
-
-• Sorting the edges: O(E lg E) time.
-
• O(E) operations on a disjoint-set forest taking O(Eα(V)).
-
The sort dominates and hence the total time is O(E lg E). Sorting using counting sort when the edges fall in the range 1, . . . , |V | yields O(V + E) = O(E) time sorting. The total time is then O(Eα(V )). If the edges fall in the range 1, . . . , W for any constant W we still need to use Ω(E) time for sorting and the total running time cannot be improved further.
-
-### Exercises 23.2-5
-***
-Suppose that all edge weights in a graph are integers in the range from 1 to |V|. How fast can you make Prim's algorithm run? What if the edge weights are integers in the range from 1 to W for some constant W?
### `Answer`
-The running time of Prims algorithm is composed :
-
• O(V) initialization.
-
• O(V · time for EXTRACT-MIN).
-
• O(E · time for DECREASE-KEY).
-
If the edges are in the range 1, . . . , |V| the Van Emde Boas priority queue can speed up EXTRACT- MIN and DECREASE-KEY to O(lg lg V) thus yielding a total running time of O(V lg lg V +E lg lg V) = O(E lg lg V ). If the edges are in the range from 1 to W we can implement the queue as an array [1...W+1]wheretheithslotholdsadoublylinkedlistoftheedgeswithweighti. TheW+1st slot contains ∞. EXTRACT-MIN now runs in O(W) = O(1) time since we can simply scan for the first nonempty slot and return the first element of that list. DECREASE-KEY runs in O(1) time as well since it can be implemented by moving an element from one slot to another.
-
-### Exercises 23.2-6 *
-***
-Suppose that the edge weights in a graph are uniformly distributed over the half-open interval
[0, 1). Which algorithm, Kruskal's or Prim's, can you make run faster?
-
-### `Answer`
-Kruskal, using bucket sort.
-
-### Exercises 23.2-7 *
-***
-Suppose that a graph G has a minimum spanning tree already computed. How quickly can the
minimum spanning tree be updated if a new vertex and incident edges are added to G?
-
-### `Answer`
-如果只有一条边,只需要将这个顶点和这条边加进去.
-
-如果有k(k > 1)条边,那么需要删去k-1条边.
-
-假设新节点是v,那么从v必然有一些回路. 遍历k-1次,每次都能找到一个回路,从该回路中删除一条权值最大的边.
-
-If there is only one edge, just add this edge.
-
-If there are k(k > 1) edges, then we need to remmove k-1 edges. We can find cycles by Union-Find and remove the weightest edge in an union. This algorithm need (k-1) passes.
### Exercises 23.2-8
-***
Professor Toole proposes a new divide-and-conquer algorithm for computing minimum spanning trees, which goes as follows. Given a graph G = (V, E), partition the set V of vertices into two sets V1 and V2 such that |V1| and |V2| differ by at most 1. Let E1 be the set of edges that are incident only on vertices in V1, and let E2 be the set of edges that are incident only on vertices in V2. Recursively solve a minimum-spanning-tree problem on each of the two subgraphs G1 = (V1, E1) and G2 = (V2, E2). Finally, select the minimum-weight edge in E that crosses the cut (V1, V2), and use this edge to unite the resulting two minimum spanning trees into a single spanning tree.
Either argue that the algorithm correctly computes a minimum spanning tree of G, or provide an example for which the algorithm fails.
### `Answer`
-We argue that the algorithm fails. Consider the graph G below. We partition G into V1 and V2 as follows: V1 = {A, B}, V2 = {C,
-D}. E1 = {(A, B)}. E2 = {(C, D)}. The set of edges that cross the cut is Ec = {(A, C), (B, D)}.
-
-
-
-Now, we must recursively find the minimum spanning trees of G1 and G2. We can see that in this case, MST(G1) = G1 and MST(G2) = G2. The minimum spanning trees of G1 and G2 are shown below on the left.
-
-The minimum weighted edge of the two edges across the cut is edge (A, C). So (A, C) is used to connect G1 and G2. This is the minimum spanning tree returned by Professor Borden’s algorithm. It is shown below and to the right.
-
-
-
-We can see that the minimum-spanning tree returned by Professor Borden’s algorithm is not the minimum spanning tree of G, therefore, this algorithm fails.
-
-
-[reference](http://test.scripts.psu.edu/users/d/j/djh300/cmpsc465/notes-4985903869437/solutions-to-some-homework-exercises-as-shared-with-students/4-solutions-clrs-23.pdf)
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
-本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
-
+
+### `Answer`
+If w is a constant we can use **counting sort**
+
+• Sorting the edges: O(E lg E) time.
+
+• O(E) operations on a disjoint-set forest taking O(Eα(V)).
+
+The sort dominates and hence the total time is O(E lg E). Sorting using counting sort when the edges fall in the range 1, . . . , |V | yields O(V + E) = O(E) time sorting. The total time is then O(Eα(V )). If the edges fall in the range 1, . . . , W for any constant W we still need to use Ω(E) time for sorting and the total running time cannot be improved further.
+
+### Exercises 23.2-5
+***
+Suppose that all edge weights in a graph are integers in the range from 1 to |V|. How fast can you make Prim's algorithm run? What if the edge weights are integers in the range from 1 to W for some constant W?
+
+### `Answer`
+The running time of Prims algorithm is composed :
+
+• O(V) initialization.
+
+• O(V · time for EXTRACT-MIN).
+
+• O(E · time for DECREASE-KEY).
+
+If the edges are in the range 1, . . . , |V| the Van Emde Boas priority queue can speed up EXTRACT- MIN and DECREASE-KEY to O(lg lg V) thus yielding a total running time of O(V lg lg V +E lg lg V) = O(E lg lg V ). If the edges are in the range from 1 to W we can implement the queue as an array [1...W+1]wheretheithslotholdsadoublylinkedlistoftheedgeswithweighti. TheW+1st slot contains ∞. EXTRACT-MIN now runs in O(W) = O(1) time since we can simply scan for the first nonempty slot and return the first element of that list. DECREASE-KEY runs in O(1) time as well since it can be implemented by moving an element from one slot to another.
+
+### Exercises 23.2-6 *
+***
+Suppose that the edge weights in a graph are uniformly distributed over the half-open interval
+[0, 1). Which algorithm, Kruskal's or Prim's, can you make run faster?
+
+### `Answer`
+Kruskal, using bucket sort.
+
+### Exercises 23.2-7 *
+***
+Suppose that a graph G has a minimum spanning tree already computed. How quickly can the
+minimum spanning tree be updated if a new vertex and incident edges are added to G?
+
+### `Answer`
+如果只有一条边,只需要将这个顶点和这条边加进去.
+
+如果有k(k > 1)条边,那么需要删去k-1条边.
+
+假设新节点是v,那么从v必然有一些回路. 遍历k-1次,每次都能找到一个回路,从该回路中删除一条权值最大的边.
+
+If there is only one edge, just add this edge.
+
+If there are k(k > 1) edges, then we need to remmove k-1 edges. We can find cycles by Union-Find and remove the weightest edge in an union. This algorithm need (k-1) passes.
+
+### Exercises 23.2-8
+***
+Professor Toole proposes a new divide-and-conquer algorithm for computing minimum spanning trees, which goes as follows. Given a graph G = (V, E), partition the set V of vertices into two sets V1 and V2 such that |V1| and |V2| differ by at most 1. Let E1 be the set of edges that are incident only on vertices in V1, and let E2 be the set of edges that are incident only on vertices in V2. Recursively solve a minimum-spanning-tree problem on each of the two subgraphs G1 = (V1, E1) and G2 = (V2, E2). Finally, select the minimum-weight edge in E that crosses the cut (V1, V2), and use this edge to unite the resulting two minimum spanning trees into a single spanning tree.
+
+Either argue that the algorithm correctly computes a minimum spanning tree of G, or provide an example for which the algorithm fails.
+
+### `Answer`
+We argue that the algorithm fails. Consider the graph G below. We partition G into V1 and V2 as follows: V1 = {A, B}, V2 = {C,
+D}. E1 = {(A, B)}. E2 = {(C, D)}. The set of edges that cross the cut is Ec = {(A, C), (B, D)}.
+
+
+
+Now, we must recursively find the minimum spanning trees of G1 and G2. We can see that in this case, MST(G1) = G1 and MST(G2) = G2. The minimum spanning trees of G1 and G2 are shown below on the left.
+
+The minimum weighted edge of the two edges across the cut is edge (A, C). So (A, C) is used to connect G1 and G2. This is the minimum spanning tree returned by Professor Borden’s algorithm. It is shown below and to the right.
+
+
+
+We can see that the minimum-spanning tree returned by Professor Borden’s algorithm is not the minimum spanning tree of G, therefore, this algorithm fails.
+
+
+[reference](http://test.scripts.psu.edu/users/d/j/djh300/cmpsc465/notes-4985903869437/solutions-to-some-homework-exercises-as-shared-with-students/4-solutions-clrs-23.pdf)
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
+本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
+
diff --git a/C24-Single-Source-Shortest-Paths/24.2.md b/C24-Single-Source-Shortest-Paths/24.2.md
index e0209486..3086665e 100644
--- a/C24-Single-Source-Shortest-Paths/24.2.md
+++ b/C24-Single-Source-Shortest-Paths/24.2.md
@@ -1,58 +1,63 @@
-### Exercises 24.2-1
-***
-Run DAG-SHORTEST-PATHS on the directed graph of Figure 24.5, using vertex r as the
source.
-### `Answer`
-
-straightforward.
-
-
-### Exercises 24.2-2
-***
-Suppose we change line 3 of DAG-SHORTEST-PATHS to read 3 for the first |V| - 1 vertices, taken in topologically sorted order Show that the procedure would remain correct.
-### `Answer`
-因为最后一次对结果没有影响.
-
-### Exercises 24.2-3
-***
-The PERT chart formulation given above is somewhat unnatural. It would be more natural for vertices to represent jobs and edges to represent sequencing constraints; that is, edge (u, v) would indicate that job u must be performed before job v. Weights would then be assigned to vertices, not edges. Modify the DAG-SHORTEST-PATHS procedure so that it finds a longest path in a directed acyclic graph with weighted vertices in linear time.
-### `Answer`
-
- PERT(G)
- topologically sort the vertices of G
- INITIALIZE(G)
- for each vertex u, taken in topologically sorted order
- do for each vertex v ∈ Adj[u]
- do RELAX(u,v)
-
- INITIALIZE(G)
- for each vertex v ∈ V[G]
- do d[v] = w[v]
- π[v] = NIL
-
- RELAX(u, v)
- if(d[v] < d[u] + w[v])
- d[v] = d[u] + w[v]
- u[v] = u
-
-
-### Exercises 24.2-4
-***
+### Exercises 24.2-1
+***
+Run DAG-SHORTEST-PATHS on the directed graph of Figure 24.5, using vertex r as the
+source.
+
+### `Answer`
+
+straightforward.
+
+
+### Exercises 24.2-2
+***
+Suppose we change line 3 of DAG-SHORTEST-PATHS to read 3 for the first |V| - 1 vertices, taken in topologically sorted order Show that the procedure would remain correct.
+
+### `Answer`
+因为最后一次对结果没有影响.
+
+### Exercises 24.2-3
+***
+The PERT chart formulation given above is somewhat unnatural. It would be more natural for vertices to represent jobs and edges to represent sequencing constraints; that is, edge (u, v) would indicate that job u must be performed before job v. Weights would then be assigned to vertices, not edges. Modify the DAG-SHORTEST-PATHS procedure so that it finds a longest path in a directed acyclic graph with weighted vertices in linear time.
+
+### `Answer`
+
+ PERT(G)
+ topologically sort the vertices of G
+ INITIALIZE(G)
+ for each vertex u, taken in topologically sorted order
+ do for each vertex v ∈ Adj[u]
+ do RELAX(u,v)
+
+ INITIALIZE(G)
+ for each vertex v ∈ V[G]
+ do d[v] = w[v]
+ π[v] = NIL
+
+ RELAX(u, v)
+ if(d[v] < d[u] + w[v])
+ d[v] = d[u] + w[v]
+ u[v] = u
+
+
+### Exercises 24.2-4
+***
Give an efficient algorithm to count the total number of paths in a directed acyclic graph. Analyze your algorithm.
-
-### `Answer`
- DAG-PATHS(G, s)
- topologically sort the vertices of G
- INITIALIZE(G, s)
- for each vertex u, taken in topologically sorted order
- do for each vertex v ∈ Adj[u]
- do c[v] = c[v] + c[u]
-
- INITIALIZE(G, s)
- for each vertex v ∈ V[G]
- do c[v] = 0
- c[s] = 1
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
-本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
-
+
+### `Answer`
+ DAG-PATHS(G, s)
+ topologically sort the vertices of G
+ INITIALIZE(G, s)
+ for each vertex u, taken in topologically sorted order
+ do for each vertex v ∈ Adj[u]
+ do c[v] = c[v] + c[u]
+
+ INITIALIZE(G, s)
+ for each vertex v ∈ V[G]
+ do c[v] = 0
+ c[s] = 1
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
+本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
+
diff --git a/C24-Single-Source-Shortest-Paths/24.3.md b/C24-Single-Source-Shortest-Paths/24.3.md
index a2cead64..337d2ea2 100644
--- a/C24-Single-Source-Shortest-Paths/24.3.md
+++ b/C24-Single-Source-Shortest-Paths/24.3.md
@@ -1,75 +1,84 @@
-### Exercises 24.3-1
-***
-Run Dijkstra's algorithm on the directed graph of Figure 24.2, first using vertex s as the source and then using vertex z as the source. In the style of Figure 24.6, show the d and π values and the vertices in set S after each iteration of the while loop.
-### `Answer`
-
-
-
-
-
-
-### Exercises 24.3-2
-***
-Give a simple example of a directed graph with negative-weight edges for which Dijkstra's algorithm produces incorrect answers. Why doesn't the proof of Theorem 24.6 go through when negative-weight edges are allowed?
-### `Answer`
-Dijkstra算法的原理是:每次新拓展一个最近的点,更新与其相邻的点的距离,当所有边的权值都为正时,由于不会存在一个距离更短的没拓展过的点,所以这个点的距离永远不会被改变,因而保证了算法的正确性.但是这个原理有一个限制,就是边权不能为负.
-
-### Exercises 24.3-3
-***
-Suppose we change line 4 of Dijkstra's algorithm to the following.
-
-**4** while |Q| > 1
This change causes the while loop to execute |V | - 1 times instead of |V | times. Is this proposed algorithm correct?
-### `Answer`
-完全正确,其他点已经做过relax,不可能再更新了.否则就破坏了这个算法的基本性质.
-
-### Exercises 24.3-4
-***
+### Exercises 24.3-1
+***
+Run Dijkstra's algorithm on the directed graph of Figure 24.2, first using vertex s as the source and then using vertex z as the source. In the style of Figure 24.6, show the d and π values and the vertices in set S after each iteration of the while loop.
+
+### `Answer`
+
+
+
+
+
+
+### Exercises 24.3-2
+***
+Give a simple example of a directed graph with negative-weight edges for which Dijkstra's algorithm produces incorrect answers. Why doesn't the proof of Theorem 24.6 go through when negative-weight edges are allowed?
+
+### `Answer`
+Dijkstra算法的原理是:每次新拓展一个最近的点,更新与其相邻的点的距离,当所有边的权值都为正时,由于不会存在一个距离更短的没拓展过的点,所以这个点的距离永远不会被改变,因而保证了算法的正确性.但是这个原理有一个限制,就是边权不能为负.
+
+### Exercises 24.3-3
+***
+Suppose we change line 4 of Dijkstra's algorithm to the following.
+
+**4** while |Q| > 1
+
+This change causes the while loop to execute |V | - 1 times instead of |V | times. Is this proposed algorithm correct?
+
+
+### `Answer`
+完全正确,其他点已经做过relax,不可能再更新了.否则就破坏了这个算法的基本性质.
+
+### Exercises 24.3-4
+***
We are given a directed graph G = (V, E) on which each edge (u, v) ∈ E has an associated value r(u, v), which is a real number in the range 0 ≤ r(u, v) ≤ 1 that represents the reliability of a communication channel from vertex u to vertex v. We interpret r(u, v) as the probability that the channel from u to v will not fail, and we assume that these probabilities are independent. Give an efficient algorithm to find the most reliable path between two given vertices.
-
-### `Answer`
-令w(u,v) = lg(r(u,v)),即可转化用Dijkstra算法解决.
-
-### Exercises 24.3-5
-***
-Let G = (V, E) be a weighted, directed graph with weight function w : E → {1, 2, ..., W } for some positive integer W , and assume that no two vertices have the same shortest-path weights from source vertex s. Now suppose that we define an unweighted, directed graph G' = (V U V', E') by replacing each edge (u, v) ∈ E with w(u, v) unit-weight edges in series. How many vertices does G' have? Now suppose that we run a breadth-first search on G'. Show that the order in which vertices in V are colored black in the breadth-first search of G' is the same as the order in which the vertices of V are extracted from the priority queue in line 5 of DIJKSTRA when run on G.
-
-### `Answer`
-图 G 与 图 G' 的区别如下图所示:
-
-
-
-由图可知, 对应图 G 的每一条边 (u, v), 图 G' 都会新增 w(u, v) - 1 个结点, 因此图 G' 的结点数为 
-
-对于遍历顺序的证明:
-
-假设在图 G 上运行 DIJKSTRA 算法时, 结点 u, v 先后从优先队列中取出. 由题意, 从源点 s 到其他各点的最短路径互不相同, 所以可以肯定 d(u) < d(v). 又因为在图 G' 上进行广度优先遍历时, 结点 u 会在第 d[u] 步染成黑色, 结点 v 则在第 d[v] 步. 因此图 G' 上结点的染色顺序与在图 G 上运行 DIJKSTRA 算法时从优先队列取出的顺序相同.
-
-
-### Exercises 24.3-6
-***
-Let G = (V, E) be a weighted, directed graph with weight function w : E → {0, 1, ..., W } for some nonnegative integer W . Modify Dijkstra's algorithm to compute the shortest paths from a given source vertex s in O(W V + E) time.
-
-### `Answer`
-用一个二维数组A[wv]实现优先级队列.具有长度为d的节点就在A[d]的list中.
-
-EXTRACT-MIN总共需要O(WV)的时间. 因为跑完整个算法相当于遍历了一遍数组.
-
-DECREASE-KEY总共需要O(E)的时间. 每次检查一条边做relax,只需要根据d移动到数组A的对应位置.
-
-### Exercises 24.3-7
-***
-Modify your algorithm from Exercise 24.3-6 to run in O((V + E) lg W ) time. (Hint: How
many distinct shortest-path estimates can there be in V - S at any point in time?)
-
-### `Answer`
-用binary heap实现priority queue.
-
-### Exercises 24.3-8
-***
-Suppose that we are given a weighted, directed graph G = (V, E) in which edges that leave the source vertex s may have negative weights, all other edge weights are nonnegative, and there are no negative-weight cycles. Argue that Dijkstra's algorithm correctly finds shortest paths from s in this graph.
-
-### `Answer`
-这种情况下不会破坏已经更新的点的距离.
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
-本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
+
+### `Answer`
+令w(u,v) = lg(r(u,v)),即可转化用Dijkstra算法解决.
+
+### Exercises 24.3-5
+***
+Let G = (V, E) be a weighted, directed graph with weight function w : E → {1, 2, ..., W } for some positive integer W , and assume that no two vertices have the same shortest-path weights from source vertex s. Now suppose that we define an unweighted, directed graph G' = (V U V', E') by replacing each edge (u, v) ∈ E with w(u, v) unit-weight edges in series. How many vertices does G' have? Now suppose that we run a breadth-first search on G'. Show that the order in which vertices in V are colored black in the breadth-first search of G' is the same as the order in which the vertices of V are extracted from the priority queue in line 5 of DIJKSTRA when run on G.
+
+### `Answer`
+图 G 与 图 G' 的区别如下图所示:
+
+
+
+由图可知, 对应图 G 的每一条边 (u, v), 图 G' 都会新增 w(u, v) - 1 个结点, 因此图 G' 的结点数为 
+
+对于遍历顺序的证明:
+
+假设在图 G 上运行 DIJKSTRA 算法时, 结点 u, v 先后从优先队列中取出. 由题意, 从源点 s 到其他各点的最短路径互不相同, 所以可以肯定 d(u) < d(v). 又因为在图 G' 上进行广度优先遍历时, 结点 u 会在第 d[u] 步染成黑色, 结点 v 则在第 d[v] 步. 因此图 G' 上结点的染色顺序与在图 G 上运行 DIJKSTRA 算法时从优先队列取出的顺序相同.
+
+
+### Exercises 24.3-6
+***
+Let G = (V, E) be a weighted, directed graph with weight function w : E → {0, 1, ..., W } for some nonnegative integer W . Modify Dijkstra's algorithm to compute the shortest paths from a given source vertex s in O(W V + E) time.
+
+### `Answer`
+用一个二维数组A[wv]实现优先级队列.具有长度为d的节点就在A[d]的list中.
+
+EXTRACT-MIN总共需要O(WV)的时间. 因为跑完整个算法相当于遍历了一遍数组.
+
+DECREASE-KEY总共需要O(E)的时间. 每次检查一条边做relax,只需要根据d移动到数组A的对应位置.
+
+### Exercises 24.3-7
+***
+Modify your algorithm from Exercise 24.3-6 to run in O((V + E) lg W ) time. (Hint: How
+many distinct shortest-path estimates can there be in V - S at any point in time?)
+
+### `Answer`
+用binary heap实现priority queue.
+
+### Exercises 24.3-8
+***
+Suppose that we are given a weighted, directed graph G = (V, E) in which edges that leave the source vertex s may have negative weights, all other edge weights are nonnegative, and there are no negative-weight cycles. Argue that Dijkstra's algorithm correctly finds shortest paths from s in this graph.
+
+### `Answer`
+这种情况下不会破坏已经更新的点的距离.
+
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
+本节部分答案参考自[这里](http://blog.csdn.net/anye3000/article/details/12091125)
diff --git a/C26-Flow-networks/26.1.md b/C26-Flow-networks/26.1.md
index d3443105..f8e16590 100644
--- a/C26-Flow-networks/26.1.md
+++ b/C26-Flow-networks/26.1.md
@@ -1,74 +1,87 @@
-### Exercises 26.1-1
-***
-
Using the definition of a flow, prove that if (u, v) ∉ E and (v, u) ∉ E then f(u, v) = f(v, u) = 0.
-### `Answer`
- f(u,v) <= c(u,v)
- f(u,v) + f(v, u) = 0
- c(u,v) = 0
-
-So f(u,v) = f(v,u) = 0
-
-### Exercises 26.1-2
-***
Prove that for any vertex v other than the source or sink, the total positive flow entering v must equal the total positive flow leaving v.
-
-### `Answer`
-Capacity constraint: For all u, v ∈ V, we require f(u, v) <= c(u, v)
-
-Skew Symmetry: For all u, v ∈ V, we require f(u, v) <= -f(u, v)
-
-Flow conservation: For all u, v ∈ V – {s, t}, we require Σ f(u, v) = 0
-
-### Exercises 26.1-3
-***
Extend the flow properties and definitions to the multiple-source, multiple-sink problem. Show that any flow in a multiple-source, multiple-sink flow network corresponds to a flow of identical value in the single-source, single-sink network obtained by adding a supersource and a supersink, and vice versa.
-
-### `Answer`
-In Figure 26.2, we add a supersource s and add a directed edge (s, si) with capacity c(s, si) = ∞ for each i = 1, 2, . . . , m. We also create a new supersink t and add a directed edge (ti, t) with capacity c(ti, t) = ∞ for each i = 1, 2, . . . , n. The single source s simply provides as much flow as desired for the multiple sources si, and the single sink t likewise consumes as much flow as desired for the multiple sinks ti.
-
-Because the virutal edges of s and t can consume as much flows as they want, they don't influence the actual edges.
-
-### Exercises 26.1-4
-***
Prove Lemma 26.1.
-
-### `Answer`
-Pretty obvious, several vertices make up a set. Apply each f on on vertices and combine them.
-
-### Exercises 26.1-5
-***
For the flow network G = (V, E) and flow f shown in Figure 26.1(b), find a pair of subsets X, Y for all u, v ∈ V. If f1 and f2 are flows in G, which of the three flow properties must the flow sum f1 + f2 satisfy, and which might it violate? V for which f(X, Y) = - f(V - X, Y). Then, find a pair of subsets X, Y ∈ V for which f (X, Y) ≠ - f(V - X, Y).
-
-### `Answer`
-X = {v1, v2} , Y = {v3} , f(X, Y) = - f(V - X, Y)
-
-X = {s} , Y = {t} , f(X, Y) ≠ - f(V - X, Y)
-
-### Exercises 26.1-6
-***
Given a flow network G = (V,E),let *f1* and *f2* be functions from *V×V* to **R**.The **flow sum** *f1* + *f2* is the function from *V* × *V* to **R** defined by
-
(26.4) (f1+f2)(u,v) = f1(u,v) + f2(u,v)
-
for all u, v ∈ V. If f1 and f2 are flows in G, which of the three flow properties must the flow sum f1 + f2 satisfy, and which might it violate?
-
-### `Answer`
-Flow conservation, may violate Capacity constraint
-
-### Exercises 26.1-7
-***
Let f be a flow in a network, and let α be a real number. The *scalar flow product*, denoted α f, is a function from V × V to **R defined by
-
(αf)(u, v) = α · f (u, v).
-
Prove that the flows in a network form a **convex set**. That is, show that if f1 and f2 are flows, thensoisαf1 +(1-α)f2 forallαintherange0≤α≤1.
-
-### `Answer`
-UNSOLVED
-
-### Exercises 26.1-8
-***
State the maximum-flow problem as a linear-programming problem.
-
-### `Answer`
-Haven't focus on linear-programming yet.
-
-### Exercises 26.1-9
-***
-Professor Adam has two children who, unfortunately, dislike each other. The problem is so severe that not only do they refuse to walk to school together, but in fact each one refuses to walk on any block that the other child has stepped on that day. The children have no problem with their paths crossing at a corner. Fortunately both the professor's house and the school are on corners, but beyond that he is not sure if it is going to be possible to send both of his children to the same school. The professor has a map of his town. Show how to formulate the problem of determining if both his children can go to the same school as a maximum-flow problem.
-
-### `Answer`
-Each edge has weight 1, to see if the max flow is bigger than 1.
-
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
-
+### Exercises 26.1-1
+***
+
+Using the definition of a flow, prove that if (u, v) ∉ E and (v, u) ∉ E then f(u, v) = f(v, u) = 0.
+
+### `Answer`
+ f(u,v) <= c(u,v)
+ f(u,v) + f(v, u) = 0
+ c(u,v) = 0
+
+So f(u,v) = f(v,u) = 0
+
+### Exercises 26.1-2
+***
+Prove that for any vertex v other than the source or sink, the total positive flow entering v must equal the total positive flow leaving v.
+
+### `Answer`
+Capacity constraint: For all u, v ∈ V, we require f(u, v) <= c(u, v)
+
+Skew Symmetry: For all u, v ∈ V, we require f(u, v) <= -f(u, v)
+
+Flow conservation: For all u, v ∈ V – {s, t}, we require Σ f(u, v) = 0
+
+### Exercises 26.1-3
+***
+Extend the flow properties and definitions to the multiple-source, multiple-sink problem. Show that any flow in a multiple-source, multiple-sink flow network corresponds to a flow of identical value in the single-source, single-sink network obtained by adding a supersource and a supersink, and vice versa.
+
+### `Answer`
+In Figure 26.2, we add a supersource s and add a directed edge (s, si) with capacity c(s, si) = ∞ for each i = 1, 2, . . . , m. We also create a new supersink t and add a directed edge (ti, t) with capacity c(ti, t) = ∞ for each i = 1, 2, . . . , n. The single source s simply provides as much flow as desired for the multiple sources si, and the single sink t likewise consumes as much flow as desired for the multiple sinks ti.
+
+Because the virutal edges of s and t can consume as much flows as they want, they don't influence the actual edges.
+
+### Exercises 26.1-4
+***
+Prove Lemma 26.1.
+
+### `Answer`
+Pretty obvious, several vertices make up a set. Apply each f on on vertices and combine them.
+
+### Exercises 26.1-5
+***
+For the flow network G = (V, E) and flow f shown in Figure 26.1(b), find a pair of subsets X, Y for all u, v ∈ V. If f1 and f2 are flows in G, which of the three flow properties must the flow sum f1 + f2 satisfy, and which might it violate? V for which f(X, Y) = - f(V - X, Y). Then, find a pair of subsets X, Y ∈ V for which f (X, Y) ≠ - f(V - X, Y).
+
+### `Answer`
+X = {v1, v2} , Y = {v3} , f(X, Y) = - f(V - X, Y)
+
+X = {s} , Y = {t} , f(X, Y) ≠ - f(V - X, Y)
+
+### Exercises 26.1-6
+***
+Given a flow network G = (V,E),let *f1* and *f2* be functions from *V×V* to **R**.The **flow sum** *f1* + *f2* is the function from *V* × *V* to **R** defined by
+
+(26.4) (f1+f2)(u,v) = f1(u,v) + f2(u,v)
+
+for all u, v ∈ V. If f1 and f2 are flows in G, which of the three flow properties must the flow sum f1 + f2 satisfy, and which might it violate?
+
+### `Answer`
+Flow conservation, may violate Capacity constraint
+
+### Exercises 26.1-7
+***
+Let f be a flow in a network, and let α be a real number. The *scalar flow product*, denoted α f, is a function from V × V to **R defined by
+
+(αf)(u, v) = α · f (u, v).
+
+Prove that the flows in a network form a **convex set**. That is, show that if f1 and f2 are flows, thensoisαf1 +(1-α)f2 forallαintherange0≤α≤1.
+
+### `Answer`
+UNSOLVED
+
+### Exercises 26.1-8
+***
+State the maximum-flow problem as a linear-programming problem.
+
+### `Answer`
+Haven't focus on linear-programming yet.
+
+### Exercises 26.1-9
+***
+Professor Adam has two children who, unfortunately, dislike each other. The problem is so severe that not only do they refuse to walk to school together, but in fact each one refuses to walk on any block that the other child has stepped on that day. The children have no problem with their paths crossing at a corner. Fortunately both the professor's house and the school are on corners, but beyond that he is not sure if it is going to be possible to send both of his children to the same school. The professor has a map of his town. Show how to formulate the problem of determining if both his children can go to the same school as a maximum-flow problem.
+
+### `Answer`
+Each edge has weight 1, to see if the max flow is bigger than 1.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
+
diff --git a/C31-Number-Theoretic-Algorithms/31.1.md b/C31-Number-Theoretic-Algorithms/31.1.md
index 5cfac00e..c830b170 100644
--- a/C31-Number-Theoretic-Algorithms/31.1.md
+++ b/C31-Number-Theoretic-Algorithms/31.1.md
@@ -1,112 +1,140 @@
-### Exercises 31.1-1
-***
-Prove that there are infinitely many primes. (Hint: how that none of the primes p1, p2, ..., pk divide (p1 p2 ··· pk) + 1.)
-### `Answer`
-
-The hint tells us everything.
-
-If we have finite prime numbers{p1,p2,p3,...,pk}. We show that A = (p1 p2 ··· pk) + 1 is neither a composite number nor prime number.
-
-* Becauce we have finite prime numbers, then A is not prime.
-* On the other hand, A mod p1 = 1;A mod p2 = 1;...;A mod pk = 1. So, A is not composite.
-
-As a result, we have infinite many primes.
-
-
-
-### Exercises 31.1-2
-***
-Prove that if a | b and b | c, then a | c.
-
-a | b means b = k1a
-
-b | c means c = k2b
-
+### Exercises 31.1-1
+***
+Prove that there are infinitely many primes. (Hint: how that none of the primes p1, p2, ..., pk divide (p1 p2 ··· pk) + 1.)
+
+### `Answer`
+
+The hint tells us everything.
+
+If we have finite prime numbers{p1,p2,p3,...,pk}. We show that A = (p1 p2 ··· pk) + 1 is neither a composite number nor prime number.
+
+* Becauce we have finite prime numbers, then A is not prime.
+* On the other hand, A mod p1 = 1;A mod p2 = 1;...;A mod pk = 1. So, A is not composite.
+
+As a result, we have infinite many primes.
+
+
+
+### Exercises 31.1-2
+***
+Prove that if a | b and b | c, then a | c.
+
+a | b means b = k1a
+
+b | c means c = k2b
+
So, c = k2b = k1k2a which means a | c
-
-### `Answer`
-If p[i] dismatch T[j],next time trace back to j+1;That is,compare from p[0] and T[j+1].
-
-### Exercises 31.1-3
-***
-Prove that if p is prime and 0 < k < p, then gcd(k, p) = 1.
-### `Answer`
-Obvious.
-
-### Exercises 31.1-4
-***
-Prove Corollary 31.5.
-
-### `Answer`
-ab = kn
-
-b = n(k/a), because gcd(n,a) = 1,k/a is an integer
-
-b = k'n, k' = k/a
-
-so n | b
-
### Exercises 31.1-5
-***
-Prove that if p is prime and 0 < k < p, then  p | (p k). Conclude that for all integers a, b, and primes p, (a+b)p ≡ ap +bp (modp).
-
-### `Answer`
-The first is pretty obvious using polynomial expansion.
-
-If solve the first, the second is easy too.
-
-(a+b)^p mod p
-
-= a^p + b^p + a^1*b^(p-1)(p 1) + ... mod p
-
-= a^p + b^p mod p
-
-### Exercises 31.1-6
-***
-Prove that if a and b are any integers such that a | b and b > 0,
-
-then (x mod b) mod a = x mod a for any x.
-
-Prove, under the same assumptions, that
-
-x ≡ y mod b) implies x ≡ y (mod a)
for any integers x and y.
### `Answer`
-Assume x = ra + b , b = ka
-
-x mod a = b
-
-x mod b = (ra+b)%(ka) = (r%k)a+b
-
-x mod b mod a = (r%k)a % a + b % a = b
-
-### Exercises 31.1-7
-***
-For any integer k > 0, we say that an integer n is a kth power if there exists an integer a such that ak = n.We say that n > 1 is a nontrivial power if it is a kth power for some integer k > 1. Show how to determine if a given β-bit integer n is a nontrivial power in time polynomial in β.
### `Answer`
I only have naive idea : iterate every number.
-
### Exercises 31.1-8
-***
-Prove equations (31.6)–(31.10).
### `Answer`
-straightforward
-
-### Exercises 31.1-9
-***
-Show that the gcd operator is associative. That is, prove that for all integers a, b, and c,
gcd(a, gcd(b, c)) = gcd(gcd(a, b), c).
### `Answer`
-Assume a = p1^i1 * p2^i2 * ... * pk^ik
-
-Assume b = p1^j1 * p2^j2 * ... * pk^jk
-
-Assume c = p1^l1 * p2^l2 * ... * pk^lk
-
-gcd(a, gcd(b, c)) = gcd(gcd(a, b), c) = p1^min(i1,j2,k1) * p2^min(i2,j2,k2) * ... *pk^min(ik,jk,lk)
-
-### Exercises 31.1-10
-***
-Prove Theorem 31.8.
### `Answer`
-If the way is not unique, then some combinations of primes are equal to others. However, gcd(prime1, prime2) = 1, so it is not possible.
-
-### Exercises 31.1-11
-***
-Give efficient algorithms for the operations of dividing a β-bit integer by a shorter integer and of taking the remainder of a β-bit integer when divided by a shorter integer. Your algorithms should run in time O(β2).
### `Answer`
UNSOLVED
-
### Exercises 31.1-12
-***
-Give an efficient algorithm to convert a given β-bit (binary) integer to a decimal representation. Argue that if multiplication or division of integers whose length is at most β takes time M(β), then binary-to-decimal conversion can be performed in time Θ(M(β) lg β).

-(Hint: Use a divide-and-conquer approach, obtaining the top and bottom halves of the result with separate recursions.)
### `Answer`
[implementation](./exercise_code/binary2decimal.py)
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+
+### `Answer`
+If p[i] dismatch T[j],next time trace back to j+1;That is,compare from p[0] and T[j+1].
+
+### Exercises 31.1-3
+***
+Prove that if p is prime and 0 < k < p, then gcd(k, p) = 1.
+
+### `Answer`
+Obvious.
+
+### Exercises 31.1-4
+***
+Prove Corollary 31.5.
+
+### `Answer`
+ab = kn
+
+b = n(k/a), because gcd(n,a) = 1,k/a is an integer
+
+b = k'n, k' = k/a
+
+so n | b
+
+### Exercises 31.1-5
+***
+Prove that if p is prime and 0 < k < p, then  p | (p k). Conclude that for all integers a, b, and primes p, (a+b)p ≡ ap +bp (modp).
+
+### `Answer`
+The first is pretty obvious using polynomial expansion.
+
+If solve the first, the second is easy too.
+
+(a+b)^p mod p
+
+= a^p + b^p + a^1*b^(p-1)(p 1) + ... mod p
+
+= a^p + b^p mod p
+
+### Exercises 31.1-6
+***
+Prove that if a and b are any integers such that a | b and b > 0,
+
+then (x mod b) mod a = x mod a for any x.
+
+Prove, under the same assumptions, that
+
+x ≡ y mod b) implies x ≡ y (mod a)
+
+for any integers x and y.
+
+### `Answer`
+Assume x = ra + b , b = ka
+
+x mod a = b
+
+x mod b = (ra+b)%(ka) = (r%k)a+b
+
+x mod b mod a = (r%k)a % a + b % a = b
+
+### Exercises 31.1-7
+***
+For any integer k > 0, we say that an integer n is a kth power if there exists an integer a such that ak = n.We say that n > 1 is a nontrivial power if it is a kth power for some integer k > 1. Show how to determine if a given β-bit integer n is a nontrivial power in time polynomial in β.
+
+### `Answer`
+I only have naive idea : iterate every number.
+
+### Exercises 31.1-8
+***
+Prove equations (31.6)–(31.10).
+
+### `Answer`
+straightforward
+
+### Exercises 31.1-9
+***
+Show that the gcd operator is associative. That is, prove that for all integers a, b, and c,
+gcd(a, gcd(b, c)) = gcd(gcd(a, b), c).
+
+### `Answer`
+Assume a = p1^i1 * p2^i2 * ... * pk^ik
+
+Assume b = p1^j1 * p2^j2 * ... * pk^jk
+
+Assume c = p1^l1 * p2^l2 * ... * pk^lk
+
+gcd(a, gcd(b, c)) = gcd(gcd(a, b), c) = p1^min(i1,j2,k1) * p2^min(i2,j2,k2) * ... *pk^min(ik,jk,lk)
+
+### Exercises 31.1-10
+***
+Prove Theorem 31.8.
+
+### `Answer`
+If the way is not unique, then some combinations of primes are equal to others. However, gcd(prime1, prime2) = 1, so it is not possible.
+
+### Exercises 31.1-11
+***
+Give efficient algorithms for the operations of dividing a β-bit integer by a shorter integer and of taking the remainder of a β-bit integer when divided by a shorter integer. Your algorithms should run in time O(β2).
+
+### `Answer`
+UNSOLVED
+
+
+### Exercises 31.1-12
+***
+Give an efficient algorithm to convert a given β-bit (binary) integer to a decimal representation. Argue that if multiplication or division of integers whose length is at most β takes time M(β), then binary-to-decimal conversion can be performed in time Θ(M(β) lg β).
+
+(Hint: Use a divide-and-conquer approach, obtaining the top and bottom halves of the result with separate recursions.)
+
+### `Answer`
+[implementation](./exercise_code/binary2decimal.py)
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C31-Number-Theoretic-Algorithms/31.2.md b/C31-Number-Theoretic-Algorithms/31.2.md
index 48f8b74a..aa130fa1 100644
--- a/C31-Number-Theoretic-Algorithms/31.2.md
+++ b/C31-Number-Theoretic-Algorithms/31.2.md
@@ -1,86 +1,96 @@
-### Exercises 31.2-1
-***
-Prove that equations (31.11) and (31.12) imply equation (31.13).
-### `Answer`
-straightforward
-
-### Exercises 31.2-2
-***
+### Exercises 31.2-1
+***
+Prove that equations (31.11) and (31.12) imply equation (31.13).
+
+### `Answer`
+straightforward
+
+### Exercises 31.2-2
+***
Compute the values (d, x, y) that the call EXTENDED-EUCLID(899, 493) returns.
-
-### `Answer`
-(29, -6, 11)
-
-### Exercises 31.2-3
-***
-Prove that for all integers a, k, and n,
-
gcd(a, n) = gcd(a + kn, n).
-### `Answer`
-gcd(a+kn,n) = gcd(n, (a+kn) mod n) = gcd(n, a)
-
-### Exercises 31.2-4
-***
+
+### `Answer`
+(29, -6, 11)
+
+### Exercises 31.2-3
+***
+Prove that for all integers a, k, and n,
+
+gcd(a, n) = gcd(a + kn, n).
+
+### `Answer`
+gcd(a+kn,n) = gcd(n, (a+kn) mod n) = gcd(n, a)
+
+### Exercises 31.2-4
+***
Rewrite EUCLID in an iterative form that uses only a constant amount of memory (that is, stores only a constant number of integer values).
-
-### `Answer`
-[implementation](./euclid.py)
-
### Exercises 31.2-5
-***
-If a > b ≥ 0, show that the invocation EUCLID(a, b) makes at most 1 + logφ b recursive calls. Improve this bound to 1 + logφ(b/ gcd(a, b)).
-
-### `Answer`
-φ^(k+1) / Root(5) < F(k+1) < b
-
-k + 1 < 1/2logφ 5 + logφ b
-
-k <= logφ b + 1
-
-The second is pretty simple, before executing, we divide gcd(a,b) and get the answer.
-
-### Exercises 31.2-6
-***
What does EXTENDED-EUCLID(Fk+1, Fk) return? Prove your answer correct.
-
-### `Answer`
-a | b | 0
-:----:|:----:|:----:
-2 | 1 | (1,0,1)
-3 | 2 | (1,1,-1)
-5 | 3 | (1,-1,2)
-8 | 5 | (1,2,-3)
-13 | 8 | (1,-3,5)
-
-(1,1,2,3,5,8,13,...)
-
-we can conclude that
-
-* if k is odd, the answer is (1, F_k-2, -F_k-1)
-* if k is even, the answer is (1, -F_k-2, F_k-1)
-
-If k is odd,
-
-Fk+1 * Fk-2 - Fk * Fk-1 = Fk * Fk-2 + Fk-1 * Fk-2 - Fk * Fk-1 = Fk-1Fk-2 + Fk-2Fk-2 + Fk-1Fk-2 - Fk-1Fk-1 - Fk-1Fk-2 = Fk-2Fk-2 + Fk-1Fk-2 - Fk-1Fk-1 = 1(by mathematical induction we can obtain the result)
-
-if k is even, the prove is the same.
-
-### Exercises 31.2-7
-***
Define the gcd function for more than two arguments by the recursive equation gcd(a0, a1, ..., an) = gcd(a0, gcd(a1, a2, ..., an)). Show that the gcd function returns the same answer independent of the order in which its arguments are specified. Also show how to find integers x0, x1, ..., xn such that gcd(a0, a1, ..., an) = a0x0 + a1x1 + ··· + anxn. Show that the number of divisions performed by your algorithm is O(n + lg(max {a0, a1, ..., an})).
-
-### `Answer`
-UNSOLVED
-
-### Exercises 31.2-8
-***
Define the gcd function for more than two arguments by the recursive equation gcd(a0, a1, ..., an) = gcd(a0, gcd(a1, a2, ..., an)). Show that the gcd function returns the same answer independent of the order in which its arguments are specified. Also show how to find integers x0, x1, ..., xn such that gcd(a0, a1, ..., an) = a0x0 + a1x1 + ··· + anxn. Show that the number of divisions performed by your algorithm is O(n + lg(max {a0, a1, ..., an})).
-
-### `Answer`
-[implementation](./exercise_code/lcm.py)
-
-### Exercises 31.2-9
-***
Prove that n1, n2, n3, and n4 are pairwise relatively prime if and only if
-
gcd(n1n2, n3n4) = gcd(n1n3, n2n4) = 1.
-
Show more generally that n1, n2, ..., nk are pairwise relatively prime if and only if a set of ⌈lg k⌉ pairs of numbers derived from the ni are relatively prime.
-
+
+### `Answer`
+[implementation](./euclid.py)
+
+### Exercises 31.2-5
+***
+If a > b ≥ 0, show that the invocation EUCLID(a, b) makes at most 1 + logφ b recursive calls. Improve this bound to 1 + logφ(b/ gcd(a, b)).
+
+### `Answer`
+φ^(k+1) / Root(5) < F(k+1) < b
+
+k + 1 < 1/2logφ 5 + logφ b
+
+k <= logφ b + 1
+
+The second is pretty simple, before executing, we divide gcd(a,b) and get the answer.
+
+### Exercises 31.2-6
+***
+What does EXTENDED-EUCLID(Fk+1, Fk) return? Prove your answer correct.
+
+### `Answer`
+a | b | 0
+:----:|:----:|:----:
+2 | 1 | (1,0,1)
+3 | 2 | (1,1,-1)
+5 | 3 | (1,-1,2)
+8 | 5 | (1,2,-3)
+13 | 8 | (1,-3,5)
+
+(1,1,2,3,5,8,13,...)
+
+we can conclude that
+
+* if k is odd, the answer is (1, F_k-2, -F_k-1)
+* if k is even, the answer is (1, -F_k-2, F_k-1)
+
+If k is odd,
+
+Fk+1 * Fk-2 - Fk * Fk-1 = Fk * Fk-2 + Fk-1 * Fk-2 - Fk * Fk-1 = Fk-1Fk-2 + Fk-2Fk-2 + Fk-1Fk-2 - Fk-1Fk-1 - Fk-1Fk-2 = Fk-2Fk-2 + Fk-1Fk-2 - Fk-1Fk-1 = 1(by mathematical induction we can obtain the result)
+
+if k is even, the prove is the same.
+
+### Exercises 31.2-7
+***
+Define the gcd function for more than two arguments by the recursive equation gcd(a0, a1, ..., an) = gcd(a0, gcd(a1, a2, ..., an)). Show that the gcd function returns the same answer independent of the order in which its arguments are specified. Also show how to find integers x0, x1, ..., xn such that gcd(a0, a1, ..., an) = a0x0 + a1x1 + ··· + anxn. Show that the number of divisions performed by your algorithm is O(n + lg(max {a0, a1, ..., an})).
+
+### `Answer`
+UNSOLVED
+
+### Exercises 31.2-8
+***
+Define the gcd function for more than two arguments by the recursive equation gcd(a0, a1, ..., an) = gcd(a0, gcd(a1, a2, ..., an)). Show that the gcd function returns the same answer independent of the order in which its arguments are specified. Also show how to find integers x0, x1, ..., xn such that gcd(a0, a1, ..., an) = a0x0 + a1x1 + ··· + anxn. Show that the number of divisions performed by your algorithm is O(n + lg(max {a0, a1, ..., an})).
+
+### `Answer`
+[implementation](./exercise_code/lcm.py)
+
+### Exercises 31.2-9
+***
+Prove that n1, n2, n3, and n4 are pairwise relatively prime if and only if
+
+gcd(n1n2, n3n4) = gcd(n1n3, n2n4) = 1.
+
+Show more generally that n1, n2, ..., nk are pairwise relatively prime if and only if a set of ⌈lg k⌉ pairs of numbers derived from the ni are relatively prime.
+
### `Answer`
-UNSOLVED
+UNSOLVED
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C32-String-Matching/32.1.md b/C32-String-Matching/32.1.md
index b42f8fd5..dfbb8710 100644
--- a/C32-String-Matching/32.1.md
+++ b/C32-String-Matching/32.1.md
@@ -1,46 +1,54 @@
-### Exercises 32.1-1
-***
-Show the comparisons the naive string matcher makes for the pattern P = 0001 in the text T = 000010001010001.
-### `Answer`
-
-straightforward.
-
-
-### Exercises 32.1-2
-***
-Suppose that all characters in the pattern P are different. Show how to accelerate NAIVE-
STRING-MATCHER to run in time O(n) on an n-character text T.
-
-### `Answer`
-If p[i] dismatch T[j],next time trace back to j+1;That is,compare from p[0] and T[j+1].
-
-### Exercises 32.1-3
-***
-Suppose that pattern P and text T are randomly chosen strings of length m and n, respectively, from the d-ary alphabet Σd = {0, 1, . . . , d - 1}, where d ≥ 2. Show that the expected number of character-to-character comparisons made by the implicit loop in line 4 of the naive algorithm is
-
-
-
over all executions of this loop. (Assume that the naive algorithm stops comparing characters for a given shift once a mismatch is found or the entire pattern is matched.) Thus, for randomly chosen strings, the naive algorithm is quite efficient.
-### `Answer`
-It's a probability problem.
-
- assume we have to compare (n-m+1) times.
- a(n) b(n)
- each time: compare 1 1-1/d
- 2 1/d*(1-1/d)
- 3 (1/d)^2*(1-1/d)
- ... ...
- m (1/d)^(m-1)*(1-1/d)
- then wo can get the T(time) = (n-m+1)*[a(1)*b(1)+a(2)*b(2)+,,,+a(m)*b(m)]
- So we get the answer.
-
-
-
-### Exercises 32.1-4
-***
-Suppose we allow the pattern P to contain occurrences of a gap character ⋄ that can match
an arbitrary string of characters (even one of zero length). For example, the pattern ab⋄ba⋄c occurs in the text cabccbacbacab as
-
-
Note that the gap character may occur an arbitrary number of times in the pattern but is assumed not to occur at all in the text. Give a polynomial-time algorithm to determine if such a pattern P occurs in a given text T , and analyze the running time of your algorithm.
-
-### `Answer`
-To determine if a pattern P with gap characters exists in T partition P into substrings P1 , . . . , Pk determined by the gap characters. Search for P1 and if found continue searching for P2 and so on. This clearly find a pattern if one exists.
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+### Exercises 32.1-1
+***
+Show the comparisons the naive string matcher makes for the pattern P = 0001 in the text T = 000010001010001.
+
+### `Answer`
+
+straightforward.
+
+
+### Exercises 32.1-2
+***
+Suppose that all characters in the pattern P are different. Show how to accelerate NAIVE-
+STRING-MATCHER to run in time O(n) on an n-character text T.
+
+### `Answer`
+If p[i] dismatch T[j],next time trace back to j+1;That is,compare from p[0] and T[j+1].
+
+### Exercises 32.1-3
+***
+Suppose that pattern P and text T are randomly chosen strings of length m and n, respectively, from the d-ary alphabet Σd = {0, 1, . . . , d - 1}, where d ≥ 2. Show that the expected number of character-to-character comparisons made by the implicit loop in line 4 of the naive algorithm is
+
+
+
+over all executions of this loop. (Assume that the naive algorithm stops comparing characters for a given shift once a mismatch is found or the entire pattern is matched.) Thus, for randomly chosen strings, the naive algorithm is quite efficient.
+
+### `Answer`
+It's a probability problem.
+
+ assume we have to compare (n-m+1) times.
+ a(n) b(n)
+ each time: compare 1 1-1/d
+ 2 1/d*(1-1/d)
+ 3 (1/d)^2*(1-1/d)
+ ... ...
+ m (1/d)^(m-1)*(1-1/d)
+ then wo can get the T(time) = (n-m+1)*[a(1)*b(1)+a(2)*b(2)+,,,+a(m)*b(m)]
+ So we get the answer.
+
+
+
+### Exercises 32.1-4
+***
+Suppose we allow the pattern P to contain occurrences of a gap character ⋄ that can match
+an arbitrary string of characters (even one of zero length). For example, the pattern ab⋄ba⋄c occurs in the text cabccbacbacab as
+
+
+
+Note that the gap character may occur an arbitrary number of times in the pattern but is assumed not to occur at all in the text. Give a polynomial-time algorithm to determine if such a pattern P occurs in a given text T , and analyze the running time of your algorithm.
+
+### `Answer`
+To determine if a pattern P with gap characters exists in T partition P into substrings P1 , . . . , Pk determined by the gap characters. Search for P1 and if found continue searching for P2 and so on. This clearly find a pattern if one exists.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C32-String-Matching/32.2.md b/C32-String-Matching/32.2.md
index 22c79acc..aaab5bdb 100644
--- a/C32-String-Matching/32.2.md
+++ b/C32-String-Matching/32.2.md
@@ -1,41 +1,45 @@
-### Exercises 32.2-1
-***
-Working modulo q = 11, how many spurious hits does the Rabin-Karp matcher encounter in
the text T = 3141592653589793 when looking for the pattern P = 26?
-### `Answer`
-
-15,59,92.
-
-So there are 3.
-
-
-### Exercises 32.2-2
-***
+### Exercises 32.2-1
+***
+Working modulo q = 11, how many spurious hits does the Rabin-Karp matcher encounter in
+the text T = 3141592653589793 when looking for the pattern P = 26?
+
+### `Answer`
+
+15,59,92.
+
+So there are 3.
+
+
+### Exercises 32.2-2
+***
How would you extend the Rabin-Karp method to the problem of searching a text string for an occurrence of any one of a given set of k patterns? Start by assuming that all k patterns have the same length. Then generalize your solution to allow the patterns to have different lengths.
-
-### `Answer`
-如果k个模式都是等长的,那么算法修改不大.用这些模式模p.然后跑正常的RK算法.遇到有出现在其中的就去匹配一下.
-
-如果不等长,可以按长度划分跑多次RK.
-
-### Exercises 32.2-3
-***
-Show how to extend the Rabin-Karp method to handle the problem of looking for a given m × m pattern in an n × n array of characters. (The pattern may be shifted vertically and horizontally, but it may not be rotated.)
-### `Answer`
-核心思想是reduce 2d to 1d.
-
-对长度为n每一列,我们都能根据RK算法计算出(n-m+1)个hash值.然后对每一行的连续的m个hash值,又能够根据RK的hash算法新算出一个值.
-
-也就是说,原来的RK是把算出长度为m的模式的hash值.而现在是先计算出m个长度为m的hash值,再对这m个hash值再一次hash.
-
-### Exercises 32.2-4
-***
-Alice has a copy of a long n-bit file A = , and Bob similarly has an n-bit file B = . Alice and Bob wish to know if their files are identical. To avoid transmitting all of A or B, they use the following fast probabilistic check. Together, they select a prime q > 1000n and randomly select an integer x from {0, 1, . . . , q - 1}. Then, Alice evaluates
-
-
-
-and Bob similarly evaluates B(x). Prove that if A ≠ B, there is at most one chance in 1000 that A(x) = B(x), whereas if the two files are the same, A(x) is necessarily the same as B(x). (Hint: See Exercise 31.4-4.)
-
-### `Answer`
-UNSOLVED
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+
+### `Answer`
+如果k个模式都是等长的,那么算法修改不大.用这些模式模p.然后跑正常的RK算法.遇到有出现在其中的就去匹配一下.
+
+如果不等长,可以按长度划分跑多次RK.
+
+### Exercises 32.2-3
+***
+Show how to extend the Rabin-Karp method to handle the problem of looking for a given m × m pattern in an n × n array of characters. (The pattern may be shifted vertically and horizontally, but it may not be rotated.)
+
+### `Answer`
+核心思想是reduce 2d to 1d.
+
+对长度为n每一列,我们都能根据RK算法计算出(n-m+1)个hash值.然后对每一行的连续的m个hash值,又能够根据RK的hash算法新算出一个值.
+
+也就是说,原来的RK是把算出长度为m的模式的hash值.而现在是先计算出m个长度为m的hash值,再对这m个hash值再一次hash.
+
+### Exercises 32.2-4
+***
+Alice has a copy of a long n-bit file A = , and Bob similarly has an n-bit file B = . Alice and Bob wish to know if their files are identical. To avoid transmitting all of A or B, they use the following fast probabilistic check. Together, they select a prime q > 1000n and randomly select an integer x from {0, 1, . . . , q - 1}. Then, Alice evaluates
+
+
+
+and Bob similarly evaluates B(x). Prove that if A ≠ B, there is at most one chance in 1000 that A(x) = B(x), whereas if the two files are the same, A(x) is necessarily the same as B(x). (Hint: See Exercise 31.4-4.)
+
+### `Answer`
+UNSOLVED
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C32-String-Matching/32.3.md b/C32-String-Matching/32.3.md
index 3b1b502a..d55bd9e9 100644
--- a/C32-String-Matching/32.3.md
+++ b/C32-String-Matching/32.3.md
@@ -1,35 +1,40 @@
-### Exercises 32.3-1
-***
-Construct the string-matching automaton for the pattern P = aabab and illustrate its operation on the text string T = aaababaabaababaab.
-### `Answer`
-run my program [FA.c](./FA.c) you will get the answer.
-
-
-### Exercises 32.3-2
-***
+### Exercises 32.3-1
+***
+Construct the string-matching automaton for the pattern P = aabab and illustrate its operation on the text string T = aaababaabaababaab.
+
+### `Answer`
+run my program [FA.c](./FA.c) you will get the answer.
+
+
+### Exercises 32.3-2
+***
Draw a state-transition diagram for a string-matching automaton for the pattern ababbabbababbababbabb over the alphabet Σ = {a, b}.
-
-### `Answer`
-run my program [FA.c](./FA.c) then you can draw the diagram.
-
-### Exercises 32.3-3
-***
-We call a pattern P nonoverlappable if Pk ⊐ Pq implies k = 0 or k = q. Describe the state- transition diagram of the string-matching automaton for a nonoverlappable pattern.
-### `Answer`
-这样子的模式产生的要么指向下一个状态,要么重新回到状态0.
-
-### Exercises 32.3-4 *
-***
-Given two patterns P and P′, describe how to construct a finite automaton that determines all
occurrences of either pattern. Try to minimize the number of states in your automaton.
-
-### `Answer`
-UNSOLVED
-
-### Exercises 32.3-5
-***
-Given a pattern P containing gap characters (see Exercise 32.1-4), show how to build a finite
automaton that can find an occurrence of P in a text T in O(n) matching time, where n = |T|.
-
-### `Answer`
-We can construct the finite automaton corresponding to a pattern P using the same idea as in exercise 32.1−4. Partition P into substrings P1, . . . , Pk determined by the gap characters. Construct finite automatons for each Pi and combine sequentially, i.e., the accepting state of Pi, i ∈ [1, k) is no longer accepting but has a single transition to Pi+1.
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+
+### `Answer`
+run my program [FA.c](./FA.c) then you can draw the diagram.
+
+### Exercises 32.3-3
+***
+We call a pattern P nonoverlappable if Pk ⊐ Pq implies k = 0 or k = q. Describe the state- transition diagram of the string-matching automaton for a nonoverlappable pattern.
+
+### `Answer`
+这样子的模式产生的要么指向下一个状态,要么重新回到状态0.
+
+### Exercises 32.3-4 *
+***
+Given two patterns P and P′, describe how to construct a finite automaton that determines all
+occurrences of either pattern. Try to minimize the number of states in your automaton.
+
+### `Answer`
+UNSOLVED
+
+### Exercises 32.3-5
+***
+Given a pattern P containing gap characters (see Exercise 32.1-4), show how to build a finite
+automaton that can find an occurrence of P in a text T in O(n) matching time, where n = |T|.
+
+### `Answer`
+We can construct the finite automaton corresponding to a pattern P using the same idea as in exercise 32.1−4. Partition P into substrings P1, . . . , Pk determined by the gap characters. Construct finite automatons for each Pi and combine sequentially, i.e., the accepting state of Pi, i ∈ [1, k) is no longer accepting but has a single transition to Pi+1.
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C32-String-Matching/32.4.md b/C32-String-Matching/32.4.md
index 8e8eaee9..e4275d77 100644
--- a/C32-String-Matching/32.4.md
+++ b/C32-String-Matching/32.4.md
@@ -1,47 +1,55 @@
-### Exercises 32.4-1
-***
-Compute the prefix function π for the pattern ababbabbabbababbabb when the alphabet is Σ = {a, b}.
-### `Answer`
-run my program [KMP.c](./KMP.c) you will get the answer.
-
-
-### Exercises 32.4-2
-***
+### Exercises 32.4-1
+***
+Compute the prefix function π for the pattern ababbabbabbababbabb when the alphabet is Σ = {a, b}.
+
+### `Answer`
+run my program [KMP.c](./KMP.c) you will get the answer.
+
+
+### Exercises 32.4-2
+***
Give an upper bound on the size of π*[q] as a function of q. Give an example to show that your bound is tight.
-
-### `Answer`
-Since π[q] < q we trivially have |π∗[q]| <= q. This bound is tight as illustrated by the string a^q. Here π[q] = q − 1, π(1)[q] = q − 2, and so on resulting in π∗[q] = {q − 1, . . . , 0}.
-
-### Exercises 32.4-3
-***
-Explain how to determine the occurrences of pattern P in the text T by examining the π
function for the string PT (the string of length m + n that is the concatenation of P and T).
-### `Answer`
-The indices in which P occurs in PT can be determined as the set M = {q | m ∈ π∗[q] and q >= 2m}.
-
-### Exercises 32.4-4
-***
-Show how to improve KMP-MATCHER by replacing the occurrence of π in line 7 (but not
line 12) by π′, where π′ is defined recursively for q = 1, 2, . . . , m by the equation
-
- 0 if π[q] = 0,
- π'[q] = π'[π[q]] if π[q] != 0 and p[π[q]+1] = p[q+1]
- π[q] if π[q] != 0 and p[π[q]+1] != p[q+1]
-
Explain why the modified algorithm is correct, and explain in what sense this modification constitutes an improvement.
-
-### `Answer`
-本质上和原算法是一样的,就是可以快速的推进,按最大的距离推进.
-
-### Exercises 32.4-5
-***
-Give a linear-time algorithm to determine if a text T is a cyclic rotation of another string T′. For example, arc and car are cyclic rotations of each other.
-
-### `Answer`
-[implementation](./exercise_code/str_spin.c)
-
-### Exercises 32.4-6 *
-***
-Give an efficient algorithm for computing the transition function δ for the string-matching automaton corresponding to a given pattern P. Your algorithm should run in time O(m |Σ|). (Hint: Prove that δ(q, a) = δ(π[q], a) if q = m or P[q + 1] ≠ a.)
-
-### `Answer`
-UNSOLVED
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+
+### `Answer`
+Since π[q] < q we trivially have |π∗[q]| <= q. This bound is tight as illustrated by the string a^q. Here π[q] = q − 1, π(1)[q] = q − 2, and so on resulting in π∗[q] = {q − 1, . . . , 0}.
+
+### Exercises 32.4-3
+***
+Explain how to determine the occurrences of pattern P in the text T by examining the π
+function for the string PT (the string of length m + n that is the concatenation of P and T).
+
+### `Answer`
+The indices in which P occurs in PT can be determined as the set M = {q | m ∈ π∗[q] and q >= 2m}.
+
+### Exercises 32.4-4
+***
+Show how to improve KMP-MATCHER by replacing the occurrence of π in line 7 (but not
+line 12) by π′, where π′ is defined recursively for q = 1, 2, . . . , m by the equation
+
+ 0 if π[q] = 0,
+ π'[q] = π'[π[q]] if π[q] != 0 and p[π[q]+1] = p[q+1]
+ π[q] if π[q] != 0 and p[π[q]+1] != p[q+1]
+
+
+
+Explain why the modified algorithm is correct, and explain in what sense this modification constitutes an improvement.
+
+### `Answer`
+本质上和原算法是一样的,就是可以快速的推进,按最大的距离推进.
+
+### Exercises 32.4-5
+***
+Give a linear-time algorithm to determine if a text T is a cyclic rotation of another string T′. For example, arc and car are cyclic rotations of each other.
+
+### `Answer`
+[implementation](./exercise_code/str_spin.c)
+
+### Exercises 32.4-6 *
+***
+Give an efficient algorithm for computing the transition function δ for the string-matching automaton corresponding to a given pattern P. Your algorithm should run in time O(m |Σ|). (Hint: Prove that δ(q, a) = δ(π[q], a) if q = m or P[q + 1] ≠ a.)
+
+### `Answer`
+UNSOLVED
+
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C33-Computational-Geometry/33.1.md b/C33-Computational-Geometry/33.1.md
index f1fbeb84..b9138252 100644
--- a/C33-Computational-Geometry/33.1.md
+++ b/C33-Computational-Geometry/33.1.md
@@ -1,90 +1,94 @@
-### Exercises 33.1-1
-***
-Prove that if p1 × p2 is positive, then vector p1 is clockwise from vector p2 with respect to the origin (0, 0) and that if this cross product is negative, then p1 is counterclockwise from p2.
-### `Answer`
-
-cross-product是一个三维的概念,根据右手规则,若p1在p2的顺时针方向,右手握住拇指出纸面,这时候的面积是正的;否则,面积是负的.
-
-
-### Exercises 33.1-2
-***
+### Exercises 33.1-1
+***
+Prove that if p1 × p2 is positive, then vector p1 is clockwise from vector p2 with respect to the origin (0, 0) and that if this cross product is negative, then p1 is counterclockwise from p2.
+
+### `Answer`
+
+cross-product是一个三维的概念,根据右手规则,若p1在p2的顺时针方向,右手握住拇指出纸面,这时候的面积是正的;否则,面积是负的.
+
+
+### Exercises 33.1-2
+***
Professor Powell proposes that only the x-dimension needs to be tested in line 1 of ON- SEGMENT. Show why the professor is wrong.
-
-### `Answer`
-如何一条直线是竖直的话,不仅要检查x值,还要检查y值.
-
-If a line is vertical, it's not enough to check x-value, y-valuealso needs checking.
-
-### Exercises 33.1-3
-***
-The polar angle of a point p1 with respect to an origin point p0 is the angle of the vector p1 - p0 in the usual polar coordinate system. For example, the polar angle of (3, 5) with respect to (2, 4) is the angle of the vector (1, 1), which is 45 degrees or π/4 radians. The polar angle of (3, 3) with respect to (2, 4) is the angle of the vector (1, -1), which is 315 degrees or 7π/4 radians. Write pseudocode to sort a sequence [p1, p2, ..., pn] of n points according to their polar angles with respect to a given origin point p0. Your procedure should take O(n lg n) time and use cross products to compare angles.
-### `Answer`
-Here is the basic idea : if we could define the compare function in points by cross product, we could adopt methods like quicksort to sort the points.
-
-* if p1 > 0, p2 < 0, then p1 < p2.
-* else if p1 < 0, p2 > 0, then p1 > p2.
-* else if crossproduct(p1, p2) > 0, then p1 < p2
-* else p1 > p2
-
-Once we define this compare function, we could call **sort** in the `algorithm` standard library and pass this function as a parameter.
-
-Here is my [implementation](./exercise_code/polarCMP.cpp)
-
-### Exercises 33.1-4
-***
-Show how to determine in O(n2 lg n) time whether any three points in a set of n points are collinear.
-
-### `Answer`
-Show how to determine if three point are collinear in a set of n points. For each point p0 sort the n − 1 other points according to the polar angle with respect to p. If two points p1 and p2 have the same polar angle then p0, p1 and p2 are collinear. This can approach can be implemented in O(n2 lg n).
-
-For conveience, we will ignore the case in which two points may have same coordinate.
-
+
+### `Answer`
+如何一条直线是竖直的话,不仅要检查x值,还要检查y值.
+
+If a line is vertical, it's not enough to check x-value, y-valuealso needs checking.
+
+### Exercises 33.1-3
+***
+The polar angle of a point p1 with respect to an origin point p0 is the angle of the vector p1 - p0 in the usual polar coordinate system. For example, the polar angle of (3, 5) with respect to (2, 4) is the angle of the vector (1, 1), which is 45 degrees or π/4 radians. The polar angle of (3, 3) with respect to (2, 4) is the angle of the vector (1, -1), which is 315 degrees or 7π/4 radians. Write pseudocode to sort a sequence [p1, p2, ..., pn] of n points according to their polar angles with respect to a given origin point p0. Your procedure should take O(n lg n) time and use cross products to compare angles.
+
+### `Answer`
+Here is the basic idea : if we could define the compare function in points by cross product, we could adopt methods like quicksort to sort the points.
+
+* if p1 > 0, p2 < 0, then p1 < p2.
+* else if p1 < 0, p2 > 0, then p1 > p2.
+* else if crossproduct(p1, p2) > 0, then p1 < p2
+* else p1 > p2
+
+Once we define this compare function, we could call **sort** in the `algorithm` standard library and pass this function as a parameter.
+
+Here is my [implementation](./exercise_code/polarCMP.cpp)
+
+### Exercises 33.1-4
+***
+Show how to determine in O(n2 lg n) time whether any three points in a set of n points are collinear.
+
+### `Answer`
+Show how to determine if three point are collinear in a set of n points. For each point p0 sort the n − 1 other points according to the polar angle with respect to p. If two points p1 and p2 have the same polar angle then p0, p1 and p2 are collinear. This can approach can be implemented in O(n2 lg n).
+
+For conveience, we will ignore the case in which two points may have same coordinate.
+
Here is my [implementation](./exercise_code/colinear.cpp)
-
-### Exercises 33.1-5
-***
-A polygon is a piecewise-linear, closed curve in the plane. That is, it is a curve ending on itself that is formed by a sequence of straight-line segments, called the sides of the polygon. A point joining two consecutive sides is called a vertex of the polygon. If the polygon is simple, as we shall generally assume, it does not cross itself. The set of points in the plane enclosed by a simple polygon forms the interior of the polygon, the set of points on the polygon itself forms its boundary, and the set of points surrounding the polygon forms its exterior. A simple polygon is convex if, given any two points on its boundary or in its interior, all points on the line segment drawn between them are contained in the polygon's boundary or interior.
-
Professor Amundsen proposes the following method to determine whether a sequence {p0, p1, ..., pn-1} of n points forms the consecutive vertices of a convex polygon. Output "yes" if the set {angle pi pi+1 pi+2 : i = 0, 1, ..., n - 1}, where subscript addition is performed modulo n, does not contain both left turns and right turns; otherwise, output "no." Show that although this method runs in linear time, it does not always produce the correct answer. Modify the professor's method so that it always produces the correct answer in linear time.
-
### `Answer`
-For example, Point(0,0)(1,1)(2,2) form a line not a polygon. But it does not contain both left turns and right turns so Professor Amundsen will say "yes".
-
-So, if these is no left turn or right turn, then say "no". Only if left turn occurs or right turn occurs will we say "yes".
-
-[implementation](./exercise_code/convex_polygon.cpp)
-
-### Exercises 33.1-6
-***
-Given a point p0 = (x0, y0), the right horizontal ray from p0 is the set of points {pi = (xi, yi) : xi ≥ x0 and yi = y0}, that is, it is the set of points due right of p0 along with p0 itself. Show how to determine whether a given right horizontal ray from p0 intersects a line segment p1p2 in O(1) time by reducing the problem to that of determining whether two line segments intersect.
-
-### `Answer`
-The tricky part is how to find an `end` point in the ray. We follow this strategy : The y-coordinate of the end point is the same as p0(y0). We name `xmax = max(p1.x, p2.x)`, to prevent p0 and end-point are same, we set end.x = xmax + 1.
-
-Next, we can apply original algorithm on p0p`end` and p1p2.
-
-It is my [implementation](./exercise_code/ray_intersection.cpp).
-
-### Exercises 33.1-7
-***
-One way to determine whether a point p0 is in the interior of a simple, but not necessarily convex, polygon P is to look at any ray from p0 and check that the ray intersects the boundary of P an odd number of times but that p0 itself is not on the boundary of P. Show how to compute in Θ(n) time whether a point p0 is in the interior of an n-vertex polygon P. (Hint: Use Exercise 33.1-6. Make sure your algorithm is correct when the ray intersects the polygon boundary at a vertex and when the ray overlaps a side of the polygon.)
-
-### `Answer`
-The difficulty is how to deal with the case when the ray intersects the polygon boundary at a vertex and when the ray overlaps a side of the polygon. I adopt this strategy : when the case occurs, if the line is below my ray(that is to say, one of the y-coordinate < p0.y, and the other >= p0.y) the increase the interaction times else do not.
-
-see my [implementation](./exercise_code/pointpolygon.cpp)
-
-[reference](http://blog.csdn.net/hjh2005/article/details/9246967)
-
-### Exercises 33.1-8
-***
+
+### Exercises 33.1-5
+***
+A polygon is a piecewise-linear, closed curve in the plane. That is, it is a curve ending on itself that is formed by a sequence of straight-line segments, called the sides of the polygon. A point joining two consecutive sides is called a vertex of the polygon. If the polygon is simple, as we shall generally assume, it does not cross itself. The set of points in the plane enclosed by a simple polygon forms the interior of the polygon, the set of points on the polygon itself forms its boundary, and the set of points surrounding the polygon forms its exterior. A simple polygon is convex if, given any two points on its boundary or in its interior, all points on the line segment drawn between them are contained in the polygon's boundary or interior.
+
+Professor Amundsen proposes the following method to determine whether a sequence {p0, p1, ..., pn-1} of n points forms the consecutive vertices of a convex polygon. Output "yes" if the set {angle pi pi+1 pi+2 : i = 0, 1, ..., n - 1}, where subscript addition is performed modulo n, does not contain both left turns and right turns; otherwise, output "no." Show that although this method runs in linear time, it does not always produce the correct answer. Modify the professor's method so that it always produces the correct answer in linear time.
+
+### `Answer`
+For example, Point(0,0)(1,1)(2,2) form a line not a polygon. But it does not contain both left turns and right turns so Professor Amundsen will say "yes".
+
+So, if these is no left turn or right turn, then say "no". Only if left turn occurs or right turn occurs will we say "yes".
+
+[implementation](./exercise_code/convex_polygon.cpp)
+
+### Exercises 33.1-6
+***
+Given a point p0 = (x0, y0), the right horizontal ray from p0 is the set of points {pi = (xi, yi) : xi ≥ x0 and yi = y0}, that is, it is the set of points due right of p0 along with p0 itself. Show how to determine whether a given right horizontal ray from p0 intersects a line segment p1p2 in O(1) time by reducing the problem to that of determining whether two line segments intersect.
+
+### `Answer`
+The tricky part is how to find an `end` point in the ray. We follow this strategy : The y-coordinate of the end point is the same as p0(y0). We name `xmax = max(p1.x, p2.x)`, to prevent p0 and end-point are same, we set end.x = xmax + 1.
+
+Next, we can apply original algorithm on p0p`end` and p1p2.
+
+It is my [implementation](./exercise_code/ray_intersection.cpp).
+
+### Exercises 33.1-7
+***
+One way to determine whether a point p0 is in the interior of a simple, but not necessarily convex, polygon P is to look at any ray from p0 and check that the ray intersects the boundary of P an odd number of times but that p0 itself is not on the boundary of P. Show how to compute in Θ(n) time whether a point p0 is in the interior of an n-vertex polygon P. (Hint: Use Exercise 33.1-6. Make sure your algorithm is correct when the ray intersects the polygon boundary at a vertex and when the ray overlaps a side of the polygon.)
+
+### `Answer`
+The difficulty is how to deal with the case when the ray intersects the polygon boundary at a vertex and when the ray overlaps a side of the polygon. I adopt this strategy : when the case occurs, if the line is below my ray(that is to say, one of the y-coordinate < p0.y, and the other >= p0.y) the increase the interaction times else do not.
+
+see my [implementation](./exercise_code/pointpolygon.cpp)
+
+[reference](http://blog.csdn.net/hjh2005/article/details/9246967)
+
+### Exercises 33.1-8
+***
Show how to compute the area of an n-vertex simple, but not necessarily convex, polygon in Θ(n) time. (See Exercise 33.1-5 for definitions pertaining to polygons.)
-
-### `Answer`
-To calculate the area of an arbitary polygon, we can divide the polygon into a number of triangles.
-
-
-Then we calculate the area of each triangle and add them.
-
+
+### `Answer`
+To calculate the area of an arbitary polygon, we can divide the polygon into a number of triangles.
+
+
+Then we calculate the area of each triangle and add them.
+
Here is the [code](./exercise_code/area.cpp).
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/C35-Approximation-Algorithms/35.1.md b/C35-Approximation-Algorithms/35.1.md
index c1e5841c..288730ba 100644
--- a/C35-Approximation-Algorithms/35.1.md
+++ b/C35-Approximation-Algorithms/35.1.md
@@ -1,17 +1,19 @@
-### Exercises 35.1-1
-***
-Give an example of a graph for which APPROX-VERTEX-COVER always yields a suboptimal solution.
-### `Answer`
-
-A graph with two node u,v and an edge(u,v). The optimal is either u or v. By running
-APPROX-VERTEX-COVER we get u and v. It is always a suboptimal solution.
-
-### Exercises 35.1-2
-***
-Let A denote the set of edges that were picked in line 4 of APPROX-VERTEX-COVER.
Prove that the set A is a maximal matching in the graph G.
+### Exercises 35.1-1
+***
+Give an example of a graph for which APPROX-VERTEX-COVER always yields a suboptimal solution.
-### `Answer`
+### `Answer`
+
+A graph with two node u,v and an edge(u,v). The optimal is either u or v. By running
+APPROX-VERTEX-COVER we get u and v. It is always a suboptimal solution.
+
+### Exercises 35.1-2
+***
+Let A denote the set of edges that were picked in line 4 of APPROX-VERTEX-COVER.
+Prove that the set A is a maximal matching in the graph G.
+
+### `Answer`
It is obvious. Because in line 4, we randomly choose an edge (u,v) and delete all edges incident on either u or v. The remaining graph becomes a subproblem.
-***
-Follow [@louis1992](https://github.com/gzc) on github to help finish this task.
\ No newline at end of file
+***
+Follow [@louis1992](https://github.com/gzc) on github to help finish this task
diff --git a/README.md b/README.md
index 49cc9250..e961789a 100644
--- a/README.md
+++ b/README.md
@@ -313,9 +313,9 @@ If a problem is too easy to solve, we'll mark it as **straightforward** in order
***
-##Data Structure&algorithm implementation
+## Data Structure&algorithm implementation
-###BASIC
+### BASIC
* [Heap](./C06-Heapsort/heap.cpp)
* [Priority Queue](./C06-Heapsort/p_queue.h)
* [Quicksort](./C07-Quicksort/quicksort.py)
@@ -324,11 +324,11 @@ If a problem is too easy to solve, we'll mark it as **straightforward** in order
* [K-th Finding](./C09-Medians-and-Order-Statistics/worst-case-linear-time.cpp)
* [Deque(py)](./C10-Elementary-Data-Structures/exercise_code/deque.py) [Deque(c++)](./C10-Elementary-Data-Structures/exercise_code/deque.cpp)
-###DIVIDE and CONQUER
+### DIVIDE and CONQUER
* [Karatsuba](./other/Karatsuba)
-###TREE/ADVANCED
+### TREE/ADVANCED
* [BST](./C12-Binary-Search-Trees/BSTree.h)
* [RBT](./C13-Red-Black-Trees/rbtree.cpp)
* [Btree](./C18-B-Trees/btree.cpp)
@@ -336,26 +336,26 @@ If a problem is too easy to solve, we'll mark it as **straightforward** in order
* [UnionFind](./C21-Data-Structures-for-Disjoint-Sets/uf.cpp)
* [SegmentTree](./other/segmentTree.cpp)
-###DYNAMIC/GREEDY
+### DYNAMIC/GREEDY
* [Matrix Chain](./C15-Dynamic-Programming/Matrix-chain-multiplication.c)
* [Huffman](./C16-Greedy-Algorithms/huffman)
-###GRAPH
+### GRAPH
* [Kosaraju's Algorithm ( strongly connected components )](./C22-Elementary-Graph-Algorithms/elementary_graph_algo.py#L70)
* [Maximum Flow](./C26-Flow-networks/maxflow)
* [Floyd-Warshall](./C25-All-Pairs-Shortest-Paths/Floyd_Warshall.cpp)
-###GEOMETRY
+### GEOMETRY
* [LineIntersection](./C33-Computational-Geometry/twoline.cpp)
* Convex Hull
* [Graham Scan](./C33-Computational-Geometry/Graham_Scan.py)
-###STRING
+### STRING
* [BruteForce](./C32-String-Matching/BF.c)
* [KMP](./C32-String-Matching/KMP.c)
* [DFA](./C32-String-Matching/FA.c)
-#UNSOLVED
+# UNSOLVED
[24.4.9](./C24-Single-Source-Shortest-Paths/24.4.md#exercises-244-9)