-
Notifications
You must be signed in to change notification settings - Fork 5
/
openapi-fixed.json
15353 lines (15353 loc) · 536 KB
/
openapi-fixed.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
{
"openapi": "3.0.3",
"info": {
"title": "Carbon",
"description": "Connect external data to LLMs, no matter the source.",
"version": "1.0.0",
"x-logo": {
"url": "https://i.ibb.co/qBqT3Ft/Group-14-1.png"
},
"x-konfig-ignore": {
"object-with-no-properties": true
}
},
"servers": [
{
"url": "https://api.carbon.ai"
}
],
"tags": [
{
"description": "\nEmploy these endpoints when syncing files from external data sources outside of Carbon Connect.\n",
"name": "Integrations"
},
{
"description": "\n---\nUtilize these API endpoints to manage user documents. Whether the data is sourced from third-party integrations, web pages, or file uploads, Carbon maintains consistency by standardizing all documents as \"files\" within our data model.\n\nCarbon supports the following file formats:\n\n### Text\n- `pdf`\n- `xlsx`\n- `csv`\n- `docx`\n- `txt`\n- `md`\n- `rtf`\n- `tsv`\n- `pptx`\n- `json` (Coming Soon)\n\n### Audio\n- `mp3`\n- `mp4`\n- `mp2`\n- `aac`\n- `wav`\n- `flac`\n- `pcm`\n- `m4a`\n- `ogg`\n- `opus`\n- `webm`\n\n### Images\n- `jpg`\n- `png`\n",
"name": "Files"
},
{
"description": "\n---\nLeverage these `Utilities` endpoints to execute a wide range of helpful actions, including initiating web scraping, processing sitemaps, retrieving URLs from a specific webpage, obtaining relevant URLs based on a search query, fetching YouTube video transcripts, and many other functionalities.\n",
"name": "Utilities"
},
{
"name": "CRM"
},
{
"name": "Github"
},
{
"description": "\n---\n",
"name": "Users"
},
{
"description": "\n---\nCarbon facilitates user connections and content synchronization with third-party applications. We manage authentication, ingestion, parsing, and sync scheduling. Within Carbon, content from third-party applications is uniformly categorized as \"files\" within our data model. \n\nCarbon also supports websites as a data source (see [here](https://api.carbon.ai/redoc#tag/Data-Sources/operation/web_scrape_web_scrape_post)).\n\n# Google Drive\nThe Carbon Connect `enabledIntegrations` value for Google Drive is `GOOGLE_DRIVE`. Google Slides, Google Docs and Google Sheets are supported with our Google Drive integration, along with regular text, audio and image files.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://developers.google.com/identity/protocols/oauth2)** to connect to Google workspace.\n\n## Authorization Flow\n\n**Carbon's Google Drive integration is still pending approval from Google. In the meantime, end users are required to take a couple additional steps to connect their accounts (see gif below).**\n\n\n\nLog into your Google Drive account.\n\n\nOnce you've successfully authenticated your account, you can select files directly.\n\n\nClick \"Select\" after selecting files to grant Carbon access to files.\n\n\n\n## Configuration\n\n### Custom OAuth Credentials\n\n1. Go to `APIs and Services` > `Enabled APIs and Services` in your Google Cloud console, then click on the button titled `ENABLE APIS AND SERVICES` and enable `Google Drive API` and `Google Picker API`.\n2. Then create an `OAuth Client ID` in the `Credentials section` under `Google Drive API`. Select `Web Application` as the Application type and give it an identifiable name for your reference.\n\n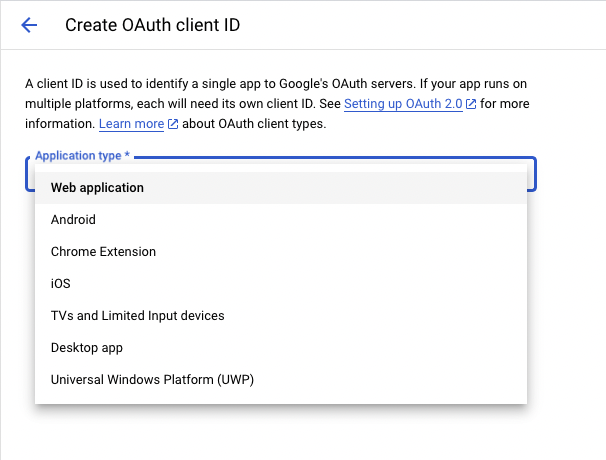\n\n3. Add [https://api.carbon.ai](https://api.carbon.ai/) as the `Authorized JS origin` and <https://api.carbon.ai/integrations/google> as an `Authorized redirect URI`.\n\n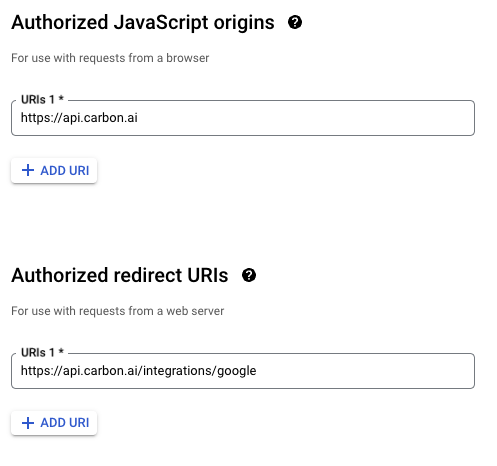\n\n4. Save the credentials. Download the credentials.json file once you save the OAuth Client ID data and share the file with Carbon.\n\n\n\n5. Then create an `API key` in the `Credentials section` under `Google Picker API`. Restrict the application to websites and then add [https://api.carbon.ai](https://api.carbon.ai/) to the list under website restrictions. For `API Restrictions`, pick `Restrict key` and select `Google Picker API` from the list.\n\n6. Save the API key. Copy the API key and share it with Carbon.\n\n7. Configure your consent screen in the OAuth Consent Screen. Provide your **App name**, **support email address**, and **brand logo**. Add [carbon.ai](http://carbon.ai/) to `Authorized domain`.\n\n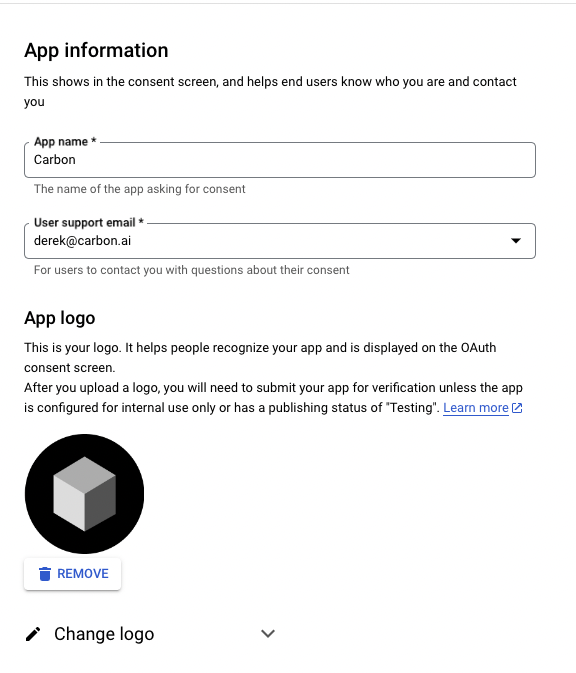\n\n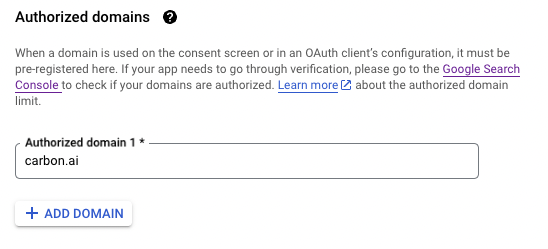\n\n\n8. Click on `Add or Remove Scopes` button to add the following scopes: `userinfo.profile`, `userinfo.email`, `drive.readonly`, `drive.metadata.readonly`\n\n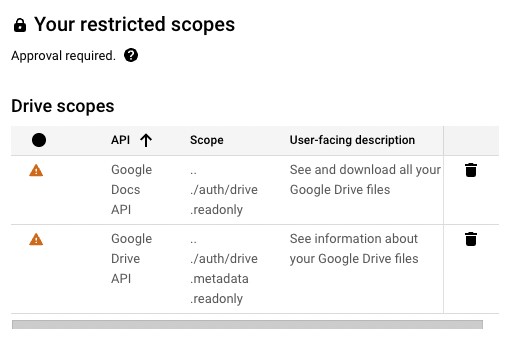\n\n\n9. If you wish to add test users, you can do so. These users will not see the \"App is unverified\" notification. Other users will see this alert.\n10. Click `Publish App` to make this app available to your end-users.\n\n\n\n## Synchronization\n\nSyncs are triggered when end-users add or remove Google Drive files and folders via the Google Drive picker. When a user selects a folder to be synced, we auto-sync all files added to the folder as well.\n\nYou can use the `resync_file` API endpoint to programmatically resync specific Google Drive files.\n\nIn addition, we have a 24-hour batch sync running in the background. You can request us via Slack to run more frequent batch syncs.\n\n# Dropbox\nThe Carbon Connect `enabledIntegrations` value for Dropbox is `DROPBOX`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://developers.dropbox.com/oauth-guide)** to connect to Dropbox.\n\n## Authorization Flow\n\nLog into your Dropbox account.\n\n\nOnce you've successfully authenticated your account, you can select files directly.\n\n\nClick \"Choose\" after selecting files to grant Carbon access to files.\n\n\n## Configuration\n\n### Custom OAuth Credentials\n\n1. Sign up on [Dropbox Developers](https://www.dropbox.com/developers) and create a new app with `Full Dropbox` access.\n\n\n\n2. Copy and share the `App key` and `App secret` under the `Settings` tab with us.\n\n\n\n3. Add <https://api.carbon.ai/integrations/dropbox> as a `Redirect URIs` and [carbon.ai](carbon.ai) as the `Chooser / Saver / Embedder domains`.\n\n\n\n4. Configure your app details under the `Branding` tab. These details will appear on the OAuth Consent Screen as well. Provide your **App name**, **Publisher**, and **App icons**. \n\n\n\n5. Under the `Permissions` tab, add the following scopes: `account_info.read`, `files.metadata.read`, and `files.content.read`.\n\n\n\n6. Click `Apply for Production` under the `Settings` tab to make this app available to your end-users.\n\n## Functionality\n\nCarbon allows users to upload `pdf`, `docx`, `pptx`,`txt`,`csv`, `png`, `rtf`, `tsv`, `xlsx`, `jpeg` and `md` files directly from Dropbox.\n\n## Synchronization\n\nSyncs are triggered when end-users select files to upload via the Dropbox file selector UI. You can also use the `resync_file` API endpoint to programmatically resync specific Dropbox files. To delete Dropbox files from Carbon, you can use the `deletefile` endpoint directly.\n\nWe do not run our 24-hour batch sync for Dropbox by default. If you'd like us to enable batch syncs to run in the background, you can request this via Slack.\n\n# Intercom\n\nThe Carbon Connect `enabledIntegrations` value for Intercom is `INTERCOM`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://developers.intercom.com/building-apps/docs/setting-up-oauth)** to connect to Intercom workspaces.\n\n## Authorization Flow\n\n\n\n\n\n## Functionality\n\nCarbon syncs all `Published` articles under a single Intercom workspace. Any `Draft` article won't be synced. We currently support only having a single Intercom workspace connected per `customer_id`.\n\n## Configuration\n\n### Custom OAuth Credentials\n\n1. After you create or log into your [Intercom Developer](https://developers.intercom.com/) account, click `New App` to create your own app.\n\n\n\n2. Under the `Authentication` tab, click `Edit` -> `Use OAuth` -> `Add redirect URL` and then enter https://api.carbon.ai/integrations/intercom.\n\n\n\n3. Under the `Authentication` tab, click `Edit` and then add permissions for `Read one admin`, `Read and List Articles`, and `Read and Write Articles`. You can remove access to the other permissions.\n\n\n\n4. Under the `Basic Info` tab, share the `Client ID` and `Client secret` with us via Slack.\n\n\n\n5. Under the `Basic Info` tab, add an `App icon` and `App name`.\n\n\n\n6. Click `Test and publish` -> `Submit for review` and fill in the details require to publish your app. After your app is approved, then we can enable the white labeling.\n\n\n\n\n## Synchronization\n\nSyncs are triggered when end-users add or remove pages via the Intercom OAuth flow. You can use the `resync_file` API endpoint to programmatically resync specific Intercom files.\n\nIn addition, we have a 24-hour batch sync running in the background. You can request us via Slack to run more frequent batch syncs.\n\n# Notion\n\nThe Carbon Connect `enabledIntegrations` value for Notion is `NOTION`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://developers.notion.com/docs/authorization)** to connect to Notion workspaces.\n\n## Authorization Flow\n\n\n\n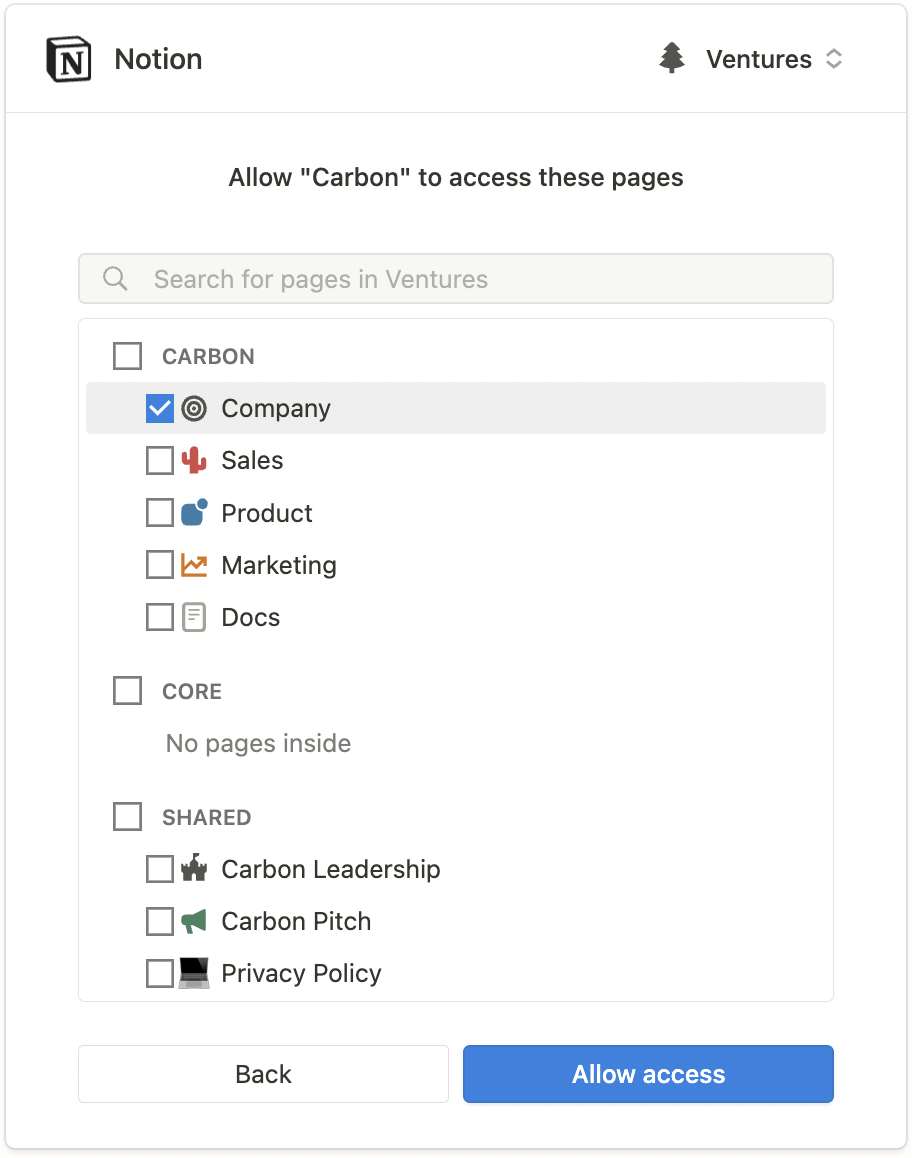\n\n## Functionality\n\nCarbon enables end-users to select top-level pages for synchronization and automatically syncs all sub-pages. For instance, a top-level Company page may contain sub-pages for **`Company Benefits`** and **`PTO Policy`**. Once the end-user selects the Company page in the Authorization flow, Carbon automatically includes the sub-pages **`Company Benefits`** or **`PTO Policy`** to be synced.\n\n## Synchronization\n\nSyncs are triggered when end-users add or remove pages via the Notion OAuth flow. You can use the `resync_file` API endpoint to programmatically resync specific Notion files.\n\nIn addition, we have a 24-hour batch sync running in the background. You can request us via Slack to run more frequent batch syncs. \n\nWhen a user adds a nested page or database record under a selected Notion page, we auto-sync those documents as well.\n\n# OneDrive\n\nThe Carbon Connect `enabledIntegrations` value for OneDrive is `ONEDRIVE`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://learn.microsoft.com/en-us/onedrive/developer/rest-api/getting-started/msa-oauth?view=odsp-graph-online)** to connect to OneDrive.\n\n## Authorization Flow\n\nLog into your Microsoft account.\n\n\nClick the \"Confirm\" button to grant us permission to access OneDrive.\n\n\nClick the \"Select Files from OneDrive\" button to open up the OneDrive file selector.\n\n\nClick \"Select\" after selecting files to grant Carbon access to files.\n\n\n## Configuration\n\n### Custom OAuth Credentials\n\n#### Setting up the OAuth App\n\n1. Create or log into your [Microsoft Azure](https://portal.azure.com/) Account.\n\n2. Under `Azure Services`, select `App Registration` -> `New registration`.\n\n\n\n3. Select `Accounts in any organizational directory (Any Microsoft Entra ID tenant - Multitenant) and personal Microsoft accounts (e.g. Skype, Xbox)` as the `Supported account types`.\n\n\n\n4. Add https://api.carbon.ai/integrations/onedrive as the `Redirect URI` and select `Web` under the `Select a platform` dropdown. You can also opt to use a custom CNAME record pointing to https://api.carbon.ai. The domain path must still be `/integrations/onedrive`.\n\n\n\n5. Under `Manage` -> `API permissions` add the permissions `Files.Read.All`, `offline_access`, `openid`, and `User.Read`.\n\n\n\n6. Under `Client credentials`, click `Add a certificate or secret` -> `New Client Secret`. Then copy the client secret’s `Value` and share it with us via Slack.\n\n\n\n7. Navigate to the `Overview` tab then copy the `Application (client) ID` and share it with us via Slack.\n\n\n\n8. Customize your app branding under `Manage` -> `Branding & properties`.\n\n\n\n#### Setting up the File Picker UI\n\n1. Under `Azure Services`, select `App Registration` -> `New registration`.\n\n\n\n2. Select `Accounts in any organizational directory (Any Microsoft Entra ID tenant - Multitenant) and personal Microsoft accounts (e.g. Skype, Xbox)` as the `Supported account types`.\n\n\n\n3. Under the `Authentication` tab, select `Add a Platform` -> `Single Page Application`. \n\n\n\n4. For the `Redirect URI` of the `Single Page Application`, you can use https://api.carbon.ai/static/loading.html or add a custom CNAME record pointing to https://api.carbon.ai. The domain path must still be `/static/loading.html`.\n\n\n\n5. Under the `Authentciation`'s `Implicit grant and hybrid flows` section, check `Access tokens (used for implicit flows)` and `ID tokens (used for implicit and hybrid flows)`.\n\n\n\n6. Under `Manage` -> `API permissions` add the permissions `Files.Read.All`, `Sites.Read.All`, `User.Read`, `AllSites.Read`, and `MyFiles.Read`.\n\n\n\n7. Under `Client credentials`, click `Add a certificate or secret` -> `New Client Secret`. Then copy the client secret’s `Value` and share it with us via Slack.\n\n\n\n8. Navigate to the `Overview` tab then copy the `Application (client) ID` and share it with us via Slack.\n\n## Functionality\n\nCarbon allows users to upload `pdf`, `docx`, `pptx`,`txt`,`csv`, `png`, `rtf`, `tsv`, `xlsx`, `jpeg` and `md` files directly from OneDrive.\n\n## Synchronization\n\nSyncs are triggered when end-users select files to upload via the OneDrive file selector UI. You can also use the `resync_file` API endpoint to programmatically resync specific OneDrive files. To delete OneDrive files from Carbon, you can use the `deletefile` endpoint directly.\n\nWe do not run our 24-hour batch sync for OneDrive by default. If you'd like us to enable batch syncs to run in the background, you can request this via Slack.\n\n# SharePoint\n\nThe Carbon Connect `enabledIntegrations` value for SharePoint is `SHAREPOINT`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://learn.microsoft.com/en-us/onedrive/developer/rest-api/getting-started/msa-oauth?view=odsp-graph-online)** to connect to SharePoint.\n\n## Authorization Flow\n\nEnter your Sharepoint `tenant` and `site name`. For example, if the SharePoint site URL is `https://jasoncarbon.sharepoint.com/sites/carbon-dev`, `jasoncarbon` is the tenant and `carbon-dev` is the site name.\n\n\n\nLog into your Microsoft SharePoint account.\n\n\nClick the \"Confirm\" button to grant us permission to access SharePoint.\n\n\nOnce clicking \"Confirm\", you will be taken through a flow to grant permissions.\n\n\nClick the \"Select Files from SharePoint\" button to open up the SharePoint file selector.\n\n\nClick \"Select\" after selecting files to grant Carbon access to files.\n\n\nYou'll see a screen confirming that your files have been added.\n\n\n## Configuration\n\n### Custom OAuth Credentials\n\n#### Setting up the OAuth App\n\n1. Create or log into your [Microsoft Azure](https://portal.azure.com/) Account.\n\n2. Under `Azure Services`, select `App Registration` -> `New registration`.\n\n\n\n3. Select `Accounts in any organizational directory (Any Microsoft Entra ID tenant - Multitenant) and personal Microsoft accounts (e.g. Skype, Xbox)` as the `Supported account types`.\n\n\n\n4. Add https://api.carbon.ai/integrations/onedrive and https://api.carbon.ai/integrations/sharepoint to `Redirect URI` and select `Web` under the `Select a platform` dropdown. You can also opt to use a custom CNAME record pointing to https://api.carbon.ai. The domain paths must still be `/integrations/onedrive` and `/integrations/sharepoint`.\n\n\n\n5. Under `Manage` -> `API permissions` add the permissions `Files.Read.All`, `offline_access`, `openid`, and `User.Read`.\n\n\n\n6. Under `Client credentials`, click `Add a certificate or secret` -> `New Client Secret`. Then copy the client secret’s `Value` and share it with us via Slack.\n\n\n\n7. Navigate to the `Overview` tab then copy the `Application (client) ID` and share it with us via Slack.\n\n\n\n8. Customize your app branding under `Manage` -> `Branding & properties`.\n\n\n\n#### Setting up the File Picker UI\n\n1. Under `Azure Services`, select `App Registration` -> `New registration`.\n\n\n\n2. Select `Accounts in any organizational directory (Any Microsoft Entra ID tenant - Multitenant) and personal Microsoft accounts (e.g. Skype, Xbox)` as the `Supported account types`.\n\n\n\n3. Under the `Authentication` tab, select `Add a Platform` -> `Single Page Application`. \n\n\n\n4. For the `Redirect URI` of the `Single Page Application`, you can use https://api.carbon.ai/static/loading.html or add a custom CNAME record pointing to https://api.carbon.ai. The domain path must still be `/static/loading.html`.\n\n\n\n5. Under the `Authentciation`'s `Implicit grant and hybrid flows` section, check `Access tokens (used for implicit flows)` and `ID tokens (used for implicit and hybrid flows)`.\n\n\n\n6. Under `Manage` -> `API permissions` add the permissions `Files.Read.All`, `Sites.Read.All`, `User.Read`, `AllSites.Read`, and `MyFiles.Read`.\n\n\n\n7. Under `Client credentials`, click `Add a certificate or secret` -> `New Client Secret`. Then copy the client secret’s `Value` and share it with us via Slack.\n\n\n\n8. Navigate to the `Overview` tab then copy the `Application (client) ID` and share it with us via Slack.\n\n## Functionality\n\nCarbon allows users to upload `pdf`, `docx`, `pptx`,`txt`,`csv`, `png`, `rtf`, `tsv`, `xlsx`, `jpeg` and `md` files directly from SharePoint.\n\n## Synchronization\n\nSyncs are triggered when end-users select files to upload via the SharePoint file selector UI. You can also use the `resync_file` API endpoint to programmatically resync specific SharePoint files. To delete SharePoint files from Carbon, you can use the `deletefile` endpoint directly.\n\nWe do not run our 24-hour batch sync for SharePoint by default. If you'd like us to enable batch syncs to run in the background, you can request this via Slack.\n\n# Zotero\n\nThe Carbon Connect `enabledIntegrations` value for ZOTERO is `ZOTERO`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 1.0](https://www.zotero.org/support/dev/web_api/v2/oauth)** to connect to Zotero.\n\n## Authorization Flow\n\nLog into your Zotero account. \n\n\nClick the \"Accept Defaults\" button to grant us permission to access Zotero.\n\n\nOnce clicking \"Accept Defaults\", all Zotero files are synced and you should see the following confirmation:\n\n\n## Configuration\n\n### Custom OAuth Credentials\n\n#### Setting up the OAuth App\n\n1. Create or log into your [Zotero](https://www.zotero.org/) Account.\n\n2. Click [here](https://www.zotero.org/oauth/apps) to set up your OAuth app.\n\n\n\n3. Click \"Register a New Application\" and fill out the info below. Add https://api.carbon.ai/integrations/zotero as the `Callback URL`. You can also opt to use a custom CNAME record pointing to https://api.carbon.ai. The domain path must still be `/integrations/zotero`.\n\n\n\n4. Copy and share the Client Key and Client Secret with Carbon.\n\n\n\n## Functionality\n\nCarbon allows users to upload `pdf`, `docx`, `pptx`,`txt`,`csv`, `png`, `rtf`, `tsv`, `xlsx`, `jpeg` and `md` files directly from Zotero.\n\n## Synchronization\n\nBy default, Carbon syncs all attachments from your Zotero library along with the accompanying info as metadata.\n\nYou can use the `resync_file` API endpoint to programmatically resync specific Zotero files. To delete Zotero files from Carbon, you can use the `deletefile` endpoint directly.\n\nWe do not run our 24-hour batch sync for Zotero by default. If you'd like us to enable batch syncs to run in the background, you can request this via Slack.\n\n# Box\n\nThe Carbon Connect `enabledIntegrations` value for Box is `BOX`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://developer.box.com/guides/authentication/oauth2/)** to connect to Box.\n\n## Authorization Flow\n\nLog into your Box account.\n\n\n\nClick the \"Select Files from Box\" button to open up the Box file selector.\n\n\nClick the checkmark after selecting files to grant Carbon access to files.\n\n*Limitations*: You can currently only upload individual file(s) via Box's file selector. If you'd like the ability the upload entire folders, please reach out to us on Slack. \n\n\n\nYou'll receive a confirmation that your file(s) has been uploaded.\n\n\n\n\n## Configuration\n\n### Custom OAuth Credentials\n\n1. Sign up for an account under [Box Developer](https://developer.box.com/).\n\n2. Go to `My Apps`, then `Create New App` -> `Choose Custom App`.\n\n\n\n2. Fill out the app details in the modal that opens.\n\n\n\n3. Select User Auth with OAuth 2.0 in the following step.\n\n\n\n4. In the `Configuration` tab copy and paste the `Client ID` and `Client Secret` and share it with us.\n\n\n\n5. Add https://api.carbon.ai/integrations/box as a `Redirect URIs` and https://api.carbon.ai as a `CORS Domains`\n\n\n\n\n7. For scopes, select `Read all files and folders stored in Box` and `Write all files and folders stored in Box`.\n\n\n\n8. In the `App Center` tab, you can edit your branding.\n\n\n\n9. Once you're ready, you can also submit your app for approval.\n\n\n\n## Functionality\n\nCarbon allows users to upload `pdf`, `docx`, `pptx`,`txt`,`csv`, `png`, `rtf`, `tsv`, `xlsx`, `jpeg` and `md` files directly from Box.\n\n## Synchronization\n\nSyncs are triggered when end-users select files to upload via the Box file selector UI. You can also use the `resync_file` API endpoint to programmatically resync specific Box files. To delete Box files from Carbon, you can use the `deletefile` endpoint directly.\n\nWe do not run our 24-hour batch sync for Box by default. If you'd like us to enable batch syncs to run in the background, you can request this via Slack.\n\n\n# Zendesk\nThe Carbon Connect `enabledIntegrations` value for Zendesk is `ZENDESK`.\n\n## Authorization Type\n\nCarbon uses **[OAuth 2.0](https://developers.Zendesk.com/building-apps/docs/setting-up-oauth)** to connect to Zendesk workspaces.\n\n## Authorization Flow\n\n\n\n\n\n\n\n## Functionality\n\nCarbon syncs all `Published` articles under a single Zendesk workspace. Any `Draft` article won't be synced. We currently support only having a single Zendesk workspace connected per `customer_id`.\n\n## Configuration\n\n### Custom OAuth Credentials\n\n1. In Admin Center, click the `Apps and integrations` icon and then in the sidebar, select `APIs` > `Zendesk` APIs.\n\n\n\n\n\n2. Click the `OAuth Clients` tab on the Zendesk API page, and then click `Add OAuth client` on the right side of the OAuth client list.\n\n\n\n3. Complete the following fields to create a client:\n- Client Name - Enter a name for your app. This is the name that users will see when asked to grant access to your application, and when they check the list of third-party apps that have access to their Zendesk.\nDescription - Optional. This is a short description of your app that users will see when asked to grant access to it.\n- Company - Optional. This is the company name that users will see when asked to grant access to your application. The information can help them understand who they're granting access to.\n- Logo - Optional. This is the logo that users will see when asked to grant access to your application. The image can be a JPG, GIF, or PNG. For best results, upload a square image. It will be resized for the authorization page.\n- Unique Identifier - The field is auto-populated with a reformatted version of the name you entered for your app. You can change it if you want.\n- Redirect URLs - Enter https://api.carbon.ai/integrations/zendesk here. You can also opt to use a custom CNAME record pointing to https://api.carbon.ai. The domain path must still be `/integrations/zendesk`.\n\n\n\n4. Click Save. After the page refreshes, a new pre-populated Secret field appears on the lower side. This is the `client_secret` value specified in the OAuth2 spec. Send us the `client_secret` value over Slack.\n6. Copy the Secret value to your clipboard and save it somewhere safe. Note: The characters may extend past the width of the text box, so make sure to select everything before copying.\n\n\n\n7. Copy the `Unique Identifier` of the OAuth app and share that value over Slack as well.\n8. In order for us to white-label your OAuth app, you need to request approval first to convert the app from a **local OAuth client** to **global OAuth client**. You can follow the instructions [here](https://developer.zendesk.com/documentation/marketplace/building-a-marketplace-app/set-up-a-global-oauth-client) to do so.\n\n## Synchronization\n\nSyncs are triggered when end-users add or remove pages via the Zendesk OAuth flow. You can use the `resync_file` API endpoint to programmatically resync specific Zendesk files.\n\nIn addition, we have a 24-hour batch sync running in the background. You can request us via Slack to run more frequent batch syncs.\n\n# Slack\n# Confluence\n",
"name": "Data Sources"
},
{
"description": "\n---\nEmploy these endpoints for direct vector searches within our managed vector database or to fetch embeddings for storage in your custom vector store. Additionally, we offer hybrid support for keyword-based searches.\n",
"name": "Embeddings"
},
{
"name": "White Label"
},
{
"description": "\n---\nCarbon offers a set of webhooks for a variety of events, listed below. Currently, there is no way to choose\nwhich events to receive webhooks for - it's on our roadmap to allow for more fine-grained filtering. The steps\nin setting up webhooks for your service are:\n1. Add a URL to which webhoooks should be sent. This can be done using the `/add_webhook` endpoint.\n2. Save the `signing_key` in the response somewhere safe - this can't be retrieved again.\n\nAt this point, all events will be sent to the URL specified in step 1. An event - sent via an HTTP POST\nrequest - contains two important elements, a `Carbon-Signature` header and a body with a single key-value pair.\nYou can validate the authenticity and integrity of the webhook by calculating its signature. To do this, you should:\n1. Extract the timestamp and signature.\n 1. Extract the timestamp and signature from the `Carbon-Signature` header. It will be of the form\n`Carbon-Signature:t=1492774577,v1=5257a869e7ecebeda32affa62cdca3fa51cad7e77a0e56ff536d0ce8e108d8bd`.\n 2. For those using JavaScript and decoding the request json via `JSON.stringify`, we suggest using the `Carbon-Signature-Compact`\nheader instead. It will have the form `Carbon-Signature:t=1492774577,v2=5257a869e7ecebeda32affa62cdca3fa51cad7e77a0e56ff536d0ce8e108d8bd`.\n2. Create a string of the form `{timestamp}.{request_body}`, where `request_body` is the entire request body.\nNote that all values in the webhook request body are coerced to strings - this is *intentional*.\n 1. If using `Carbon-Signature`, you can use `request_body` as is, or you can decode it as json. When decoding, ensure that the \nresulting json is formatted *exactly* as it is in `request_body`. In other words, the json should look like:\n```\n{\"x\": 5, \"y\": 6}\n```\n 2. If using `Carbon-Signature-V2`, when decoding the request body, ensure that the resulting json is in compact form, where there \nare no spaces between key-value pairs or between keys and values. For example,\n```\n{\"x\":5,\"y\":6}\n```\nGiven a request body, `x`, you can do this in Python via `json.dumps(x, separators=[\",\", \":\"])` or in JavaScript via `JSON.stringify(x)`.\n3. Compute an HMAC of the above string with the SHA256 hash function. Use `signing_key` obtained from the `/add_webhook` endpoint as the key.\n4. Compare the computed signature with the signature in the header (the value that `v1` - or `v2` - is equal to). If they're identical,\nyou can be assured that the webhook is both genuine and hasn't been tampered with.\n\nOnce you receive and handle the webhook, you should respond to the POST request with a 200 status - otherwise the webhook\nwill be retried (up to three times).\n\n### Webhooks for File Processing\n\nWe currently support the following webhook events for file processing:\n1. `FILE_READY`\n - Sent after a file has been fully processed and added to Carbon.\n2. `FILE_ERROR`\n - Sent if there was an error during the file processing stage. If an error occurred, the file is requeued for reprocessing\n up to three times.\n3. `FILE_DELETED`\n - Sent if a file has been successfully deleted.\n4. `FILES_CREATED`\n - Sent if files are being synced for the first time.\n5. `UPLOAD_ALL_QUEUED`\n - Sent when all files and folders in a uploaded batch have been queued for processing.\n6. `RATE_LIMIT_ERROR`\n - Sent if the organization has reached the rate limit for file processing. In this case, the file is requeued for reprocessing\n up to three times.\n\nThese are sent *after* a file has been processed.\n\n### Webhooks for Data Sources\n\nWe currently support the following webhook events for managing user connections to data sources:\n\n1. `ADD` \n - This event is fired when a user authenticates their account for a specific data source for the first time.\n\n2. `UPDATE` \n - This event is fired when a user selects one or more files for a particular data source. This event is fired once per file selection confirmation, regardless of how many files are selected.\n\n3. `CANCEL` \n - This event is fired when a user cancels the authentication flow. It's important to note that this event cannot capture tab-close events, so directly closing a tab is not within our tracking capabilities.\n\n4. `REVOKE`\n - This event is triggered when a user's data source connection is revoked via the `/revoke_access_token` endpoint.\n\nAn organization is allowed up to *3* webhook URLs. To delete an existing URL, you can use the `/delete_webhook` endpoint.\nTo view all existing webhooks, use the `/webhooks` endpoint.\n\nAll webhook payloads have the form\n```\n{\n \"payload\": str\n}\n```\nThe value of `payload` (which is a stringified json object) will always have the form\n```\n{\n \"webhook_type\": WebhookType,\n \"obj\": {\n \"object_type\": WebhookObjectType,\n \"object_id\": str,\n \"additional_information\": dict[str, str] | str\n },\n \"timestamp\": str\n}\n```\nNote that `WebhookType` is one of the webhook events described above. `WebhookObjectType` is limited to `FILE` currently.\n`additional_information` is always a dictionary of string-string key-value pairs, unless it's empty, in which case it is\nthe string value \"null\". Finally, `timestamp` is an int POSIX timestamp as a string. Note that to use `object_id` in\nsubsequent API requests, you'll likely need to convert it to an int.\n",
"name": "Webhooks"
},
{
"name": "Organizations"
},
{
"description": "\n---\n",
"name": "Auth"
},
{
"description": "\n---\n\n\n\n## What is Carbon?\n\nCarbon provides a comprehensive framework designed to streamline the process of connecting external data sources to Large Language Models (LLMs). \n\nThe Carbon search model is purpose-built for Large Language Models (LLMs) because of its fully neural architecture, enabling natural language querying across indexed documents from external data sources. In cases where vector (or neural) search isn't optimal, Carbon also supports keyword-based searches.\n\nCarbon simplifies the process of **retrieval augmented generation** (RAG), allowing you to spend more time using your data, and less time trying to ingest it.\n\n## How Carbon Works\n\nUse **[Carbon Connect](https://api.carbon.ai/redoc#tag/Carbon-Connect)** to connect to your users' data sources and then our **Universal API** to retrieve the data to use with LLMs. Carbon has native integrations with 10+ data sources and supports more than 20+ file formats, encompassing text, audio, and visual data.\n\nDepending on your use case and in-house infrastructure, you can retrieve user data from Carbon in several formats: \n\n- Parsed plaintext files\n- Embeddings (and chunks) to store in your vector store\n- Direct semantic and keyword search against Carbon's managed vector database\n\n## Products\n\n### 🔗 Connect\n\nA client-side component for users to connect data sources such as Notion, Google Drive, Dropbox, OneDrive, websites, and file uploads. Available as a React component, JavaScript SDK, and soon as a magic link. \n\nCarbon handles OAuth flows for 10+ sources, transforms the source data, and automates data synchronization.\n\n### 🗄️ Store\n\nChoose between Carbon's managed vector database (hosted on Qdrant Cloud) or your storage solution. The database updates as users modify connected sources and manage chunks alongside embeddings.\n\n### 🔌 Universal API\n\nAccess and manage data (documents, chunks, vectors, etc.) from any source using our flexible API suite. Apply custom metadata filters to objects for tailored data retrieval.\n\n## Setup\n\n---\n\n### 🔑 Getting a Carbon API Key\n\nCarbon is free to use up to the first 20 million characters. \nBook a 15 minute onboarding to get an API key [here](https://cal.com/carbon-ai/15min).\n\n### 🔗 Helpful Links\nTo get started with Carbon, follow our guides:\n\n- [Installing Carbon Connect](https://api.carbon.ai/redoc#tag/Carbon-Connect)\n- [Integrating Data Sources](https://api.carbon.ai/redoc#tag/Data-Sources)\n\n",
"name": "Getting Started"
},
{
"description": "\n\n---\n\nUse Connect to connect to your users' accounts with the Carbon API.\n\nCarbon Connect is the client-side component that your users will interact with in order upload their content to Carbon and grant you access via the Carbon API.\n\nCarbon Connect handles credential validation, content upload, and success/error handling for each connector that Carbon supports. We support 10+ integrations (Google Drive, Notion, etc), local file uploads (images, audio and text), and public webpages.\n\nCarbon is currently supported via a Javascript SDK, as well as via React Native and mobile webviews.\n\n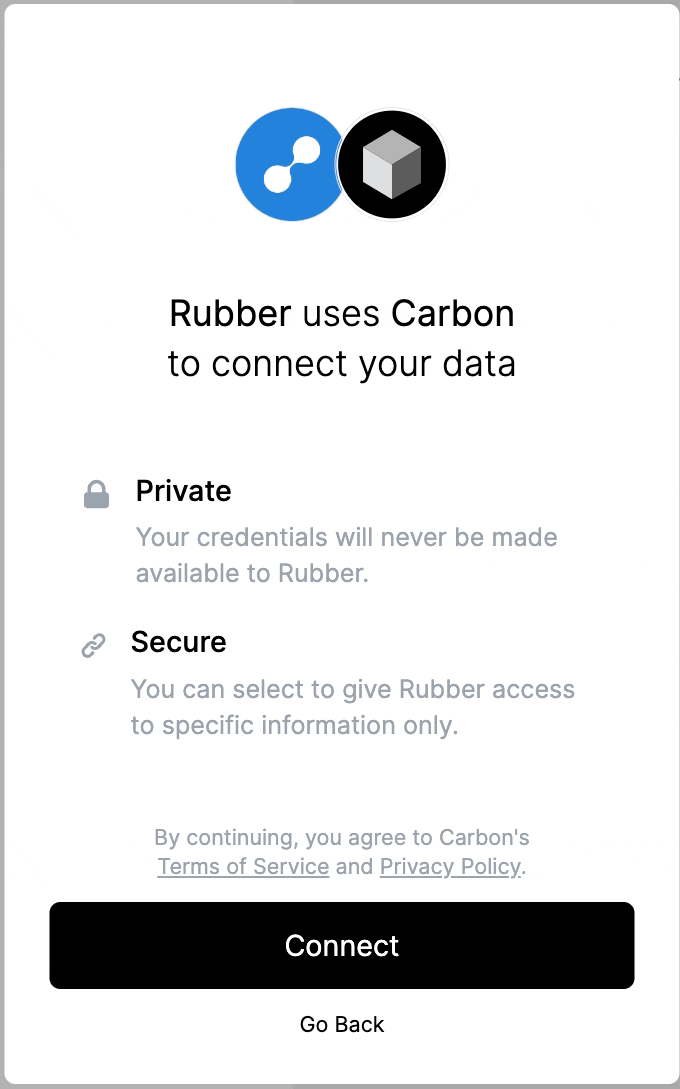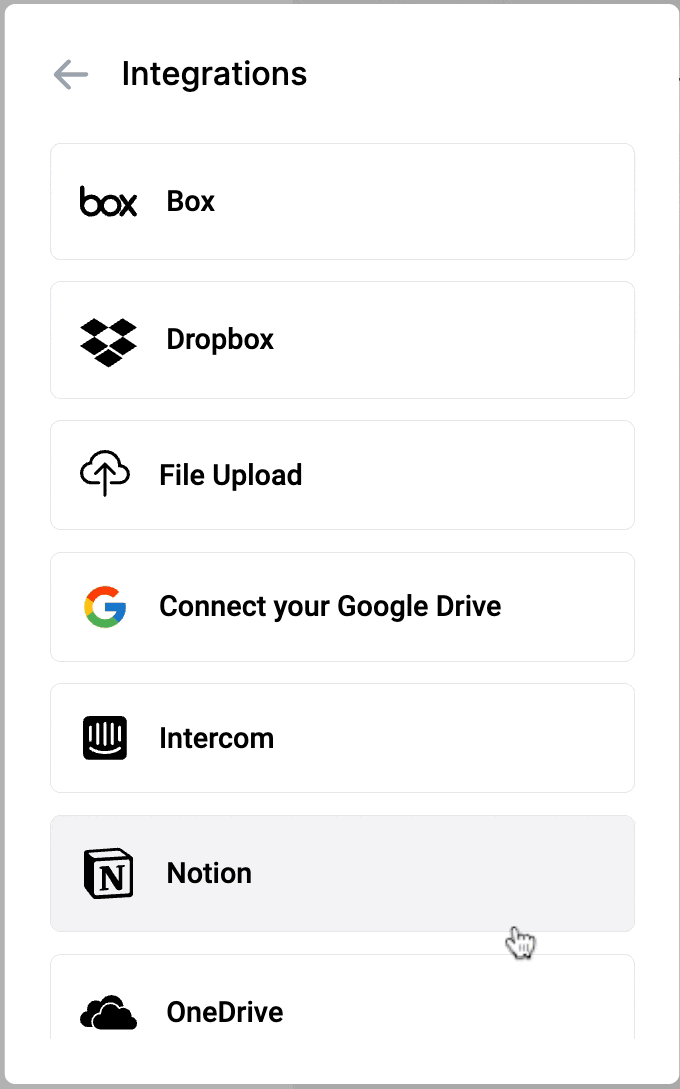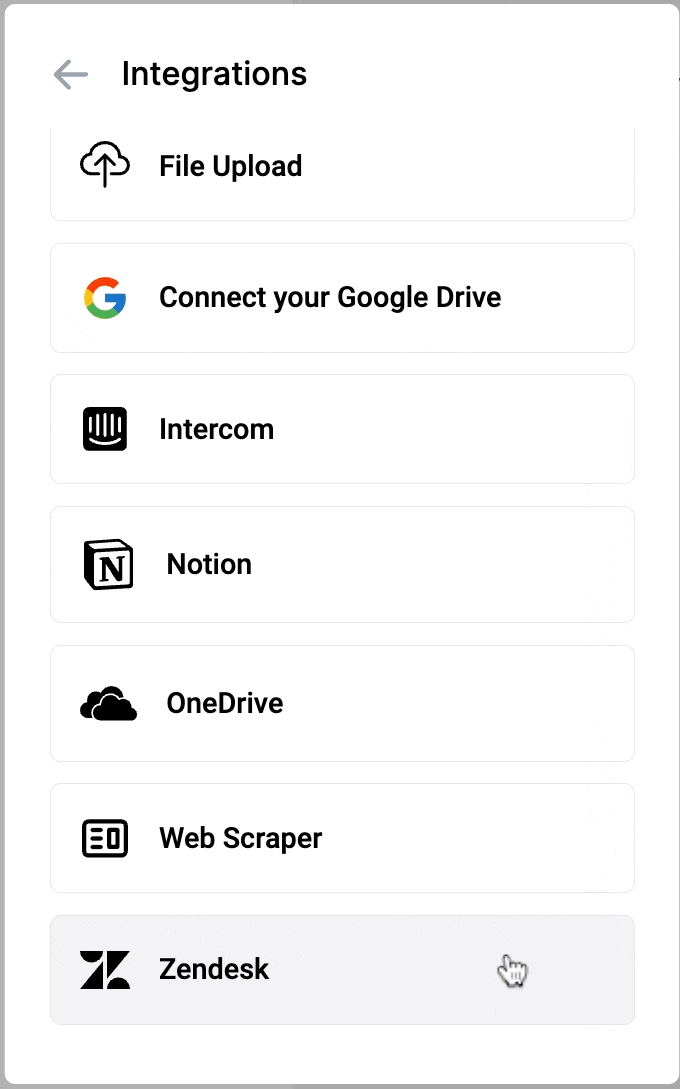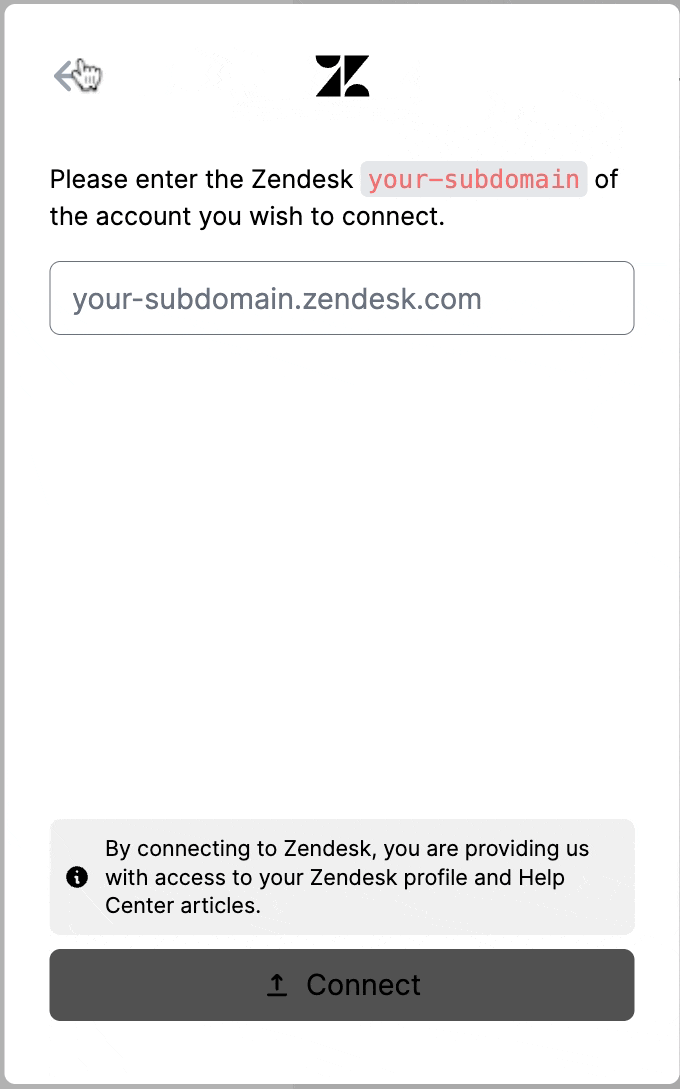\n\n# Javascript SDK\n\n---\n\nCarbon Connect JS is a vanilla JS wrapper and a headless offering to integrate Carbon API into your product.\n\nYou can reference this example repo showcasing our JS SDK [here](https://github.com/hubbleai/sdk-example).\n\n## Installation\n\n---\n\nUse the package manager [npm](https://www.npmjs.com/) to install carbon-connect-js.\n\n```bash\nnpm install carbon-connect-js\n```\n\n## Usage\n\n---\n\n```javascript\nimport * as Carbon from 'carbon-connect-js';\n\n// Note: Access token generation should happen prior to other function calls!\n\n// Generate Access Token\nconst accessTokenResponse = await Carbon.generateAccessToken(\n 'api_key',\n 'customer_id'\n);\nconsole.log(accessTokenResponse.data.access_token);\n\n// Get White Label data\nconst whiteLabelResponse = Carbon.getWhiteLabelData('ACCESS_TOKEN');\nconsole.log(whiteLabelResponse.data);\n```\n\n## Methods\n\n---\n\n### 1. generateAccessToken()\n\n- **Description**: This method is used to generate an access token required for authentication. The access token will be valid for 10 hours.\n\n- **Parameters**: The `generateAccessToken()` method accepts an object with the following properties:\n\n - `apiKey` (string): Your API key.\n - `customerId` (string): The customer's unique ID.\n\n- **Returns**: A promise that resolves to an `AccessTokenResponse` object:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data containing the access token, if the request was successful. Otherwise, null.\n - `error` (string or null): Error message if there was an issue generating the token. Otherwise, null.\n\n- **Usage**: Here's how you can use the `generateAccessToken()` method\n\n ```javascript\n const Carbon = require('carbon-connect-js');\n\n async function fetchAccessToken() {\n try {\n const response = await Carbon.generateAccessToken({\n apiKey: 'your_api_key',\n customerId: 'your_customer_id',\n });\n\n if (response.status === 200) {\n console.log('Access token:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error:', err);\n }\n }\n\n fetchAccessToken();\n ```\n\n- **Note** : It is ideal to call this method from your backend code and return it to your frontend. This is to avoid exposing your API key to the frontend.\n\n### 2. getWhiteLabelData()\n\n- **Description**: This method retrieves the white label data of the organization, which can be useful for custom branding and theming.\n- **Parameters**: The `getWhiteLabelData()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained from the authentication process.\n\n- **Returns**: A promise that resolves to an `WhiteLabelDataResponse` object:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object): The response data containing details of the white label settings.\n\n- **Usage**: Here's how you can use the `getWhiteLabelData()` method\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function fetchWhiteLabelDetails() {\n try {\n const response = await Carbon.getWhiteLabelData({\n accessToken: 'ACCESS_TOKEN',\n });\n\n if (response.status === 200) {\n console.log('White Label Data:', response.data);\n } else {\n console.error(\n 'Failed to fetch white label data. Status:',\n response.status\n );\n }\n } catch (err) {\n console.error('Unexpected error:', err.message);\n }\n }\n\n // Call the function to fetch the data.\n fetchWhiteLabelDetails();\n ```\n\n### 3. getUserConnections()\n\n- **Description**: Retrieve all the active integrations or connections associated with a user.\n- **Parameters**: The `getUserConnections()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained from the authentication process.\n\n- **Returns**: A promise that resolves to a `UserConnectionsResponse` object:\n\n - `status` (number): The HTTP status code of the response.\n - `connections` (array): List of active integrations or connections associated with the user.\n - `error` (object or null): Contains error details if any issues arise while fetching user connections.\n\n- **Usage**:\n\n```javascript\nimport * as Carbon from 'carbon-connect-js';\n\nasync function fetchUserIntegrations() {\n try {\n const response = await Carbon.getUserConnections({\n accessToken: 'ACCESS_TOKEN',\n });\n\n if (response.status === 200) {\n console.log('User Connections:', response.connections);\n } else {\n console.error('Error:', response.error.message);\n }\n } catch (err) {\n console.error('Unexpected error:', err.message);\n }\n}\n\n// Initiate the call to fetch user integrations.\nfetchUserIntegrations();\n```\n\n### 4. generateOauthurl()\n\n- **Description**: Generate an OAuth URL to facilitate users in connecting a third-party account.\n\n- **Parameters**: The `generateOauthurl()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `integrationName` (string): Name of the third-party service you want to integrate.\n - `chunkSize` (number, optional): Defines the chunk size. Defaults to 1500.\n - `chunkOverlap` (number, optional): Defines the chunk overlap. Defaults to 20.\n - `skipEmbeddingGeneration` (boolean, optional): If set to true, embedding generation will be skipped. Defaults to false.\n - `tags` (object, optional): Tags that can be passed for additional information. Defaults to an empty object.\n\n- **Returns**: A promise that resolves to a `GenerateOAuthURLResponse` object:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object): Contains details like the generated OAuth URL, integration name, chunk size, chunk overlap, and other specified parameters.\n - `error` (string or null): Contains error message if there's any issue generating the OAuth URL.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function generateIntegrationOAuthURL() {\n try {\n const response = await Carbon.generateOauthurl({\n accessToken: 'YOUR_ACCESS_TOKEN',\n integrationName: 'SERVICE_NAME',\n // Accepted values are: NOTION, GOOGLE_DRIVE, ONEDRIVE, INTERCOM, DROPBOX, ZENDESK, BOX\n });\n\n if (response.status === 200) {\n console.log('Generated OAuth URL:', response.data.oauth_url);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error:', err.message);\n }\n }\n\n generateIntegrationOAuthURL();\n ```\n\n### 5. uploadFiles()\n\n- **Description**: Upload one or multiple files to Carbon, with options to control chunk size, chunk overlap, and embedding generation.\n\n- **Parameters**: The `uploadFiles()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `files` (Array<File>): An array of files you want to upload.\n - `chunkSize` (number, optional): Defines the chunk size. Defaults to 1500.\n - `chunkOverlap` (number, optional): Defines the chunk overlap. Defaults to 20.\n - `skipEmbeddingGeneration` (boolean, optional): If set to true, embedding generation will be skipped. Defaults to false.\n\n- **Returns**: A promise that resolves to an UploadFilesResponse object:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object): Contains details of the uploaded files, including count and array of successful uploads.\n - `error` (object or null): Contains error details if there's an issue during file upload.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function uploadFilesToPlatform() {\n try {\n const response = await Carbon.uploadFilesToCarbon({\n accessToken: 'YOUR_ACCESS_TOKEN',\n files: filesToUploadArray,\n // You can also specify other parameters here if needed.\n });\n\n if (response.status === 200) {\n console.log('Uploaded Files:', response.data.successfulUploads);\n if (response.error) {\n console.warn('Failed Uploads:', response.error.failedUploads);\n }\n } else {\n console.error('Error:', response.error.message);\n }\n } catch (err) {\n console.error('Unexpected error:', err.message);\n }\n }\n\n uploadFilesToPlatform();\n ```\n\n### 6. updateTags()\n\n- **Description**: Updates or appends tags to a specified file in Carbon.\n\n- **Parameters**:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `fileId` (int): The ID of the file you want to update tags for.\n - `tags` (object): The tags you want to add or update for the specified file.\n\n- **Returns**: A promise that resolves to an `UpdateTagsResponse` object:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object): Contains details of the updated file, including the file ID and updated tags.\n - `error` (object or null): Contains error details if there's an issue updating the tags.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function updateFileTags() {\n const fileId = 'YOUR_FILE_ID'; // Replace with your actual file ID\n const tagsToUpdate = {\n category: 'document',\n type: 'pdf',\n // ... add more tags as needed\n };\n\n try {\n const response = await Carbon.updateTags({\n accessToken: 'YOUR_ACCESS_TOKEN',\n fileId: fileId,\n tags: tagsToUpdate,\n });\n\n if (response.status === 200) {\n console.log('Updated Tags:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error:', err.message);\n }\n }\n\n updateFileTags();\n ```\n\n### 7. processSitemapUrl()\n\n- **Description**: Fetches and processes the URLs present in a specified sitemap.\n\n- **Parameters**: The `processSitemapUrl()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `sitemapUrl` (string): The URL of the sitemap to be fetched.\n\n- **Returns**: A promise that resolves to a `ProcessSitemapUrlResponse` object:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object): Contains details of the fetched URLs.\n - `urls` (array): An array of URLs retrieved from the sitemap.\n - `count` (number): Total number of URLs retrieved from the sitemap.\n - `error` (string or null): Error message if there's an issue fetching the sitemap.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function fetchSitemapUrls() {\n const sitemap = 'YOUR_SITEMAP_URL'; // Replace with your actual sitemap URL\n\n try {\n const response = await Carbon.handleFetchSitemapUrls({\n accessToken: 'ACCESS_TOKEN',\n sitemapUrl: sitemap,\n });\n\n if (response.status === 200) {\n console.log('Retrieved URLs:', response.data.urls);\n console.log('Total URLs:', response.data.count);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error:', err.message);\n }\n }\n\n fetchSitemapUrls();\n ```\n\n### 8. submitScrapeRequest()\n\n- **Description**: Initiates a scraping request for specified URLs. This function supports batch scraping and can take multiple URLs in a single request.\n\n- **Parameters**: The `submitScrapeRequest()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `urls` (array of strings): An array of URLs you want to scrape.\n - `tags` (object, optional): Tags associated with the scraping request. Defaults to an empty object.\n - `recursionDepth` (number, optional): Specifies the depth of scraping for linked pages. Defaults to 1.\n - `maxPagesToScrape` (number, optional): Maximum number of pages to scrape per URL. Defaults to 1.\n - `chunkSize` (number, optional): Size of data chunks. Defaults to 1500.\n - `chunkOverlap` (number, optional): Overlapping size between chunks. Defaults to 20.\n - `skipEmbeddingGeneration` (boolean, optional): Indicates whether to skip embedding generation during scraping. Defaults to false.\n\n- **Returns**: A promise that resolves to a `SubmitScrapeRequestResponse` object:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object): Contains details of the scraping response.\n - `files` (array): An array of objects, each representing a file resulting from the scraping process.\n - `error` (string or null): Error message if there's an issue initiating the scraping.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function initiateScraping() {\n const urlsToScrape = ['URL_1', 'URL_2']; // Replace with your actual URLs\n\n try {\n const response = await Carbon.submitScrapeRequest({\n accessToken: 'YOUR_ACCESS_TOKEN',\n urls: urlsToScrape,\n recursionDepth: 2,\n maxPagesToScrape: 5,\n });\n\n if (response.status === 200) {\n console.log('Scraping result:', response.data.files);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error:', err.message);\n }\n }\n\n initiateScraping();\n ```\n\n### 9. getCarbonHealth()\n\n- **Description**: This function retrieves the health status of the Carbon service.\n\n- **Parameters**: The `getCarbonHealth()` method does not require any parameters.\n\n- **Returns**: A promise that resolves to a `getCarbonHealthResponse` object:\n\n - status (number): An HTTP status code indicating the health status. A status code of 200 indicates that the service is in a healthy state.\n\n- **Usage**: Below is an example of how to utilize the `getCarbonHealth()` method\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function fetchCarbonHealth() {\n try {\n const response = await Carbon.getCarbonHealth();\n\n if (response.status === 200) {\n console.log('Carbon service is healthy.');\n } else {\n console.error(\n 'Carbon service is currently unavailable:',\n response.status\n );\n }\n } catch (err) {\n console.error(\n 'Unexpected error while checking Carbon health:',\n err.message\n );\n }\n }\n\n fetchCarbonHealth();\n ```\n\n### 10. uploadFileFromUrl()\n\n- **Description**: This function allows you to upload a file to the Carbon service by fetching it from a specified URL.\n\n- **Parameters**: The `uploadFileFromUrl()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `url` (string): The URL from which the file should be retrieved and uploaded.\n - `fileName` (string, optional): A custom name for the file. If not specified, the original filename from the URL will be used.\n - `chunkSize` (number, optional): The size of data chunks during the upload process. Default is set to 1500.\n - `chunkOverlap` (number, optional): The overlap size between chunks. Default is set to 20.\n - `skipEmbeddingGeneration` (boolean, optional): Indicates whether to skip embedding generation during the upload. Default is set to false.\n\n- **Returns**: A promise that resolves to an `UploadFileFromUrlResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): Contains details of the uploaded file.\n - `file` (object): Represents the uploaded file and all its properties.\n - `error` (string or null): An error message, if there's an issue with the upload.\n\n- **Usage**: Below is an example of how to use the `uploadFileFromUrl()` method\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function uploadFromUrl() {\n const fileUrl = 'URL_TO_THE_FILE'; // Replace with the actual URL\n\n try {\n const response = await Carbon.uploadFileFromUrl({\n accessToken: 'YOUR_ACCESS_TOKEN',\n url: fileUrl,\n fileName: 'custom_file_name.ext',\n });\n\n if (response.status === 200) {\n console.log('Uploaded file details:', response.data.file);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during upload:', err.message);\n }\n }\n\n uploadFromUrl();\n ```\n\n### 11. uploadText()\n\n- **Description**: This function enables the uploading of textual content to the Carbon service.\n\n- **Parameters**: The `uploadText()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `contents` (string): The text content you wish to upload.\n - `fileName` (string, optional): A custom name for the file. If not specified, a random name will be used.\n - `chunkSize` (number, optional): The size of data chunks during the upload process. The default value is 1500.\n - `chunkOverlap` (number, optional): The overlapping size between chunks. The default value is 20.\n - `skipEmbeddingGeneration` (boolean, optional): An indicator of whether to skip embedding generation during the upload. The default is set to false.\n - `overWriteFileId` (number or null, optional): If provided, the uploaded content will overwrite an existing file with the specified ID.\n\n- **Returns**: A promise that resolves to an `UploadTextResponse` object containing the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): Contains details of the uploaded file.\n - `file` (object): Represents the uploaded file along with its properties.\n - `error` (string or null): An error message in case of an issue during the upload.\n\n- **Usage**: Below is an example of how to utilize the `uploadText()` method\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function uploadCustomText() {\n const textContent = 'This is a sample text content for upload.';\n\n try {\n const response = await Carbon.uploadText({\n accessToken: 'YOUR_ACCESS_TOKEN',\n contents: textContent,\n fileName: 'sample_text.txt',\n });\n\n if (response.status === 200) {\n console.log('Uploaded file details:', response.data.file);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during upload:', err.message);\n }\n }\n\n uploadCustomText();\n ```\n\n### 12. deleteFile()\n\n- **Description**: This function allows for the removal of a specified file from the Carbon service.\n\n- **Parameters**: The `deleteFile()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `fileId` (string): The ID of the file you intend to delete.\n\n- **Returns**: A promise that resolves to an `DeleteFileResponse` object containing the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): Contains details of the deleted file or any additional response data.\n - `error` (string or null): An error message in case there is an issue with the file deletion.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function removeFile() {\n const targetFileId = 'YOUR_FILE_ID_HERE';\n\n try {\n const response = await Carbon.deleteFile({\n accessToken: 'YOUR_ACCESS_TOKEN',\n fileId: targetFileId,\n });\n\n if (response.status === 200) {\n console.log('File successfully deleted:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during file deletion:', err.message);\n }\n }\n\n removeFile();\n ```\n\n### 13. resyncFile()\n\n- **Description**: This function triggers a resynchronization of a specified file with the Carbon service. This can be valuable in scenarios where a file's internal data changes or if there are discrepancies in the data on the server.\n\n- **Parameters**: The `resyncFile()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `fileId` (string): The ID of the file you wish to resynchronize.\n - `chunkSize` (number, optional, default 1500): Specifies the chunk size when processing the file.\n - `chunkOverlap` (number, optional, default 20): Specifies the overlap size between each chunk.\n\n- **Returns**: A promise that resolves to an `ResyncFileResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data, containing the access token if the request was successful; otherwise, it is null.\n - `error` (string or null): An error message if there was an issue generating the token, otherwise null.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function resynchronizeFile() {\n const targetFileId = 'YOUR_FILE_ID_HERE';\n\n try {\n const response = await Carbon.resyncFile({\n accessToken: 'YOUR_ACCESS_TOKEN',\n fileId: targetFileId,\n chunkSize: 1600, // Optional. Default is 1500.\n chunkOverlap: 25, // Optional. Default is 20.\n });\n\n if (response.status === 200) {\n console.log('File successfully resynced:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during file resync:', err.message);\n }\n }\n\n resynchronizeFile();\n ```\n\n### 14. getRawFilePresignedUrl()\n\n- **Description**: This function retrieves a presigned URL that can be utilized to directly access the unprocessed content of a file stored within the Carbon service.\n\n- **Parameters**: The `getRawFilePresignedUrl()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `fileId` (string): The ID of the file for which you seek to obtain the presigned URL.\n\n- **Returns**: A promise that resolves to an `GetRawFilePresignedUrlResponse` object comprising the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null):\n - `presigned_url` (string): The presigned URL that can be used to access the raw file content.\n - `error` (string or null): An error message if there is an issue with fetching the presigned URL.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function fetchPresignedUrl() {\n const targetFileId = 'YOUR_FILE_ID_HERE';\n\n try {\n const response = await Carbon.getRawFilePresignedUrl({\n accessToken: 'YOUR_ACCESS_TOKEN',\n fileId: targetFileId,\n });\n\n if (response.status === 200) {\n console.log('Presigned URL:', response.data.presigned_url);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error fetching presigned URL:', err.message);\n }\n }\n\n fetchPresignedUrl();\n ```\n\n### 15. getParsedFilePresignedUrl()\n\n- **Description**: This function retrieves a presigned URL that can be employed to directly access the parsed content of a file stored within the Carbon service.\n\n- **Parameters**: The `getParsedFilePresignedUrl()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `fileId` (string): The ID of the file for which you desire the presigned URL.\n\n- **Returns**: A promise that resolves to an `GetParsedFilePresignedUrlResponse` object containing the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null):\n - `presigned_url` (string): The presigned URL that enables access to the parsed file content.\n - `error` (string or null): An error message in the event of any issues with obtaining the presigned URL.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function fetchParsedPresignedUrl() {\n const targetFileId = 'YOUR_FILE_ID_HERE';\n\n try {\n const response = await Carbon.getParsedFilePresignedUrl({\n accessToken: 'YOUR_ACCESS_TOKEN',\n fileId: targetFileId,\n });\n\n if (response.status === 200) {\n console.log(\n 'Presigned URL for parsed content:',\n response.data.presigned_url\n );\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error(\n 'Unexpected error fetching presigned URL for parsed content:',\n err.message\n );\n }\n }\n\n fetchParsedPresignedUrl();\n ```\n\n### 16. getUserFiles()\n\n- **Description**: This function retrieves a list of user files from the Carbon service based on specified filters.\n\n- **Parameters**: The `getUserFiles()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `limit` (number, optional, default = 10): The maximum number of files to be returned.\n - `offset` (number, optional, default = 0): The starting point from which to fetch files.\n - `order_by` (string, optional, default = 'updated_at'): The attribute by which the returned files are ordered.\n - `order_dir` (string, optional, default = 'asc'):The direction in which the files are ordered. Options are 'asc' or 'desc'.\n - `filters` (Record<string, any>, optional, default = {}): An object of filters to apply to the file list query.\n - `include_raw_file` (boolean, optional, default = false): If set to true, includes the presigned URL for the raw file in the response.\n - `include_parsed_file` (boolean, optional, default = false): If set to true, includes the presigned URL for the parsed file in the response.\n\n- **Returns**: A promise that resolves to an `GetUserFilesResponse` object with the following properties:\n\n - status (number): The HTTP status code of the response.\n - data (object or null):\n - files (any[]): An array of user file data objects.\n - error (string or null): An error message if there are issues with fetching user files.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function fetchUserFiles() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n limit: 5,\n order_by: 'created_at',\n order_dir: 'desc',\n };\n\n try {\n const response = await Carbon.getUserFiles(params);\n\n if (response.status === 200) {\n console.log('Fetched user files:', response.data.files);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error fetching user files:', err.message);\n }\n }\n\n fetchUserFiles();\n ```\n\n### 17. deleteTags()\n\n- **Description**: This function removes specified tags from a user file within the given organization. The method sends a request to the Carbon service to delete the provided tags from the file associated with the `organizationUserFileId`.\n\n- **Parameters**: The `deleteTags()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `organizationUserFileId` (number): The unique identifier of the user file within the organization.\n - `tags` (string[]): An array of tag names to be deleted from the user file.\n\n- **Returns**: A promise that resolves to an `DeleteTagsResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data received from the Carbon service after the tags have been deleted.\n - `error` (string or null): An error message in case there are issues with the deletion of tags from the user file.\n\n- **Usage**: Below is an example of how to use the `generateAccessToken()` method\n\n ```javascript\n const Carbon = require('carbon-connect-js');\n\n async function fetchAccessToken() {\n try {\n const response = await Carbon.generateAccessToken({\n apiKey: 'your_api_key',\n customerId: 'your_customer_id',\n });\n\n if (response.status === 200) {\n console.log('Access token:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error:', err);\n }\n }\n\n fetchAccessToken();\n ```\n\n### 18. fetchUrls()\n\n- **Description**: This method retrieves all URLs from a specified web page. It initiates a GET request to the Carbon service with the target URL as a parameter. The Carbon service will then access the content of the specified web page and parse it to extract all the URLs.\n\n- **Parameters**: The `fetchUrls()` method requires an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `url` (string): The URL of the web page from which the links should be fetched.\n\n- **Returns**: A promise that resolves to an `AccessTokenResponse` object comprising the following properties:\n\n - status (number): The HTTP status code of the response.\n - data (object or null): The response data object containing the extracted URLs and potentially the raw HTML content.\n - urls (string[]): A list of URLs extracted from the web page.\n - html_content (string or null): The raw HTML content of the fetched web page (if provided by the Carbon service).\n - error (string or null): An error message in case there are issues with fetching the URLs.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function retrieveUrls() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n url: 'https://www.example.com', // replace with actual URL\n };\n\n try {\n const response = await Carbon.fetchUrls(params);\n\n if (response.status === 200) {\n console.log('Fetched URLs successfully:', response.data.urls);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error fetching URLs:', err.message);\n }\n }\n\n retrieveUrls();\n ```\n\n### 19. searchUrls()\n\n- **Description**: This method conducts a search for URLs based on the provided query string.\n\n As an illustration, when you perform a search for “content related to MRNA,” you will receive a list of links such as the following:\n\n - https://tomrenz.substack.com/p/mrna-and-why-it-matters\n - https://www.statnews.com/2020/11/10/the-story-of-mrna-how-a-once-dismissed-idea-became-a-leading-technology-in-the-covid-vaccine-race/\n - https://www.statnews.com/2022/11/16/covid-19-vaccines-were-a-success-but-mrna-still-has-a-delivery-problem/\n - https://joomi.substack.com/p/were-still-being-misled-about-how\n\n Subsequently, you can submit these links to the `web_scrape` endpoint in order to retrieve the content of the respective web pages.\n\n- **Parameters**: The `searchUrls()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `query` (string): The search term or query for which URLs are to be discovered.\n\n- **Returns**: A promise that resolves to an `SearchUrlsForQueryResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data object containing the discovered URLs.\n - `urls` (string[]): A list of URLs associated with the search query.\n - `html_content` (null): A null value is returned.\n - `error` (string or null): An error message if there are any issues with the URL search.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function retrieveSearchResults() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n query: 'example search term', // replace with actual query\n };\n\n try {\n const response = await Carbon.searchUrls(params);\n\n if (response.status === 200) {\n console.log('Search results:', response.data.urls);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during search:', err.message);\n }\n }\n\n retrieveSearchResults();\n ```\n\n### 20. fetchYoutubeTranscript()\n\n- **Description**: This method retrieves the transcript for a specific YouTube video.\n\n **Example:** In the URL https://www.youtube.com/watch?v=_Nq2m5LRQ3g&t=1080s, the video id is `_Nq2m5LRQ3`\n\n- **Parameters**: The `fetchYoutubeTranscript()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `videoId` (string): The unique identifier of the YouTube video.\n - `raw` (boolean, optional): A flag indicating whether to fetch the raw transcript (default is false, indicating that only the processed transcript is fetched).\n\n- **Returns**: A promise that resolves to an `FetchYoutubeTranscriptsResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data object containing the transcript information.\n - `error` (string or null): An error message if there are any issues with fetching the transcript.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function retrieveTranscript() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n videoId: 'YOUR_YOUTUBE_VIDEO_ID',\n raw: true,\n };\n\n try {\n const response = await Carbon.fetchYoutubeTranscript(params);\n\n if (response.status === 200) {\n console.log('Transcript data:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during transcript fetch:', err.message);\n }\n }\n\n retrieveTranscript();\n ```\n\n### 21. getEmbeddingsfetchUrls()\n\n- **Description**: This method is utilized to retrieve embeddings based on a provided query.\n\n- **Parameters**: The `getEmbeddings()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `query` (string): The search query.\n - `queryVector` (number[] or null, optional): The query vector.\n - `k` (number): The number of nearest embeddings to retrieve.\n - `filesIds` (number[] or null, optional): An array of file IDs.\n - `parentFileIds` (number[] or null, optional): An array of parent file IDs.\n - `tags` (Record<string, any> or null, optional): Tags associated with the embeddings.\n - `includeTags` (boolean or null, optional): A flag to include tags.\n - `includeVectors` (boolean or null, optional): A flag to include vectors.\n - `includeRawFile` (boolean or null, optional): A flag to include raw file.\n - `hybridSearch` (boolean or null, optional): A flag to indicate hybrid search.\n - `hybridSearchTuningParameters` (HybridSearchParams or null, optional): Parameters for fine-tuning hybrid search. The following properties are available:\n - `weightA`\n - `weightB`\n\n- **Returns**: A promise that resolves to an `GetEmbeddingsResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data containing the embeddings information.\n - `error` (string or null): An error message if there's an issue fetching the embeddings.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function retrieveEmbeddings() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n query: 'YOUR_SEARCH_QUERY',\n k: 5, // Example: retrieve 5 nearest embeddings.\n // Add other parameters as needed\n };\n\n try {\n const response = await Carbon.getEmbeddings(params);\n\n if (response.status === 200) {\n console.log('Embeddings data:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during embeddings fetch:', err.message);\n }\n }\n\n retrieveEmbeddings();\n ```\n\n### 22. getTextChunks()\n\n- **Description**: This method fetches text chunks based on the specified user file ID and other optional parameters.\n\n- **Parameters**: The `getTextChunks()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `userFileId` (number): ID of the user file for which text chunks are being fetched.\n - `limit` (number, optional): Maximum number of text chunks to retrieve. Defaults to 10.\n - `offset` (number, optional): The number to start the fetch from. Useful for pagination. Defaults to 0.\n - `orderBy` (string, optional): The column name to order the results by. Defaults to 'updated_at'.\n - `orderDir` (string, optional): Direction of the order ('asc' or 'desc'). Defaults to 'asc'.\n - `includeVectors` (boolean, optional): Flag to indicate whether to include vectors in the response. Defaults to false.\n\n- **Returns**: A promise that resolves to an `GetTextChunksResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data containing the text chunks information.\n - `error` (string or null): Error message if there's an issue fetching the text chunks.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function retrieveTextChunks() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n userFileId: 12345, // Replace with actual user file ID.\n limit: 5, // Example: retrieve 5 text chunks.\n // Add other parameters as needed\n };\n\n try {\n const response = await Carbon.getTextChunks(params);\n\n if (response.status === 200) {\n console.log('Text chunks data:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during text chunks fetch:', err.message);\n }\n }\n\n retrieveTextChunks();\n ```\n\n### 23. getUserDataSources()\n\n- **Description**: This method retrieves user data sources based on the provided parameters.\n\n- **Parameters**: The `getUserDataSources()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `limit` (number, optional): The maximum number of data sources to retrieve. Defaults to 10.\n - `offset` (number, optional): The starting point for the fetch, useful for pagination. Defaults to 0.\n - `orderBy` (string, optional): The column name to order the results by. Defaults to 'updated_at'.\n - `orderDir` (string, optional): The direction of the order ('asc' or 'desc'). Defaults to 'asc'.\n - `sourceType` (string, optional): The type of data source to filter the results by.\n - `sourceIds` (number[] or null, optional): An array of specific data source IDs to retrieve.\n - `revokedAccess` (boolean or null, optional): A flag to filter data sources based on revoked access.\n\n- **Returns**: A promise that resolves to an `AccessTokenResponse` object with the following properties:\n\n - status (number): The HTTP status code of the response.\n - data (object or null): The response data containing user data sources information.\n - error (string or null): An error message if there's an issue fetching the user data sources.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function retrieveUserDataSources() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n limit: 5, // Example: retrieve 5 data sources.\n // Add other parameters as needed\n };\n\n try {\n const response = await Carbon.getUserDataSources(params);\n\n if (response.status === 200) {\n console.log('User data sources data:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error(\n 'Unexpected error during user data sources fetch:',\n err.message\n );\n }\n }\n\n retrieveUserDataSources();\n ```\n\n### 24. revokeAccessToDataSource()\n\n- **Description**: This method revokes user access to a specified data source. The user will need to re-authenticate after access is revoked.\n\n- **Parameters**: The `revokeAccessToDataSource()` method accepts an object with the following properties:\n\n - `accessToken` (string): The access token obtained through authentication.\n - `dataSourceId` (number): The ID of the data source for which access should be revoked.\n\n- **Returns**: A promise that resolves to an `RevokeAccessToDataSourceResponse` object with the following properties:\n\n - `status` (number): The HTTP status code of the response.\n - `data` (object or null): The response data indicating the outcome of the access revocation request.\n - `error` (string or null): An error message if there are any issues with revoking access to the data source.\n\n- **Usage**:\n\n ```javascript\n import * as Carbon from 'carbon-connect-js';\n\n async function revokeDataSourceAccess() {\n const params = {\n accessToken: 'YOUR_ACCESS_TOKEN',\n dataSourceId: 12345, // Example: data source ID to revoke access to.\n };\n\n try {\n const response = await Carbon.revokeAccessToDataSource(params);\n\n if (response.status === 200) {\n console.log('Successfully revoked access:', response.data);\n } else {\n console.error('Error:', response.error);\n }\n } catch (err) {\n console.error('Unexpected error during access revocation:', err.message);\n }\n }\n\n revokeDataSourceAccess();\n ```\n\n# Prebuilt Component\n\n---\n\n## Installation\n\n---\n\nTo install Carbon Connect as a prebuilt React component, use npm as follows:\n\n```bash\nnpm install carbon-connect\n```\n\n## Prerequisites\n\n---\n\nThe package expects the following npm packages to be installed in your project:\n\n1. `@radix-ui/react-dialog`\n2. `\"lodash\": \"^4.17.21`\n3. `react`\n4. `react-dom`\n5. `react-drag-drop-files`\n6. `react-icons`\n7. `react-toastify`\n8. `tailwindcss`\n\nPlease check for the versions from `package.json` if you encounter a version mismatch error.\n\n## Component Properties\n\n---\n\nThe `CarbonConnect` component accepts the following properties:\n\n| Property | Type | Required? | Description |\n| -------------------------- | --------------- | --------- | ----------------------------------------------------------------------------------------------------------------------- |\n| `brandIcon` | String | Yes | A URL or a local path to your organization's brand icon. |\n| `orgName` | String | Yes | The name of your organization. This is displayed in the initial announcement modal view. |\n| `tokenFetcher` | Function | Yes | A function that returns a promise which resolves with the access and refresh tokens. |\n| `onSuccess` | Function | No | A callback function that will be called after the file upload is successful. |\n| `onError` | Function | No | A callback function that will be called if there is any error in the file upload. |\n| `children` | React Node(JSX) | No | You can pass any valid React node that will be used as a trigger to open the component. |\n| `entryPoint` | String | No | The initial active step when the component loads. Default entry point is 'LOCAL_FILES'. More integrations are upcoming. |\n| `maxFileSize` | Number | No | Maximum file size in bytes that is allowed to be uploaded. Defaults to 10 MB |\n| `tags` | Object | No | Any additional data you want to associate with the component's state, such as an app ID. |\n| `enabledIntegrations` | dict | No | Let's you choose which 3rd party integrations to show. See below for more details about this prop |\n| `primaryBackgroundColor` | String | No | The primary background color of the component. Defaults to `#000000`. |\n| `primaryTextColor` | String | No | The primary text color of the component. Defaults to `#FFFFFF`. |\n| `secondaryBackgroundColor` | String | No | The secondary background color of the component. Defaults to `#FFFFFF`. |\n| `secondaryTextColor` | String | No | The secondary text color of the component. Defaults to `#000000`. |\n| `allowMultipleFiles` | Boolean | No | Whether or not to allow multiple files to be uploaded at once. Defaults to `false`. |\n| `chunkSize` | Number | No | The no.of tokens per chunk. Defaults to 1500. |\n| `overlapSize` | Number | No | The no.of tokens to overlap between chunks. Defaults to 20. |\n| `open` | Boolean | No | Whether or not to open the component. Defaults to `false`. |\n| `setOpen` | Function | No | A function that will be called to set the open state of the component. Defaults to `None`. |\n| `alwaysOpen` | Boolean | No | Whether or not to always keep the component open. Defaults to `false`. |\n| `tosURL` | String | No | A URL to your organization's terms of service. Defaults to `https://carbon.ai/terms`. |\n| `privacyPolicyURL` | String | No | A URL to your organization's privacy policy. Defaults to `https://carbon.ai/privacy`. |\n| `navigateBackURL` | String | No | A URL to your intended destination. Defaults to `None`. |\n| `backButtonText` | String | No | The label that you want to show on the back button. Defaults to `Go back` |\n\nWhen you do not pass `open` or `setOpen`, CC will manage the open state internally. If you pass `open` and `setOpen`, you will have to manage the open state yourself.\n\n### Note about Google Drive\n\nOur oAuth app is in approval phase. your users will see a warning message when they try to connect their Google account. Please ignore the warning and proceed to connect your account. We will update this section once our app is approved.\n\n## Usage\n\n---\n\nThis section demonstrates how to integrate the CarbonConnect component within a Next.js project.\n\n### Client Side Configuration\n\n1. Import necessary libraries and components:\n\n```jsx\nimport { CarbonConnect } from 'carbon-connect';\nimport axios from 'axios';\n```\n\n2. Token Retrieval:\n The tokenFetcher function is set up to request access tokens from Carbon directly via your backend:\n\n```js\nconst tokenFetcher = async () => {\n const response = await axios.get('/api/auth/fetchCarbonTokens', {\n params: { customer_id: 'your_customer_id' },\n });\n return response.data; // Must return data containing access_token\n};\n```\n In the example above, tokenFetcher is a helper function that retrieves the necessary tokens for authentication. This function should be implemented in your client-side code and is designed to make a request to an API on your backend server. The API then requests tokens from the Carbon token creation endpoint. The Carbon token creation endpoint is a secure endpoint that requires a valid API key and customer ID. The customer ID is a unique identifier for your end-user, and you can pass any string as the customer ID. The API key is a secret key provided to you by Carbon. Please contact us to obtain your API key.\n\n3. Implement CarbonConnect Component:\n Here's a concise usage example. Customize according to your requirements:\n\n```jsx\n<CarbonConnect\n orgName=\"Your Organization\"\n brandIcon=\"path/to/your/brand/icon\"\n tokenFetcher={tokenFetcher}\n tags={{\n tag1: 'tag1_value',\n tag2: 'tag2_value',\n tag3: 'tag3_value',\n }}\n maxFileSize={10000000}\n enabledIntegrations={[\n {\n id: 'LOCAL_FILES',\n chunkSize: 100,\n overlapSize: 10,\n maxFileSize: 20000000,\n allowMultipleFiles: true,\n maxFilesCount: 5,\n allowedFileTypes: [\n {\n extension: 'csv',\n chunkSize: 1200,\n overlapSize: 120,\n },\n {\n extension: 'txt',\n chunkSize: 1599,\n overlapSize: 210,\n },\n {\n extension: 'pdf',\n },\n ],\n },\n {\n id: 'NOTION',\n chunkSize: 1500,\n overlapSize: 20,\n },\n {\n id: 'WEB_SCRAPER',\n chunkSize: 1500,\n overlapSize: 20,\n },\n {\n id: 'GOOGLE_DRIVE',\n chunkSize: 1000,\n overlapSize: 20,\n },\n ]}\n onSuccess={(data) => console.log('Data on Success: ', data)}\n onError={(error) => console.log('Data on Error: ', error)}\n primaryBackgroundColor=\"#F2F2F2\"\n primaryTextColor=\"#555555\"\n secondaryBackgroundColor=\"#f2f2f2\"\n secondaryTextColor=\"#000000\"\n allowMultipleFiles={true}\n open={true}\n chunkSize={1500}\n overlapSize={20}\n // entryPoint=\"LOCAL_FILES\"\n></CarbonConnect>\n```\n\n### Server Side Configuration\n\nYour backend should handle token requests like this:\n\n```js\nconst response = await axios.get('https://api.carbon.ai/auth/v1/access_token', {\n headers: {\n 'Content-Type': 'application/json',\n 'customer-id': '<YOUR_USER_UNIQUE_IDENTIFIER>',\n authorization: 'Bearer <YOUR_API_KEY>',\n },\n});\nif (response.status === 200 && response.data) {\n res.status(200).json(response.data);\n}\n```\n\n### Return Value Expectation:\n\nEnsure that your tokenFetcher returns an object structured as:\n\n```js\n{\n access_token: string;\n}\n```\n\n## Enable Data Sources\n\n---\n\nAnother important prop is enabledIntegrations. This prop lets you choose which integrations to show in the component. You can also pass additional configuration for each integration. We have provided an example in the above code snippet. Here is the list of all the integrations that you can enable:\n\n1. `LOCAL_FILES`: This integration lets you upload files from your local machine. You can pass the following configuration for this integration:\n\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `maxFileSize`: This is the maximum file size in bytes that is allowed to be uploaded. Defaults to 10 MB.\n - `allowMultipleFiles`: Whether or not to allow multiple files to be uploaded at once. Defaults to `false`.\n - `maxFilesCount`: This is the maximum no.of files that can be uploaded at once. Defaults to 10.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n - `allowedFileTypes`: This is an array of objects. Each object represents a file type that is allowed to be uploaded. Each object can have the following properties:\n - `extension`: The file extension of the file type. This is a required property.\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n\n2. `NOTION`: This integration lets you upload files from your notion account. You can pass the following configuration for this integration\n\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n\n3. `WEB_SCRAPER`: This integration lets you scrape URLs. You can pass the following configuration for this integration:\n\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `recursionDepth`: This is the depth of recursion. Defaults to 3. If you do not want recursion to happen, please pass 1. Passing 0 will scrape recursively until the maxPagesToScrape limit is reached.\n - `maxPagesToScrape`: This is the maximum no.of pages to scrape. Defaults to 100.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n\n4. `GOOGLE_DRIVE`: This integration lets you upload files from your Google Drive. You can pass the following configuration for this integration:\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n\n5. `INTERCOM`: This integration lets you select pages from your Intercom. You can pass the following configuration for this integration:\n\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n\n6. `DROPBOX`: This integration lets you upload files from your Dropbox. You can pass the following configuration for this integration:\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n\n7. `ONEDRIVE`: This integration lets you upload files from your Onedrive. You can pass the following configuration for this integration:\n - `chunkSize`: This is the no.of tokens per chunk. Defaults to 1500.\n - `overlapSize`: This is the size of the overlap in tokens. Defaults to 20.\n - `skipEmbeddingGeneration`: Whether or not to skip embeddings generation. Defaults to `false`.\n\n## Callback Function Props\n\n---\n\n1. `onError`: CC will also call another call back method if there is an error while uploading file. This function will pass data in the following format:\n\n```js\n{\n status: 400,\n action: 'UPDATE',\n event: 'UPDATE',\n integration: `<INTEGRATION_NAME>`, // 'LOCAL_FILES' or 'WEB_SCRAPER',\n data: `<data_object>`, // This field will be present only if the error is related to a file or web scraper\n}\n```\n\n2. `onSuccess`: You can let CC trigger a callback function upon successful file upload, 3rd party account connection and file selection, Webscraping request initiation.\n\n ### `onSuccess`` Event Types\n\n 1. `INITIATE`: This event type is triggered when a user enters the integration flow (either for auth or file selection)\n 2. `ADD`: This event type is triggered when a user authenticates an account under an integration.\n 3. `UPDATE`: This event type is triggered when a user adds or removes files for an integration. We’ll list the files added or removed.\n 4. `CANCEL`: This event type is triggered when when a user exits the integration flow without taking any action.\n\n\n ### Data passed to `onSuccess` callback\n\n The data passed to the onSuccess callback prop will be:\n\n 1. For `LOCAL_FILES`: \n\n ```js\n {\n status: 200,\n data: {\n \"data_source_external_id\": null, // This field is not applicable for local files\n \"sync_status\": null, // This is not applicable for local files\n \"files\": <Array of objects corresponding to the files uploaded>, (Refer to the file object format below)\n },\n action: 'UPDATE'\n event: 'UPDATE'\n integration: 'LOCAL_FILES',\n }\n ```\n\n 2. For `WEB_SCRAPER`: An array containing only one object in the following format\n\n ```js\n {\n status: 200,\n data: {\n \"data_source_external_id\": null, // This field is not applicable for webscrapers\n \"sync_status\": null, // This is not applicable for webscrapers\n \"files\": <Array of objects corresponding to the parent URLs submitted>, (Refer to the file object format below)\n },\n action: 'UPDATE'\n event: 'UPDATE'\n integration: 'WEB_SCRAPER',\n }\n\n ```\n\n 3. For third party integrations: An array of objects. Each object will be in the following format:\n\n ```js\n {\n status: 200,\n data: {\n \"data_source_external_id\": <Unique ID for the data source>,\n \"sync_status\": <SYNC_STATUS>,\n \"files\": <Array of objects corresponding to the files / pages selected>,\n } or null,\n action: <ACTION_TYPE>, // `ACTION_TYPE` can be one of the following: `INITIATE`, `ADD`, `UPDATE`, `CANCEL`\n event: <EVENT_TYPE>, // `EVENT_TYPE` can be one of the following: `INITIATE`, `ADD`, `UPDATE`, `CANCEL`\n integration: <INTEGRATION_NAME>, // `INTEGRATION_NAME` can be one of the following: `LOCAL_FILES`, `NOTION`, `WEB_SCRAPER`, `GOOGLE_DRIVE`, `INTERCOM`, `DROPBOX`, `ONEDRIVE`\n }\n ```\n\n Each file object will be in the following format:\n\n ```js\n {\n \"id\": `Unique ID for the file, can be used for resyncing, deleting, updating tags etc.`,\n \"source\": `<integration_name>`, // One among `LOCAL_FILES`, `NOTION`, `WEB_SCRAPER`, `GOOGLE_DRIVE`, `INTERCOM`, `DROPBOX`, `ONEDRIVE`\n \"organization_id\": `<organization_id>`, // This is your unique organization id in carbon\n \"organization_supplied_user_id\": `<organization_supplied_user_id>`, // This is the unique user id that you pass to CC\n \"organization_user_data_source_id\": `<organization_user_data_source_id>`, // This is the unique user data source id that CC creates for each user for each integration\n \"external_file_id\": `<external_file_id>`, // This is the unique file id in the 3rd party integration\n \"external_url\": `<external_url>`, // This is the unique url of the file in the 3rd party integration\n \"sync_status\": `<sync_status>`, // This is the sync status of the file. It can be one of the following: `READY`, `QUEUED_FOR_SYNCING`, `SYNCING`, `SYNC_ERROR`\n \"last_sync\": `<last_sync>`, // This is the timestamp of the last sync\n \"tags\": `<tags>`, // These are the tags passed in to CC\n \"file_statistics\": `<file_statistics>`, // This is the file statistics object\n \"file_metadata\": `<file_metadata>`, // This is the file metadata object\n \"chunk_size\": `<chunk_size>`, // This is the chunk size used for the file\n \"chunk_overlap\": `<chunk_overlap>`, // This is the chunk overlap used for the file\n \"name\": `<name>`, // This is the name of the file\n \"enable_auto_sync\": `<enable_auto_sync>`, // This is the auto sync status of the file. This is a boolean flag\n \"presigned_url\": `<presigned_url>`, // This is the presigned url of the file\n \"parsed_text_url\": `<parsed_text_url>`, // This is the parsed text url of the file\n \"skip_embedding_generation\": `<skip_embedding_generation>`, // This is the skip embedding generation status of the file. This is a boolean flag\n \"created_at\": `<created_at>`, // This is the timestamp of the file creation\n \"updated_at\": `<updated_at>`, // This is the timestamp of the file updation\n \"action\": `<action>`, // This is the action type. It can be one of the following: `ADD`, `UPDATE`, `REMOVE`\n }\n ```\n",
"name": "Carbon Connect"
},
{
"description": "\n---\nUse this endpoint to check the status of the API. A `200` response indicates that the Carbon API is up.\n\nYou can also check for the health of our services on our [Status Page](https://status.carbon.ai/).\n",
"name": "Health"
},
{
"description": "\n---\n### 💬 We're here to help!\n\nIt’s our mandate to deliver a delightful experience and answer any questions you might have. This documentation is meant to help get you started but isn't the only resource you have! \n\nPlease don't hesitate to email us at [[email protected]](mailto:[email protected]) or reach out directly to your account manager.\n\nOur terms of service can be found here: [terms of service](https://carbon.ai/terms)\n\nWe're excited you're here!\n",
"name": "Contact Us"
}
],
"paths": {
"/integrations/oauth_url": {
"post": {
"tags": [
"Integrations"
],
"summary": "Get Oauth Url",
"operationId": "Integrations_getOauthUrl",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "This endpoint can be used to generate the following URLs\n- An OAuth URL for OAuth based connectors\n- A file syncing URL which skips the OAuth flow if the user already has a valid access token and takes them to the\nsuccess state.",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/OAuthURLRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/OuthURLResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/connect": {
"post": {
"tags": [
"Integrations"
],
"summary": "Connect Data Source",
"operationId": "Integrations_connectDataSource",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ConnectDataSourceInput"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ConnectDataSourceResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/items/sync": {
"post": {
"tags": [
"Integrations"
],
"summary": "Sync Data Source Items",
"operationId": "Integrations_syncDataSourceItems",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/SyncDirectoryRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/OrganizationUserDataSourceAPI"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/items/sync/cancel": {
"post": {
"tags": [
"Integrations"
],
"summary": "Cancel Data Source Items Sync",
"operationId": "Integrations_cancel",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/SyncDirectoryRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/OrganizationUserDataSourceAPI"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/items/list": {
"post": {
"tags": [
"Integrations"
],
"summary": "List Data Source Items",
"operationId": "Integrations_listDataSourceItems",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ListDataSourceItemsRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ListDataSourceItemsResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/files/sync": {
"post": {
"tags": [
"Integrations"
],
"summary": "Sync Files",
"operationId": "Integrations_syncFiles",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "After listing files and folders via /integrations/items/sync and integrations/items/list, use the selected items' external ids \nas the ids in this endpoint to sync them into Carbon. Sharepoint items take an additional parameter root_id, which identifies\nthe drive the file or folder is in and is stored in root_external_id. That additional paramter is optional and excluding it will\ntell the sync to assume the item is stored in the default Documents drive.",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/SyncFilesRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/confluence/list": {
"post": {
"tags": [
"Integrations"
],
"summary": "Confluence List",
"operationId": "Integrations_listConfluencePages",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "This endpoint has been deprecated. Use /integrations/items/list instead.\n\nTo begin listing a user's Confluence pages, at least a `data_source_id` of a connected\nConfluence account must be specified. This base request returns a list of root pages for\nevery space the user has access to in a Confluence instance. To traverse further down\nthe user's page directory, additional requests to this endpoint can be made with the same\n`data_source_id` and with `parent_id` set to the id of page from a previous request. For\nconvenience, the `has_children` property in each directory item in the response list will\nflag which pages will return non-empty lists of pages when set as the `parent_id`.",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ListRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ListResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
},
"deprecated": true
}
},
"/integrations/confluence/sync": {
"post": {
"tags": [
"Integrations"
],
"summary": "Confluence Sync",
"operationId": "Integrations_syncConfluence",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "This endpoint has been deprecated. Use /integrations/files/sync instead.\n\nAfter listing pages in a user's Confluence account, the set of selected page `ids` and the\nconnected account's `data_source_id` can be passed into this endpoint to sync them into\nCarbon. Additional parameters listed below can be used to associate data to the selected\npages or alter the behavior of the sync.",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/SyncFilesRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
},
"deprecated": true
}
},
"/integrations/azure_blob_storage": {
"post": {
"tags": [
"Integrations"
],
"summary": "Azure Blob Storage Auth",
"operationId": "Integrations_syncAzureBlobStorage",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "This endpoint can be used to connect Azure Blob Storage.\n\nFor Azure Blob Storage, follow these steps:\n<ol>\n <li>Create a new Azure Storage account and grant the following permissions:\n <ul>\n <li>List containers.</li>\n <li>Read from specific containers and blobs to sync with Carbon. Ensure any future containers or blobs carry the same permissions.</li>\n </ul>\n </li>\n <li>Generate a shared access signature (SAS) token or an access key for the storage account.</li>\n</ol>\n\nOnce created, provide us with the following details to generate the connection URL:\n<ol>\n <li>Storage Account KeyName.</li>\n <li>Storage Account Name.</li>\n</ol>",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/AzureBlobAuthRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/OrganizationUserDataSourceAPI"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/s3": {
"post": {
"tags": [
"Integrations"
],
"summary": "S3 Auth",
"operationId": "Integrations_createAwsIamUser",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "This endpoint can be used to connect S3 as well as Digital Ocean Spaces (S3 compatible) \nFor S3, create a new IAM user with permissions to:\n<ol>\n<li>List all buckets.</li>\n<li>Read from the specific buckets and objects to sync with Carbon. Ensure any future buckets or objects carry \nthe same permissions.</li>\n</ol>\nOnce created, generate an access key for this user and share the credentials with us. We recommend testing this key beforehand. \nFor Digital Ocean Spaces, generate the above credentials in your Applications and API page here https://cloud.digitalocean.com/account/api/spaces.\nEndpoint URL is required to connect Digital Ocean Spaces. It should look like <<region>>.digitaloceanspaces.com",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/S3AuthRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/OrganizationUserDataSourceAPI"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/s3/files": {
"post": {
"tags": [
"Integrations"
],
"summary": "S3 Files",
"operationId": "Integrations_syncS3Files",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "After optionally loading the items via /integrations/items/sync and integrations/items/list, use the bucket name \nand object key as the ID in this endpoint to sync them into Carbon. Additional parameters below can associate \ndata with the selected items or modify the sync behavior",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/S3FileSyncInput"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/azure_blob_storage/files": {
"post": {
"tags": [
"Integrations"
],
"summary": "Azure Blob Files",
"operationId": "Integrations_syncAzureBlobFiles",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "After optionally loading the items via /integrations/items/sync and integrations/items/list, use the container name \nand file name as the ID in this endpoint to sync them into Carbon. Additional parameters below can associate \ndata with the selected items or modify the sync behavior",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/AzureBlobFileSyncInput"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/gmail/sync": {
"post": {
"tags": [
"Integrations"
],
"summary": "Gmail Sync",
"operationId": "Integrations_syncGmail",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "Once you have successfully connected your gmail account, you can choose which emails to sync with us\nusing the filters parameter. Filters is a JSON object with key value pairs. It also supports AND and OR operations.\nFor now, we support a limited set of keys listed below.\n\n<b>label</b>: Inbuilt Gmail labels, for example \"Important\" or a custom label you created. \n<b>after</b> or <b>before</b>: A date in YYYY/mm/dd format (example 2023/12/31). Gets emails after/before a certain date.\nYou can also use them in combination to get emails from a certain period. \n<b>is</b>: Can have the following values - starred, important, snoozed, and unread \n<b>from</b>: Email address of the sender \n<b>to</b>: Email address of the recipient \n<b>in</b>: Can have the following values - sent (sync emails sent by the user) \n<b>has</b>: Can have the following values - attachment (sync emails that have attachments) \n\nUsing keys or values outside of the specified values can lead to unexpected behaviour.\n\nAn example of a basic query with filters can be\n```json\n{\n \"filters\": {\n \"key\": \"label\",\n \"value\": \"Test\"\n }\n}\n```\nWhich will list all emails that have the label \"Test\".\n\nYou can use AND and OR operation in the following way:\n```json\n{\n \"filters\": {\n \"AND\": [\n {\n \"key\": \"after\",\n \"value\": \"2024/01/07\"\n },\n {\n \"OR\": [\n {\n \"key\": \"label\",\n \"value\": \"Personal\"\n },\n {\n \"key\": \"is\",\n \"value\": \"starred\"\n }\n ]\n }\n ]\n }\n}\n```\nThis will return emails after 7th of Jan that are either starred or have the label \"Personal\". \nNote that this is the highest level of nesting we support, i.e. you can't add more AND/OR filters within the OR filter\nin the above example.",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GmailSyncInput"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/rss_feed": {
"post": {
"tags": [
"Integrations"
],
"summary": "Rss Feed",
"operationId": "Integrations_syncRssFeed",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/RSSFeedInput"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/outlook/sync": {
"post": {
"tags": [
"Integrations"
],
"summary": "Outlook Sync",
"operationId": "Integrations_syncOutlook",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "Once you have successfully connected your Outlook account, you can choose which emails to sync with us\nusing the filters and folder parameter. \"folder\" should be the folder you want to sync from Outlook. By default\nwe get messages from your inbox folder. \nFilters is a JSON object with key value pairs. It also supports AND and OR operations.\nFor now, we support a limited set of keys listed below.\n\n<b>category</b>: Custom categories that you created in Outlook. \n<b>after</b> or <b>before</b>: A date in YYYY/mm/dd format (example 2023/12/31). Gets emails after/before a certain date. You can also use them in combination to get emails from a certain period. \n<b>is</b>: Can have the following values: flagged \n<b>from</b>: Email address of the sender \n\nAn example of a basic query with filters can be\n```json\n{\n \"filters\": {\n \"key\": \"category\",\n \"value\": \"Test\"\n }\n}\n```\nWhich will list all emails that have the category \"Test\". \n\nSpecifying a custom folder in the same query\n```json\n{\n \"folder\": \"Folder Name\",\n \"filters\": {\n \"key\": \"category\",\n \"value\": \"Test\"\n }\n}\n```\n\nYou can use AND and OR operation in the following way:\n```json\n{\n \"filters\": {\n \"AND\": [\n {\n \"key\": \"after\",\n \"value\": \"2024/01/07\"\n },\n {\n \"OR\": [\n {\n \"key\": \"category\",\n \"value\": \"Personal\"\n },\n {\n \"key\": \"category\",\n \"value\": \"Test\"\n },\n ]\n }\n ]\n }\n}\n```\nThis will return emails after 7th of Jan that have either Personal or Test as category. \nNote that this is the highest level of nesting we support, i.e. you can't add more AND/OR filters within the OR filter\nin the above example.",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/OutlookSyncInput"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/freshdesk": {
"post": {
"tags": [
"Integrations"
],
"summary": "Freshdesk Connect",
"operationId": "Integrations_connectFreshdesk",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "Refer this article to obtain an API key https://support.freshdesk.com/en/support/solutions/articles/215517.\nMake sure that your API key has the permission to read solutions from your account and you are on a <b>paid</b> plan.\nOnce you have an API key, you can make a request to this endpoint along with your freshdesk domain. This will \ntrigger an automatic sync of the articles in your \"solutions\" tab. Additional parameters below can be used to associate \ndata with the synced articles or modify the sync behavior.",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/FreshDeskConnectRequest"
}
}
},
"required": true
},
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenericSuccessResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/outlook/user_folders": {
"get": {
"tags": [
"Integrations"
],
"summary": "Outlook Folders",
"operationId": "Integrations_listFolders",
"security": [
{
"accessToken": [
]
},
{
"apiKey": [
],
"customerId": [
]
}
],
"description": "After connecting your Outlook account, you can use this endpoint to list all of your folders on outlook. This includes \nboth system folders like \"inbox\" and user created folders.",
"parameters": [
{
"name": "data_source_id",
"in": "query",
"required": false,
"schema": {
"title": "Data Source Id",
"type": "integer",
"nullable": true
}
}
],
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/IntegrationsListFoldersResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/integrations/outlook/user_categories": {
"get": {