1,767,181 events recorded by gharchive.org of which 1,767,181 were push events containing 2,802,533 commit messages that amount to 211,417,918 characters filtered with words.py@e23d022007... to these 27 messages:
[MIRROR] Removes (in) smoke and foam reactions [MDB IGNORE] (#13963)
-
Removes (in) smoke and foam reactions (#67270)
-
Removes smoke and foam reactions
Turns out when you let reagents react in foam/smoke, people put bombs in them.
This behavior was initially added to just smoke, accidentially in (56f7ac0c0a29e8f898c4aab35947d027952b43f7) accidentialy (thalpy tried to make both foam and smoke instant react, but instead made smoke's temporary holder reagent instant instead. hhhhhhh)
Assuming this was intentional it was then extended to foam in (1879e2d338c9bf5f191cef6c39944b26a41e6092)
Basically, we're idiots. Anyway lets just walk this all back to instant reaction on smoke/foam formation. Hate you people
- Removes another source of gunpowder smoke
Temporal told me about this. Gunpowder uses an ex_act signal as a starter, and that also counts for smoke objects.
Really don't want instant detonation smoke bombs, so let's just... not shall we?
- Removes (in) smoke and foam reactions
Co-authored-by: LemonInTheDark [email protected]
I did so much work on moment of inertia
I did alot of work most of it being thinking and now im tired it isn't finished but I should commit because I would die if I lost this work I'm so close to death from this it's not even funny arghghghhhhh ill do more tomorrow this is fun
Rename src/dds.imageio/squish/simd.h -> squish-simd.h (#3424)
This tiny change is a quality-of-life fix for me, addressing the fact that there are two different simd.h files in our code base. I never would have done that on purpose, but one of them is part of the imported "squish" source code that we use for dds encoding.
For years I've been frustrated that reflexively typing CMD-P simd.h
in the editor has a 50/50 chance of pulling in this file, when in fact
there is literally a 100% chance of my wanting
src/include/OpenImageIO/simd.h.
So finally put my editing brain out of its misery by renaming the file that I never want to edit.
Parallax but better: Smooth movement cleanup (#66567)
- Alright, so I'm optimizing parallax code so I can justify making it do a bit more work
To that end, lets make the checks it does each process event based. There's two. One is for a difference in view, which is an easy fix since I added a view setter like a year back now.
The second is something planets do when you change your z level. This gets more complicated, because we're "owned" by a client. So the only real pattern we can use to hook into the client's mob's movement is something like connect_loc_behalf.
So, I've made connect_mob_behalf. Fuck you.
This saves a proc call and some redundant logic
- Fixes random parallax stuttering
Ok so this is kinda a weird one but hear me out.
Parallax has this concept of "direction" that some areas use, mostly the shuttle transit ones. Set when you move into a new area. So of course it has a setter. If you pass it a direction that it doesn't already have, it'll start up the movement animation, and disable normal parallax for a bit to give it some time to get going.
This var is typically set to 0.
The problem is we were setting /area/space's direction to null in shuttle movement code, because of a forgotten proc arg.
Null is of course different then 0, so this would trigger a halt in parallax processing.
This causes a lot of strange stutters in parallax, mostly when you're moving between nearspace and space. It looks really bad, and I'm a bit suprised none noticed.
I've fixed it, and added a default arg to the setter to prevent this class of issue in future. Things look a good bit nicer this way
- Adds animation back to parallax
Ok so like, I know this was removed and "none could tell" and whatever, and in fairness this animation method is a bit crummy.
What we really want to do is eliminate "halts" and "jumps" in the parallax moveemnt. So it should be smooth.
As it is on live now, this just isn't what happens, you get jumping between offsets. Looks frankly, horrible. Especially on the station.
Just what I've done won't be enough however, because what we need to do is match our parallax scroll speed with our current glide speed. I need to figure out how to do this well, and I have a feeling it will involve some system of managing glide sources.
Anyway for now the animation looks really nice for ghosts with default (high) settings, since they share the same delay.
I've done some refactoring to how old animation code worked pre (4b04f9012d1763df625e9e4ae75e4cf4bd1f3771). Two major changes tho.
First, instead of doing all the animate checks each time we loop over a layer, we only do the layer dependant ones. This saves a good bit of time.
Second, we animate movement on absolute layers too. They're staying in the same position, but they still move on the screen, so we do the same gental leaning. This has a very nice visual effect.
Oh and I cleaned up some of the code slightly.
Fuck you, import mod from drag and drop and ask for character name
Adds surplus crate-only items. (#256)
-
Funny stuff right here
-
is this piece of shit ACTUALLY complaining about indentation in a fucking comment fuck you
Fix point vendors (#259)
-
Fix point vendors bluescreening if accessed with an ID with no registered account
-
You can't (brokenly) take apart point vendors anymore
-
Moves the point vendors to the FUCKIGN VENDING DIRECTORY HOLY SHIT TCEO WHY DID YOU PUT THEM IN ECONOMY YOU IDIOT
MAINT: add SCIPY_USE_PROPACK env variable (#16361)
-
this is effectively a forward port and modernization of the release branch
PROPACKshims that were added in gh-15432; in short,PROPACK+ Windows + some linalg backends was causing all sorts of trouble, and this has never been resolved -
I've switched to
SCIPY_USE_PROPACKinstead ofUSE_PROPACKfor the opt-in, since this was requested, though the change between release branches may cause a little confusion (another release note adjustment to add maybe) -
I think the issues are painful to reproduce; for my part, I did the following just to check the proper skipping/accounting of tests:
SCIPY_USE_PROPACK=1 python dev.py -j 20 -t scipy/sparse/linalg932 passed, 172 skipped, 8 xfailed in 115.57s (0:01:55)
python dev.py -j 20 -t scipy/sparse/linalg787 passed, 317 skipped, 8 xfailed in 114.80s (0:01:54)
- why am I doing this now? well, to be frank the process of manually
backporting this for each release is error-prone, and may cause
additional confusion/debate, which I'd like to avoid. Besides, if it
is broken in
mainwe may as well have the shims there as well. I would point out that you may want to addSCIPY_USE_PROPACKto 1 or 2 jobs in CI? The other reason is that if usage ofPROPACKspreads, I don't want to be manually applying more skips/shims on each release (which I already had to do here with two new tests it seems)
Use a different way to tell where the syscall handler was interrupted on FreeBSD and macOS
I was using a global variable. This would be set to '1' just before calling the function to save cflags and cleared just after, then using the variable to fill in the 'outside_rnage_ condition in VG_(fixup_guest_state_after_syscall_interrupted)
Even though I haven't experienced any isseus with that, the comments just before do_syscall_for_client made me want to try an alternative.
This code is very ugly and won't please the language lawyers. Functions aren't guaranteed to have an address and there is no guarantee that the binary layout will reflect the source layout. Sadly C doesn't have something like "sizeof(*function)" to give the size of a function in bytes. The next best that I could manage was to use dummy 'marker' functions just after the ones I want the end address of and then use the address of 'marker - 1'
I did think of one other way to do this. That would be to generate a C file containing the function sizes. This would require
- "put_flag_size.c" would depend on the VEX guest_(x86|amd64)_helpers object files
- Extract the sizes, for instance
echo -n "const size_t x86_put_eflag_c_size = 0x" > put_flag_size.c nm -F sysv libvex_x86_freebsd_a-guest_x86_helpers.o | awk -F| '/LibVEX_GuestX86_put_eflag_c/{print $5}' >> put_flag_size.c echo ";" >> put_flag_size.c
That seems fairly difficult to do in automake and I'm not sure if it would be robust.
random: credit cpu and bootloader seeds by default
This commit changes the default Kconfig values of RANDOM_TRUST_CPU and RANDOM_TRUST_BOOTLOADER to be Y by default. It does not change any existing configs or change any kernel behavior. The reason for this is several fold.
As background, I recently had an email thread with the kernel maintainers of Fedora/RHEL, Debian, Ubuntu, Gentoo, Arch, NixOS, Alpine, SUSE, and Void as recipients. I noted that some distros trust RDRAND, some trust EFI, and some trust both, and I asked why or why not. There wasn't really much of a "debate" but rather an interesting discussion of what the historical reasons have been for this, and it came up that some distros just missed the introduction of the bootloader Kconfig knob, while another didn't want to enable it until there was a boot time switch to turn it off for more concerned users (which has since been added). The result of the rather uneventful discussion is that every major Linux distro enables these two options by default.
While I didn't have really too strong of an opinion going into this thread -- and I mostly wanted to learn what the distros' thinking was one way or another -- ultimately I think their choice was a decent enough one for a default option (which can be disabled at boot time). I'll try to summarize the pros and cons:
Pros:
-
The RNG machinery gets initialized super quickly, and there's no messing around with subsequent blocking behavior.
-
The bootloader mechanism is used by kexec in order for the prior kernel to initialize the RNG of the next kernel, which increases the entropy available to early boot daemons of the next kernel.
-
Previous objections related to backdoors centered around Dual_EC_DRBG-like kleptographic systems, in which observing some amount of the output stream enables an adversary holding the right key to determine the entire output stream.
This used to be a partially justified concern, because RDRAND output was mixed into the output stream in varying ways, some of which may have lacked pre-image resistance (e.g. XOR or an LFSR).
But this is no longer the case. Now, all usage of RDRAND and bootloader seeds go through a cryptographic hash function. This means that the CPU would have to compute a hash pre-image, which is not considered to be feasible (otherwise the hash function would be terribly broken).
-
More generally, if the CPU is backdoored, the RNG is probably not the realistic vector of choice for an attacker.
-
These CPU or bootloader seeds are far from being the only source of entropy. Rather, there is generally a pretty huge amount of entropy, not all of which is credited, especially on CPUs that support instructions like RDRAND. In other words, assuming RDRAND outputs all zeros, an attacker would still have to accurately model every single other entropy source also in use.
-
The RNG now reseeds itself quite rapidly during boot, starting at 2 seconds, then 4, then 8, then 16, and so forth, so that other sources of entropy get used without much delay.
-
Paranoid users can set random.trust_{cpu,bootloader}=no in the kernel command line, and paranoid system builders can set the Kconfig options to N, so there's no reduction or restriction of optionality.
-
It's a practical default.
-
All the distros have it set this way. Microsoft and Apple trust it too. Bandwagon.
Cons:
-
RDRAND could still be backdoored with something like a fixed key or limited space serial number seed or another indexable scheme like that. (However, it's hard to imagine threat models where the CPU is backdoored like this, yet people are still okay making any computations with it or connecting it to networks, etc.)
-
RDRAND could be defective, rather than backdoored, and produce garbage that is in one way or another insufficient for crypto.
-
Suggesting a reduction in paranoia, as this commit effectively does, may cause some to question my personal integrity as a "security person".
-
Bootloader seeds and RDRAND are generally very difficult if not all together impossible to audit.
Keep in mind that this doesn't actually change any behavior. This is just a change in the default Kconfig value. The distros already are shipping kernels that set things this way.
Ard made an additional argument in [1]:
We're at the mercy of firmware and micro-architecture anyway, given
that we are also relying on it to ensure that every instruction in
the kernel's executable image has been faithfully copied to memory,
and that the CPU implements those instructions as documented. So I
don't think firmware or ISA bugs related to RNGs deserve special
treatment - if they are broken, we should quirk around them like we
usually do. So enabling these by default is a step in the right
direction IMHO.
In [2], Phil pointed out that having this disabled masked a bug that CI otherwise would have caught:
A clean 5.15.45 boots cleanly, whereas a downstream kernel shows the
static key warning (but it does go on to boot). The significant
difference is that our defconfigs set CONFIG_RANDOM_TRUST_BOOTLOADER=y
defining that on top of multi_v7_defconfig demonstrates the issue on
a clean 5.15.45. Conversely, not setting that option in a
downstream kernel build avoids the warning
[1] https://lore.kernel.org/lkml/CAMj1kXGi+ieviFjXv9zQBSaGyyzeGW_VpMpTLJK8PJb2QHEQ-w@mail.gmail.com/ [2] https://lore.kernel.org/lkml/[email protected]/
Cc: Theodore Ts'o [email protected] Reviewed-by: Ard Biesheuvel [email protected] Signed-off-by: Jason A. Donenfeld [email protected]
Makes Hell Microwaves Not Use Power (#67413)
Hey there,
I was informed that the holodeck program Microwave Paradise would draw and suck power out of an APC. Didn't intend for that to happen, and while funny, I don't really want to arm the crew with le epic power sink with very little effort than pressing a button, or warranting this to eventually be locked to "dangerous" programs. So, let's change such that this subtype of microwaves that can not be constructed (only mapped/spawned) doesn't consume any power. I don't know why it drew off the nearest APC or how that works, but this seems to be alright.
It's not possible to deconstruct machinery spawned in at the Holodeck (which I verified while testing this PR), so do not worry about people using this to bypass the power economy for whzhzhzhz purposes.
Life is one big road with lots of signs. So when you riding through the ruts, don't complicate your mind. Flee from hate, mischief and jealousy. Don't bury your thoughts, put your vision to reality. Wake Up and Live!
Bagel Update 13.7 (#8690)
-
fuck shit ass shit
-
Add files via upload
Created Text For URL [www.express.co.uk/news/science/1622197/elon-musk-humiliated-scientist-slam-spacex-ceo-stupidest-idea-mars-mission]
I hate Lua 5.1 and LuaU.
I'm very sorry if you are going to the point of saying that it doesn't work on Lua 5.1 or LuaU but this version is so fucking retarded.
"9:05am. Went to bed at 1am, slept lightly, and yet right now I am raring to go.
9:15am. https://youtu.be/lbUluHiqwoA OpenAI’s DALL-E 2: Even More Beautiful Results! 🤯
Let me start off slowly.
https://youtu.be/lbUluHiqwoA?t=43
Oh wow, this is really good upscaling.
https://youtu.be/lbUluHiqwoA?t=131
Illustrating a fantasy novel.
Sigh, I do want this. Too bad I don't have the money for it.
https://youtu.be/lbUluHiqwoA?t=539
I should consider Weights & Biases as my cloud service.
https://arxiv.org/abs/2204.06125 Hierarchical Text-Conditional Image Generation with CLIP Latents
Here is DALLE 2. Let me read it a bit. After that I'll set the render. I'll try letting it run for 15m undisturbed.
Just why is Arxiv so slow. It seems downloading a 40mb file takes a long time for it.
9:55am. https://numenta.com/blog/2022/05/24/ai-is-harming-our-planet
Past the middle, they talk about how to make the models efficient.
Sparsity, ref frames, continual learning, optimized hardware.
https://www.frontiersin.org/articles/10.3389/fnbot.2022.846219/full#B22 Avoiding Catastrophe: Active Dendrites Enable Multi-Task Learning in Dynamic Environments
After discussing background material, we propose a new architecture that incorporates dendrites and sparse representations into deep learning. We then test our architecture on one representative benchmark from each of the two scenarios, multi-task RL and continual learning. We show experimental results on a standard multi-task RL benchmark, Meta-World. We also show results on a standard continual learning benchmark, permutedMNIST. The results in both cases show that an identical architecture with active dendrites performs well in both benchmarks. Finally, we analyze the results and show that active dendrites and sparse representations help with catastrophic forgetting and gradient interference by learning to create task-specific subnetworks where representations are sparse and mostly orthogonal. Overall, our results suggest that detailed biological properties of neurons can be used to address dynamic scenarios that are difficult for traditional ANNs to solve.
Numenta guys are actually making progress it seems.
///
2.2.1. Neurons and Active Dendrites The pyramidal neuron is the most prevalent neuron type found in the neocortex and hippocampal areas (Spruston, 2008; Ramaswamy and Markram, 2015). In particular they represent the most common excitatory neuron type found in areas associated with advanced cognitive functions (Spruston, 2008). A typical pyramidal neuron has an extensive dendritic tree containing thousands of synapses, each receiving input from another neuron (y Cajal, 1894; Bentivoglio and Swanson, 2001; Kandel, 2012). The point neuron model (Lapique, 1907) postulates that all of these synapses have a linear impact on the cell. This simple assumption formed the basis for Rosenblatt's original Perceptron (Rosenblatt, 1958) and continues to form the basis for current deep learning systems and ANNs (McClelland et al., 1986; LeCun et al., 2015).
Today it is well-known that the point neuron assumption is an oversimplified model of biological computations. Proximal synapses (close to the cell body) have a linear impact on the neuron, but the vast majority of synapses are located on distal dendritic segments (far from the cell body) and individually have minimal impact on the cell. These distal segments process groups of synapses locally in a non-linear fashion, and are known as active dendrites (Magee, 2000; Antic et al., 2010; Major et al., 2013; Stuart and Spruston, 2015; Stuart et al., 2016). Empirical evidence (London and Häusser, 2005; Branco and Häusser, 2010) suggests that each distal dendritic segment acts as a separate active subunit performing its own local computation. Modeling studies show that neurons with active dendrites are more powerful and complex than the point neuron model can accommodate (Poirazi et al., 2003; Jadi et al., 2014; Poirazi and Papoutsi, 2020; Beniaguev et al., 2021).
///
I really like this paper. I am wondering what these active dendrites are and how they different from point neurons.
///
-
Active Dendrites Network Model Our primary goal is to augment standard ANNs with the biological properties described above. The extensions should be general and applicable to a range of complex scenarios such as multi-task RL and continual learning. The key aspects of our model are summarized as follows, with details noted in the rest of this section:
-
Pyramidal neurons integrate a range of diverse inputs on multiple independent dendritic segments. To model this, we implement neurons that separate out contextual inputs from feedforward inputs. Each neuron processes the feedforward input using a linear weighted sum. A set of independent dendritic segments process the contextual input using a separate set of weights.
-
Contextual inputs on active dendrites can modulate a neuron's response, making it more likely to fire. To model this, we implement a function that can up-modulate or down-modulate the feedforward activation based on dendritic activation.
-
Neural activity and connectivity are highly sparse. To model this, we incorporate a k-Winner-Take-All function (kWTA) that mimics biological inhibitory networks (Cui et al., 2017) and guarantees sparse activations.
The above properties are implemented such that the entire network is differentiable and trainable end-to-end using backpropagation. This makes the architecture suitable for testing on any standard deep learning scenario.
///
Backprop. In order to get away from it, it will be necessary to get hardware that works differently. It is easy to think about the nets in terms of layer hierarchies, but I bet that going beyond backprop will take mastering continual learning and then reimagining the hierarchy as temporal.
We apply a kWTA activation function (Ahmad and Scheinkman, 2019) as our choice of non-linear activation in each hidden layer of the network:
I actually played around with this 2015. I found that you can train a net using relu, and swap between kWTA and it without any retraining.
We make two notes: first, only the neurons that were selected by the kWTA function will have non-zero activations (and thus non-zero gradients). Therefore, during the backward pass, only the weights corresponding to those winning neurons will be updated.
This is consistent with how backprop works.
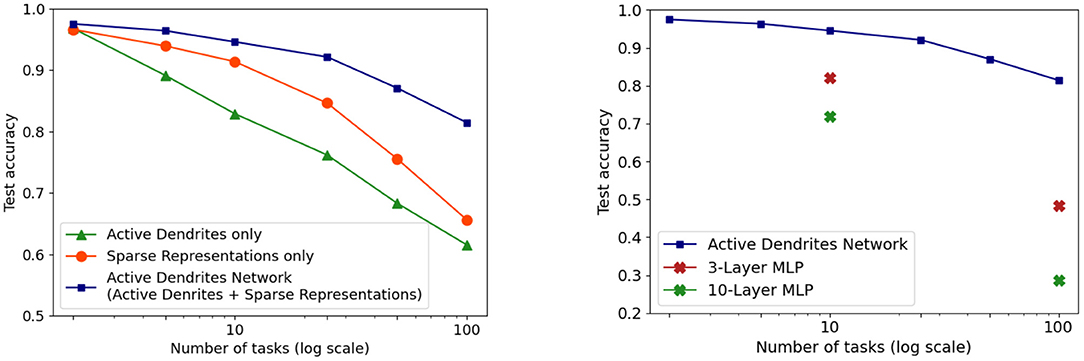
10:25am. The performance over the baseline is really not that pronounced.
{kind=link}
Oh, they really make their case here.
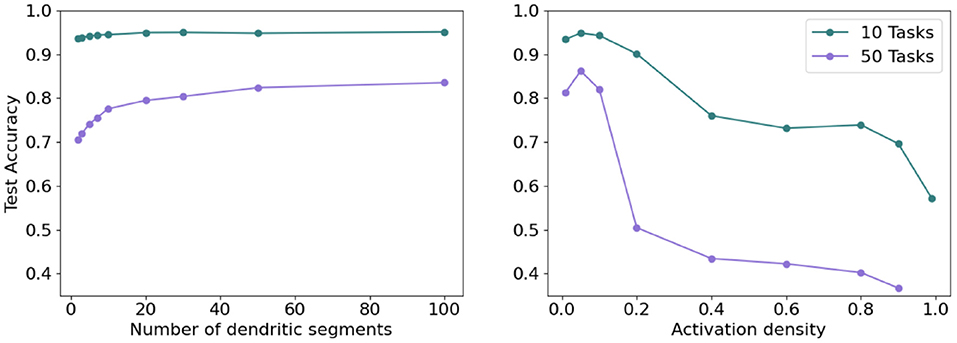{kind=link}
As well as here.
This is an interesting architecture. If I had to try RL again, I'd seriously consider it. At the very least, I am willing to concede I was wrong about, the cube activation. That way of doing it would lead to high catastrophic forgetting.
Also the way they calculate the context vector is novel. This has some similarity to recurrent nets, but I've always that that the way RNNs just multiple the hidden state together with the input did not make complete sense.
I am still not done with the paper.
10:45am. Instead of using euclidean distance minimization to select the context vector they should have used the transformer/Hopfield net update. That would have made things far easier for them.
11am. This has taken up my attention. I suppose this paper would be a lot more valuable if I had hardware that could take advantage of the efficiency gains of this. Though it already has some advantages with respect to credit assignment. I won't worry about this for now. I know that I can't tackle RL until I have the complete package. Mucking around like before won't work. Instead I'll focus on what NNs are good at which is art.
Even without huge algorithmic breakthrough, the sparsity direction they are going in here would be a valid way of cutting energy consumption on NNs drastically while retaining the same and even better performance. But it does need hardware capable of taking advantage of that.
11:25am. I finished rendering for 15m. Why did Luxcore's denoiser did not trigger at all?
Ah, there it is in the compositor.
Saved and compressed it. Now...
12pm. I've played around with it for a while. There isn't actually that much difference between the denoised and noisy version. I thought the effect would be a lot more pronounced. Let me post it in the /wip/ thread and Twitter. What I will do next is see if I can increase the degree of stylization.
12:10pm. I just realized, the image description on Twitter has a 1k char limit.
12:15pm. Let me check out the AdaIn paper.
As well as doing that, let me ask the author.
https://github.com/zyxElsa/CAST_pytorch/issues/
I opened issue 4 here.
Now let me read the paper. I'll actually try it out after breakfast. After that I guess I can get started working on the cover for Heaven's Key.
I am really looking forward to the author posting the training code for this. Right now there are still things that are unclear to me.
///
Content-style trade-off. The degree of style transfer can be controlled during training by adjusting the style weight λ in Eqa. 11.
///
I am reading the paper. They in fact talk about a convex combination of styles. I guess I'll have to give it a try.
Let me give it a try. Then I will have breakfast. I am really interested if the net can go more in the stylized direction.
def forward(self, content, style, style_weight = 1.5):
content_feats = self.encode(content)
if style_weight == 0:
return content_feats
else:
style_feats = self.encode(style)
adain_feat = self.adain(content_feats, style_feats)
if style_weight == 1: return adain_feat
else: return (1 - style_weight) * content_feats + style_weight * adain_featThis should do it.
12:55pm. Let me try out the other decoder. I want to see what is going on with it.
The results it gives are completely different. I am really convinced now that it is necessary for the sake of going from syle to realistic images while the first one is realistic -> style.
I wonder how this works? I really want to see the training code now. Hopefully the author comes through with it.
1:10pm. Let me have breakfast here. That should be enough as far as style transfer is concerned. I do not want to fool with this anymore. Later I will do some adaptation so I can run the dataset A on multiple styles in B. I am also tired of renaming by hand, so I'll fix that. But that is about it.
I certainly won't be setting this up on the cloud and trying to train it myself. Not until I get some decent resources. The way this works now is wonderful, I really don't need anything more. It was literally a fortuitous encounter giving me what I needed the most at exactly the time I wanted it.
Later when it comes out, I will study the training code to slate my curiosity, but otherwise, I expect that my next foray into NNs will be on the audio side.
I'll proabbly be using it for voice synthesis and style transfer as well.
These tools are really good, now that I am not demanding them to tackle impossible RL challenges. This is the way to do it. Eventually in the future, I will get a proper lead for how to do RL. The signs are there, but I really am going to need that 10,000x gain in efficiency like the Numenta article suggested.
Sparsity is a low hanging fruit that still hasn't been picked. Once that is done, it will be turn to crack long term memories. On one of the yearly reviews I said that I would take advantage of ML as I go along instead of trying to tackle it myself. What I've been doing is actually that plan being put into practice."
[pkg] keep backwards-compatibility for helper location
I am honestly amazed at all the things that went wrong with the commit a0f8afb97d2218b4f987779c5b2b by sam:
- attempted to fix something that was not broken
- bumped the build dependency from go 1.14 to go 1.17, even when he had been warned that we try to keep backward compatibility to be able to build the client in standard or limited enviroments.
- if you (meaning, any future maintainer) are tempted to bump the go version we depend on again, please make sure that the snap, win and mac build procedures are updated accordingly.
- removing one extra dependency is ok, but maintaining compabilitiy for builds is even more importan-ter.
- you cannot just change paths of a top-level folder without grepping for the use of those paths. period. I see you fixed linux in 5ed27792f38e974922a8u, but branding/ scripts still depend on that.
- if you are going to do this, please open a review process and wait for others to chime in.
- if you are not sure, just fucking ask.
(I better won't mention how many hours were invoiced for this commit, because that's fucking unprofessional, lol).
on the positive side, i've learned a few things that can go to a style guide in the near future. that's something, I guess :)
holy shit I fixed it. AMAZING. Though, idk how I fixed it. lol 😧
"2:25pm. https://www.lightnovelpub.com/novel/the-legendary-mechanic-novel-08061141/245-chapter-121
Let me read this and then I will get started. I am not sure on what exactly?
I guess I'll have to sketch out the Heaven's Key cover. Then I will model it in 3d. It won't take too long. I'll do two versions. After that is done, I will do some chara modeling. At least Euclid and an NPC model.
After I clear that hurdle, I think I will be done with the art stage. After I am done with that, I will move on to music as per plan. After I clear music, it will be time to start Heaven's Key.
Hmmmm...remember those videos on 3d reconstruction? It might be worth looking into that. If I could get that in addition to style transfer, it would make my work a lot easier. I could make small changes and turn photograhs into assets without issue.
Right. Ok. I'll make that my next goal. Not necessarily to get it, but just to research how it works. Just like with CAST and NNST I'll see whether I can extract something useful from the repos if the code is available.
///
902120 Investigated it, and it is possible, but not like with DDG. It feels like the net is basically a single agent that is skilled at imitation, but still has a single style underneath it all. There is not too much variety in the nets approach to the problem. This is not too bad, as humans in general have only a single style. I am not disappointed in it the least.
It is just that I am curious what it would be capable if I had 10-1000x better hardware. I hope the AI chip wave won't take too long before it arrives.
///
3:10pm. Whops, I got engrossed in it. I need to resume. First then, let me do some research on 3d reconstruction. I'll quell my skepticism and investigate it properly.
https://youtu.be/eCDBA_SbxCE?t=591 3D Deep Learning with PyTorch3D by Nikhila Ravi
I started this a while ago, but dropped it around the 10m mark. Let me watch it. Then I'll hunt down the paper on that reconstructed sax.
https://youtu.be/eCDBA_SbxCE?t=906
Pairwise distance matrix? Huh, is this anything like what NNST is doing? Before that they talked about nearest neighbors.
...No started working on a post, but I changed my mind. I do not understand NNST well enough to tell if this would be useful there. If it was on 2d data sure, but this should be operating on 3d data which is different from how NNST works.
https://youtu.be/eCDBA_SbxCE?t=995
Mesh R-CNN
I need to keep it in mind. I forgot about it by now.
https://youtu.be/eCDBA_SbxCE?t=1677
3d shape prediction. Is that going from 2d -> 3d? If so, then I am interested. If I could make use of this, it would significantly improve my modeling ability. The less I do things on my own, and the more the NN does it, the better off I'll be.
https://youtu.be/eCDBA_SbxCE?t=1695
We have tutorials for these 4 examples.
The beautiful thing about all of this even if for example 3d reconstruction does not work perfectly, this is not like poker where the method would be useless. Even if it is only moderately good, I would be able to manage it.
I have no idea what bundle adjustment and pose optimization are.
https://youtu.be/9r9TDr2Aq5A Learning 3D Reconstruction in Function Space (Long Version)
Is there anything more recent?
https://youtu.be/j8tMk-GE8hY NVIDIA’s New AI: Wow, Instant Neural Graphics! 🤖
The author of the Two Minute Papers channel is a light transport researcher, so this is up his alley. This is what I should be looking into.
https://youtu.be/j8tMk-GE8hY?t=191
We can keep zooming in, and zooming in...
Can I use this? It is not necessarily what I want, but it is adjacent to what I want.
https://youtu.be/j8tMk-GE8hY?t=247
This is a neural signed distance field it has produced.
So a volume then? That could be converted into a mesh without much issue.
https://youtu.be/j8tMk-GE8hY?t=330
Lambda GPU Cloud.
Instead of Google I'll keep that in mind. I think W&B is more for trackign of experiments.
https://youtu.be/j8tMk-GE8hY?t=370
1.5$/h for 4 GPUs. That is not too much.
https://nvlabs.github.io/instant-ngp/ Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
Here is the paper being talked about.
https://youtu.be/2Bw5f4vYL98 How Well Can DeepMind's AI Learn Physics? ⚛
Let me take a short break here.
4:30pm. I am back. This is firing up my imagination. Let me watch the Deepmind vid and then I'll take a look at the hash encoding paper as well as the accompanying video.
https://youtu.be/2Bw5f4vYL98?t=48
If we can write a simulator that runs the laws of physics to create these programs why would we need learning based algorithms?
Good question.
https://youtu.be/2Bw5f4vYL98?t=412
He says that Lambda Cloud can train ImageNET to 93% for less than 19$.
https://youtu.be/nkHL1GNU18M Physics in 4 Dimensions…How?
Let me learn this stuff. What a time to be alive.
Yeah, this is the way to go. I've completely botched my life, this is the easy to road I should have taken.
https://youtu.be/QrsxIa0JDi4 These Smoke Simulations Have A Catch! 💨
https://youtu.be/QrsxIa0JDi4?t=304
He says it does not need the GPU and runs on the CPU instead.
https://youtu.be/QrsxIa0JDi4?t=312
Yeah, indeed, if I tried this in Blender it would take forever. I hate doing sims.
https://youtu.be/QrsxIa0JDi4?t=321
Oh damn, this is such a huge memory requirement.
He mentions towards the ends that there are techniques to compress that. Work for future papers.
5pm. https://youtu.be/t33jvL7ftd4 This AI Learned Some Crazy Fighting Moves! 🥊
https://youtu.be/t33jvL7ftd4?t=320
Node based ML. I was wondering when I'd run into that.
https://youtu.be/M0RuBETA2f4 A Repulsion Simulation! But Why? 🐰
https://youtu.be/M0RuBETA2f4?t=257
This can do path planning without collisions.
https://youtu.be/aPiHhJjN3hI DeepMind’s New AI Thinks It Is A Genius! 🤖
5:25pm. Nevermind this. I had enough. Let me watch the
https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.mp4
Let me watch the multires hashing video.
5:35pm. Actually let me link to it.
https://github.com/nvlabs/tiny-cuda-nn
This has a MLP optimized to the limit it seems. It says it loads the weights only once.
5:40pm. No, this paper is not what I am looking for.
https://youtu.be/5j8I7V6blqM NVIDIA’s New AI Grows Objects Out Of Nothing! 🤖
This was the paper I was thinking about.
This is one of the links. It seems the term I am looking for is inverse 3d rendering.
Focus me, let me watch the video.
5:55pm. https://www.youtube.com/watch?v=klqYq0RUSC8 Is Nvidia Crazy?? (RTX 4090 Ti rumors, used GPUs market) - TalkLinked #8
I want to watch this, but seriously, it is just random news that I got baited on. Focus me. It would be another thing if I could afford a 40xx card. Watching this now would just be a waste of time.
https://nvlabs.github.io/nvdiffrec/
This is the link I need to study. There is code for this which I will be checking out. First let me watch the video. It is only 2.5m.
3D content creation is a challenging, mostly manual task which requires both artistic modeling skills and technical knowledge. Efforts to automate 3D modeling can save substantial production costs or allow for faster and more diverse content creation. Photogrammetry [54,62] is a popular technique to assist in this process, where multiple photos of an object are converted into a 3D model. Game studios leverage photogrammetry to quickly build highly detailed virtual landscapes [24]. However, this is a multi-stage process, including multi-view stereo [58] to align cameras and find correspondences, geometric simplification, texture parameterization, material baking and delighting. This complex pipeline has many steps with conflicting optimization goals and errors that propagate between stages. Artists rely on a plethora of software tools and significant manual adjustments to reach the desired quality of the final 3D model.
I've moved to the paper. Movies are a thing, if I really need multiple images I could get it from that.
We leverage the tiny-cuda-nn framework [46], which provides efficient kernels for hashgrid positional encoding [47] and MLP evaluations.
I keep thinking about the reference frames Jeff Hawkins talked about. I wonder how this relates to it.
6:30pm. https://github.com/NVlabs/nvdiffrec
Do I want to give this a try?
https://github.com/neurall/nvdiffrecColab/
Sadly this algo requires you to provide masks in alpha of images (like it is done in synthetic nerf datasets) as this mask detection is not part of this algo pipeline yet.
6:35pm. I am thinking whether I should try this, and I am leaning towards no. Since it requires ref images from multiple sides, this is a lot less useful that is could be from me. Right now, the only thing I am wondering about is whether this could get me anything useful with just a single image? Let me ask the author.
6:45pm. https://github.com/NVlabs/nvdiffrec/issues
///
I am thinking of giving this a try, but for most of what I'd want to sketch out in 3d I'd only have a single ref image. Could this algorithm give me anything useful in such a situation or does it require shots from all sides? Of course I am not expecting a full 3d model that includes the sides missing in the image, but merely something that could be used a bit more flexibly compared to taking the same image and putting it on a plane.
///
Opened issue 49. I am really skeptical that this method could give me anything useful. 3d requires real understanding of the object form, so I am not sure how much a ML based method could give me without quality shots from different sides.
...No, I do not think it will work. Maybe I'll get a positive reply, in that case good, but otherwise I should forget about this. Style transfer is a big enough gain on its own. And I'll have gains in audio in the future.
6:50pm. Yeah, forget it. Tomorrow I need to start modeling. Forget the laze, and start modeling. I'll get the cover done and move on.
///
No, if you only use a single view, you will get a reasonable image from that particular view, but the 3D geometry will be bad as soon as you move the camera. We typically train with 50+ views, assuming full 360 coverage.
///
I got a reply really promptly on the issue I've opened. It roughly what I expected. I could move the paragraph at the start of the entry here and it would have made perfect sense.
Let me have lunch here. I am done for the day. I am going to prep my mind and start modeling out the scene tomorrow. I'll work out some circus buildings, some regular buildings, and the overall setup. I am going to take the lesson from the room to heart and not put in needless detail. I'll also learn to use blur smartly. I am going to also locate some displacement maps of planet Earth that I could put on a sphere, as well as textures for it. I am going to work smartly.
Artistic stylization really focuses on bringing out the essence of an image by sharpening particular aspects of it and dulling others, while realism focuses on layering details. The first one is a lot easier to create quickly if you know what you are doing. 3d has a lot to offer for regular art if you know how to use it smartly. Even though I have CAST, I should not hesitate to use DDG as well if I want stronger stylization. According to the conclussion of the paper, future work will involve immitating specific artist styles, so that will be something to really look forward to.
This what I need to practice. Rather than be satisfied with 3/5, if I can optimize my workflow I'll go straight to 4/5. Style transfer taught me a lesson and showed me the way forward. I just need to follow that path to its conclussion."
New species: Meteoran
Time pressure often creates exciting gameplay and interesting tradeoffs. Baseline Dungeon Crawl uses the Zot Clock to add a very weak form of time pressure, but there's so much variety between the playstyles of different species and backgrounds that a tight clock for some would be almost impossible for others.
So, let's try limiting that gameplay to just one species! Meteorae have an exciting variety of bonuses - great attributes and aptitudes across the board, passive mapping, and exploration healing, regaining HP and MP when viewing new territory. In exchange, they have one big downside: instead of getting 6,000 turns of Zot clock for each floor, they get 600!
The big concern here is whether this species can be made fun without also being made wildly, boringly 'overpowered'. Lots of levers and knobs to tweak, so let's give it a shot!
Extra notes:
- Meteorae are humanoid beings. (In the night sky, they look like dots because they're very far up.) Hat tip to Neil Gaiman's Stardust.
- This commit has a silly 'flavour' gimmick where Meteorae's LOS radius decreases by 2 when they have less than 50 turns left of Zot clock, and again when they have less than 10. Darkness is closing in...
- Meteorae glow in the dark. Permanent backlit status (not halo!): +enemy to hit, -stealth, disables invis. Suppressed in forms. Seems funny.
Credit to hellmonk for the initial version of this species and pushing to make 'em happen. :)
modpost: file2alias: go back to simple devtable lookup
commit ec91e78d378cc5d4b43805a1227d8e04e5dfa17d upstream.
Commit e49ce14150c6 ("modpost: use linker section to generate table.") was not so cool as we had expected first; it ended up with ugly section hacks when commit dd2a3acaecd7 ("mod/file2alias: make modpost compile on darwin again") came in.
Given a certain degree of unknowledge about the link stage of host programs, I really want to see simple, stupid table lookup so that this works in the same way regardless of the underlying executable format.
Signed-off-by: Masahiro Yamada [email protected] Acked-by: Mathieu Malaterre [email protected] [nc: Omit rpmsg, sdw, fslmc, tbsvc, and typec as they don't exist here Add of to avoid backporting two larger patches] Signed-off-by: Nathan Chancellor [email protected] Signed-off-by: Sasha Levin [email protected] Signed-off-by: Kevin F. Haggerty [email protected] Change-Id: Ic632eaa7777338109f80c76535e67917f5b9761c
Updated *insult list
Removed -vore -gaylord -shitcurity -comdom -greytider -tator -lingbin -cluwn -monkey
Modified or fixed -Cheesemonger spelling -Knight-like from Captain-like -Comdom to dummy
Added -Bramin-sniffer -Raider -scum-sucker -mutie -headass -dumbass -ghoul -Kitten looking ass, added with Kit8bits permission
Now get your @pick(nouns_body) off my lawn.
...going right straight through all of it.. and leaving no fucking trail, as absolute zero wouldnt divide any better the Goedelian abstraction of an infinitely precise number.. nah, not even there you dont abadon your rationality, as it may very likel lead you to a so called safety, when all the senses overflowingly prepares you for ultimate end and then pefrom the harbour, no just resist, there in this very uncertain is vary you.. and yes is it pleasure to gave up and obey the lack of breathing air, it is pleasure to dive in loosing ones mind, it is pleasure to leave the pain behind and nor anymore feeling other peoples one.. then the humanity strikes you with the mass of bodies in tonnes of strikingly similar gestures at that very moment performed, its just passes you by and leaves you free of all this bullshit. This was written so many times before, said by better words, painted in all colours, sang aloud or silently whispered.. capitains log is now getting misty and loosing its sharp contours, and the word any distant and closr is steadily marching towards the very same morning as ever
panvk: Drop support for Midgard
We've discussed this at length and have agreed that Midgard + Vulkan is DOA, but have let the code linger. Now it's getting in the way of forward progress for PanVK... That means it's time to drop the code paths and commit t to not supporting it.
Midgard is only barely Vulkan 1.0 capable, Arm's driver was mainly experimental. Today, there are no known workloads today for hardware of that class, given the relatively weak CPU and GPU, Linux, and arm64. Even with a perfect Vulkan driver, FEX + DXVK on RK3399 won't be performant.
There is a risk here: in the future, 2D workloads (like desktop compositors) might hard depend on Vulkan. It seems this is bound to happen but about a decade out. I worry about contributing to hardware obsolescence due to missing Vulkan drivers, however such a change would obsolete far more than Midgard v5... There's plenty of GL2 hardware that's still alive and well, for one. It doesn't look like Utgard will be going anywhere, even then.
For the record: I think depending on Vulkan for 2D workloads is a bad idea. It's unfortunately on brand for some compositors.
Getting conformant Vulkan 1.0 on Midgard would be a massive amount of work on top of conformant Bifrost/Valhall PanVK, and the performance would make it useless for interesting 3D workloads -- especially by 2025 standards.
If there's a retrocomputing urge in the future to build a Midgard + Vulkan driver, that could happen later. But it would be a lot more work than reverting this commit. The compiler would need significant work to be appropriate for anything newer than OpenGL ES 3.0, even dEQP-GLES31 tortures it pretty bad. Support for non-32bit types is lacklustre. Piles of basic shader features in Vulkan 1.0 are missing or broken in the Midgard compiler. Even if you got everything working, basic extensions like subgroup ops are architecturally impossible to implement.
On the core driver side, we would need support for indirect draws -- on Vulkan, stalling and doing it on the CPU is a nonoption. In fact, the indirect draw code is needed for plain indexed draws in Vulkan, meaning Zink + PanVK can be expected to have terrible performance on anything older than Valhall. (As far as workloads to justify building a Vulkan driver, Zink/ANGLE are the worst examples. The existing GL driver works well and is not much work to maintain. If it were, sticking it in Amber branch would still be less work than trying to build a competent Vulkan driver for that hardware.)
Where does PanVK fit in? Android, for one. High end Valhall devices might run FEX + DXVK acceptably. For whatever it's worth, Valhall is the first Mali hardware that can support Vulkan properly, even Bifrost Vulkan is a slow mess that you wouldn't want to use for anything if you had another option.
In theory Arm ships Vulkan drivers for this class of hardware. In practice, Arm's drivers have long sucked on Linux, assuming you could get your hands on a build. It didn't take much for Panfrost to win the Linux/Mali market.
The highest end Midgard getting wide use with Panfrost is the RK3399 with the Mali-T860, as in the Pinebook Pro. Even by today's standards, RK3399 is showing its limits. It seems unlikely that its users in 10 years from now will also be using Vulkan-required 2030 desktop environment eye candy. Graphically, the nicest experience on RK3399 is sway or weston, with GLES2 renderers. Realistically, sway won't go Vulkan-only for a long-time.
Making ourselves crazy trying to support Midgard poorly in PanVK seems like letting perfect (Vulkan support) be the enemy of good (Vulkan support). In that light, future developers making core 2D software Vulkan-only (forcing software rasterization instead of using the hardware OpenGL) are doing a lot more e-wasting than us simply not providing Midgard Vulkan drivers because we don't have the resources to do so, and keeping the broken code in-tree will just get in the way of forward progress for shipping PanVK at all.
There are good reasons, after all, that turnip starts with a6xx.
(If proper Vulkan support only began with Valhall, will we support Bifrost long term? Unclear. There are some good arguments on both sides here.)
Signed-off-by: Alyssa Rosenzweig [email protected] Acked-by: Jason Ekstrand [email protected] Acked-by: Boris Brezillon [email protected] Part-of: https://gitlab.freedesktop.org/mesa/mesa/-/merge_requests/16915
HOLY SHIT SHUT UP (#742)
-
HOLY SHIT SHUT UP
-
Apply suggestions from code review
-
seeba sauce
Generate operator= bindings for non-Unpin C++ types.
This does not implement them for Unpin types, because those are harder architecturally, yet simultaneously less interesting: we know we can do it, it's just annoying. (This is because it requires we move to a query-based architecture first -- it's hard, otherwise, to integrate them into e.g. the Clone trait, otherwise.)
This also does not yet implement inline thunks, that will wait to a sooner followup.
Implementation note: so as to drop the return type, there is a little bit of a hack in here. Please forgive me! Overall, this change has been a net simplification -- unknown commit was also part of this -- so consider this just a wee technical debt.
The long-term solution could be some kind of overlay layer we have not yet designed, but I suspect, instead, the long term solution will be to split this into two functions: one which directly wraps operator=, and one which is the trait implementation and discards the return value. This requires (for the same reasons as the Unpin impls) a query-based architecturey thingy, and so is not part of this CL.
I could make the trait return the references, but it won't work with full generality. For example, someone can return an int from operator=. So, there's some design work to figure out what to do there, easily dodged by saying "we don't export the return value for now, using this little trick".
At any rate, it's only temporary, probably!
PiperOrigin-RevId: 453743406
Rollup merge of #97144 - samziz:patch-1, r=Dylan-DPC
Fix rusty grammar in std::error::Reporter docs
I initially saw "print's" instead of "prints" at the start of the doc comment for std::error::Reporter, while reading the docs for that type. Then I figured 'probably more where that came from', so, as well as correcting the foregoing to "prints", I've patched up these three minor solecisms (well, two types, three tokens):
- One use of the indicative which should be subjunctive - indeed the sentence immediately following it, which mirrors its structure, does use the subjunctive (L871). Replaced with the subjunctive.
- Two separate clauses joined with commas (L975, L1023). Replaced the first with a semicolon and the second with a period. Admittedly those judgements are pretty much 100% subjective, based on my sense of how the sentences flowed into each other (though ofc the replacement of the comma itself is not subjective or opinion-based).
I know this is silly and finicky, but I hope it helps tidy up the docs a bit for future readers!
This is very much non-urgent (and, honestly, non-important). I just figured it might be a nice quality-of-life improvement and bit of tidying up for the core contributors themselves not to have to do. 🙂
I'm tagging Steve, per the contributing guidelines ("Steve usually reviews documentation changes. So if you were to make a documentation change, add r? @steveklabnik"):
r? @steveklabnik