Naturally, one does not want to block the main UI thread and obstruct the user workflow while doing some lenghty operations. Lengthy operations are
are quite ubiquitous in development environments and as a matter of fact a lot of processing has to be done in background with or without user awareness
in order to bring the best experience. As Vim did not really have native support for asynchronous processing (only recently some async support has been added?),
a custom solution had to been brought in.
Therefore, to ease the development and integration of any kind of lengthy operations this framework has been developed. In the context of this framework
lenghty operations are encapsulated in units called services. Each service:
- Has its own unique ID
- Is dispatched to its own background process
- Can be started and shut down on request
- Can be triggered at any moment during its runtime
- Can notify the main thread about its events and queue the actions to be executed on the UI side
To make the communication between the UI and background services seamless, YavideServer on the server side and Y_Server...() API
on the client side is taking care of that. YavideServer is a thin proxy layer which controls and handles all the services.
Important aspect of this framework is that it provides a generic service development platform and enables service developer to fully focus on the
implementation details of particular service. See existing services to see an example how implementation may look like.
Each service can be enabled or disabled via enabled property found in <yavide_install_dir>/core/.globals.vimrc.
Restart is needed to take the change into effect.
I.e. To disable auto-formatting via clang-format:
let g:project_service_src_code_formatter = { 'id' : 2, 'enabled' : 0, 'started' : 0, 'start' : function("Y_SrcCodeFormatter_Start"), 'stop' : function("Y_SrcCodeFormatter_Stop") }
As most services are utilizing Clang front-end (libclang) for its implementation, to get the best (and most satisfying) results proper configuration has to be done.
I.e. Services must have access to all of the compiler flags that your project is actually used with while running the build. To provide this configuration one should
provide either of the following in the root of the project directory:
- JSON Compilation Database,
compile_flags.txtwhich contains all the compiler flags relevant for your project (one compiler flag per line). I.e.
-I./lib
-I./include
-DFEATURE_XX
-DFEATURE_YY
-Wall
-Werror
If there is none of the configuration files provided, a fallback solution will be used but the functionality will be very limited.
Initially, ctags + cscope combination has been used to implement indexing capabilities. Even though this approach has worked more or less quite well with C code, it hasn't
played very well with C++ code (it has much more complex grammar), and even more so with the modern instances of C++ (11, 14, 17, ...). Home-grown C++ parsers do not have tendency
to be up-to-date with the most recent C++ standards whereas it is natural for complying compiler frontends to be up-to-date by default.
For aforementioned reasons, indexer functionality has been replaced with clang-based approach which gives us, now very obvious, advantages of full understanding of the source code semantics.
Having a properly implemented & semanticly-aware indexer is crucial because it benefits the implementation of other services as well because of its capability to complement
other services with the details which they cannot naturally come up with (i.e. how does one jump to the definition of a forwared-declared symbol).
It must be noted that it is crucial for configuration step to be done in order to get this service running properly. This is also true for other services.
For imported projects, indexing will be automatically run at the start-up but one can also trigger indexing operation manually (see usage docs). Depending on the size of the code base, indexing may take some time until completely finished. However, it is optimized to run concurrently across all of the available CPU cores (threads).
Until the completion of indexing operation, some services will be temporarily disabled because they directly depend on the gathered information.
Upon completion, notification will be emitted to the Vim status bar.
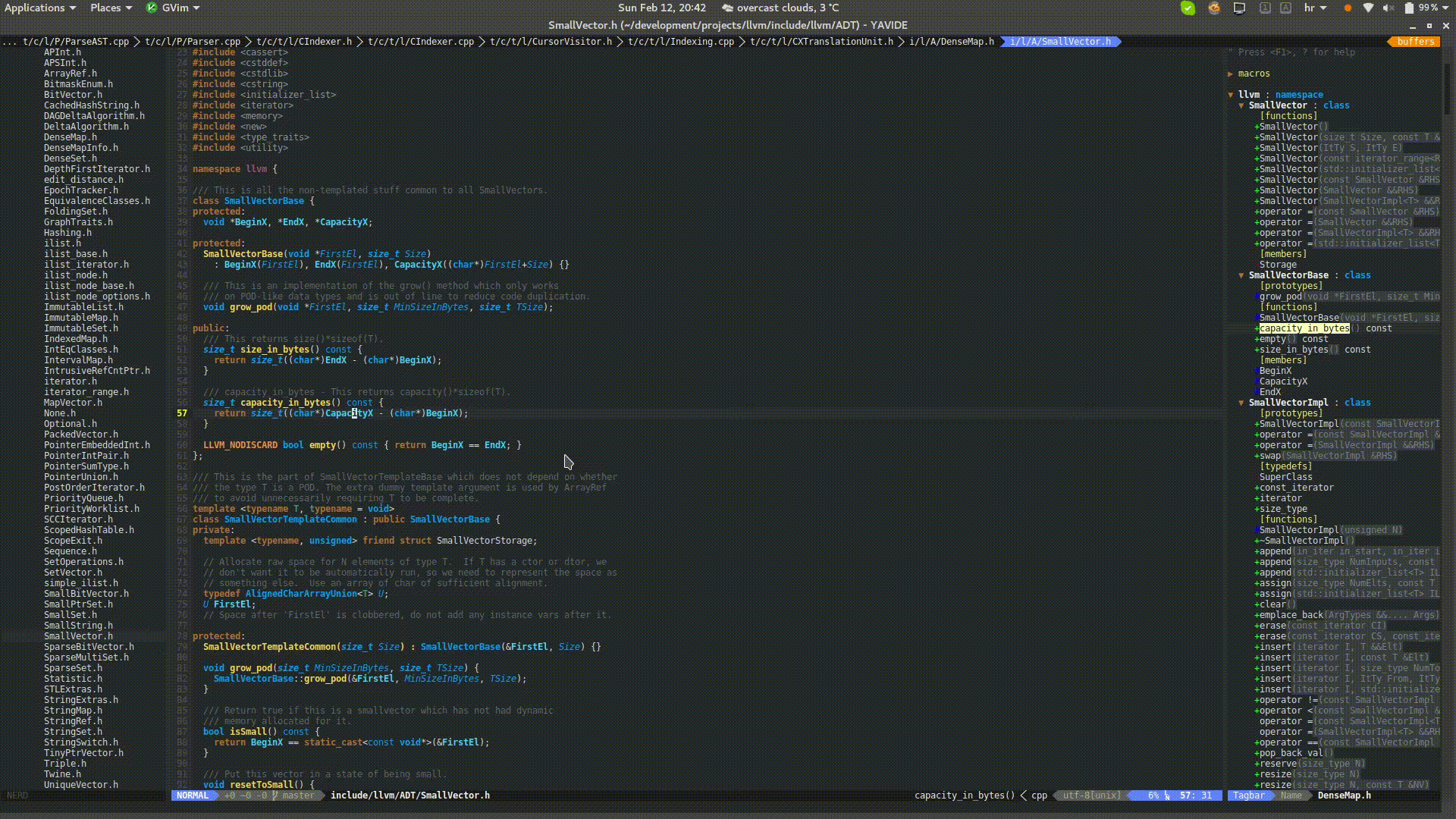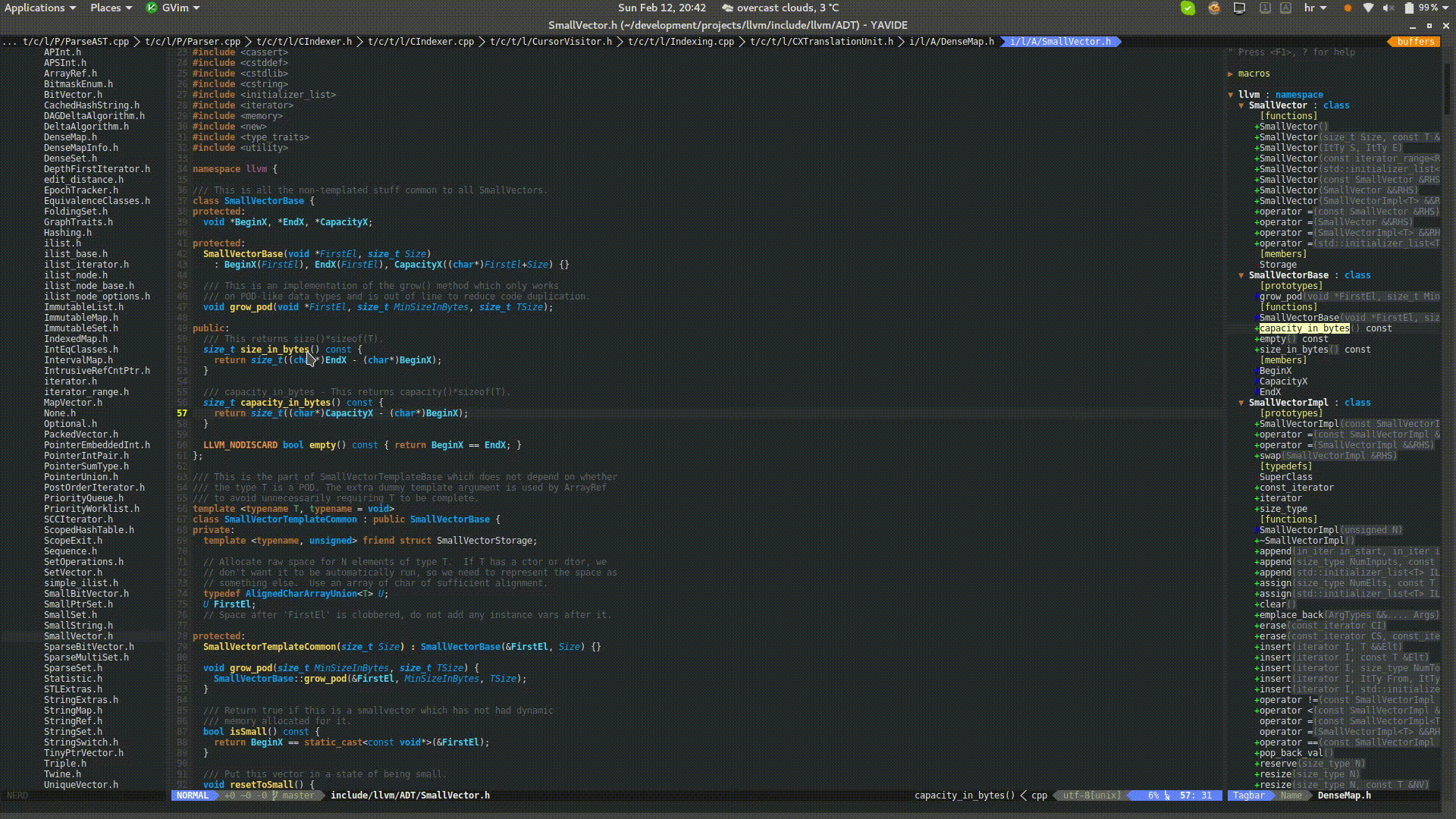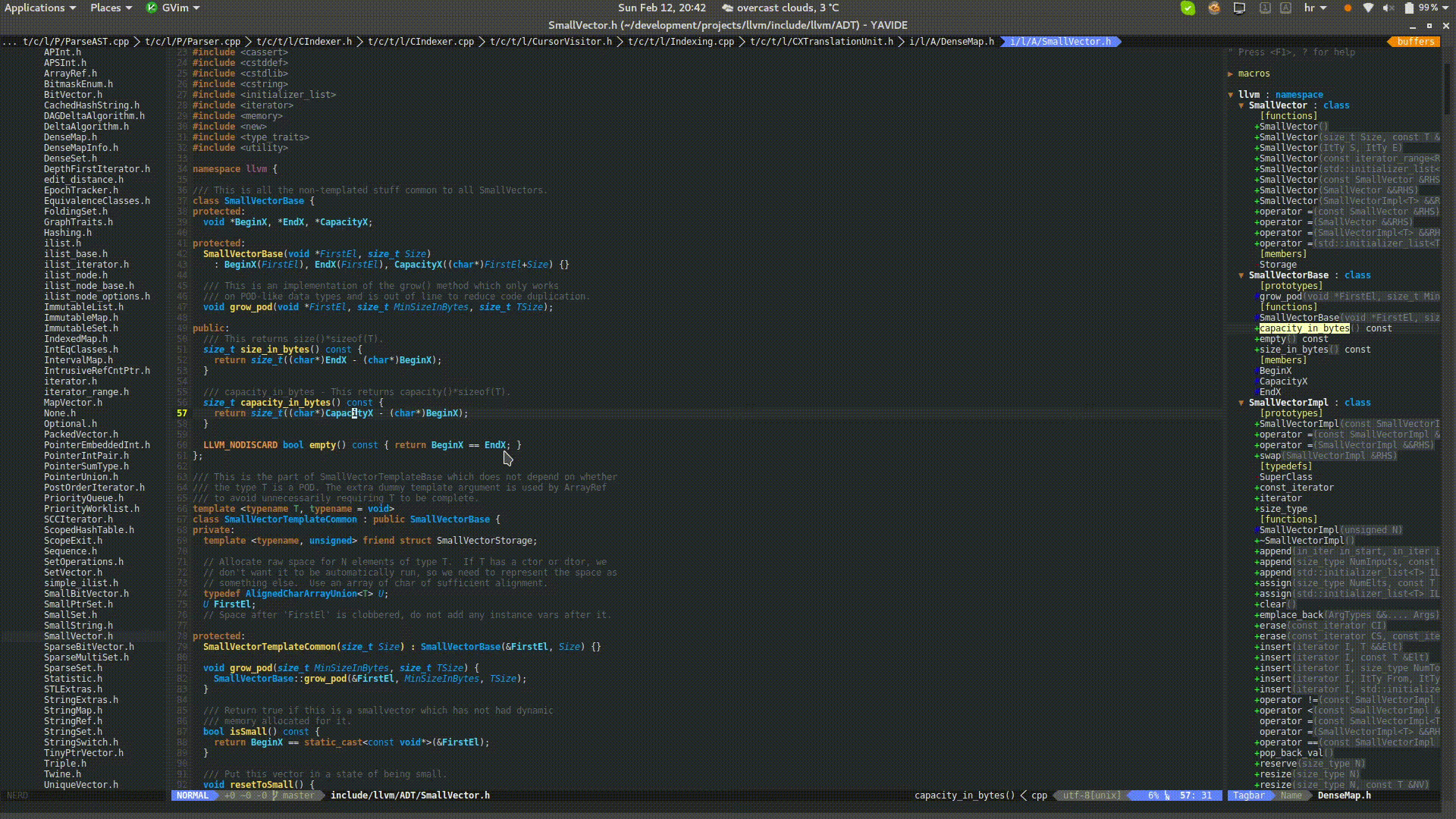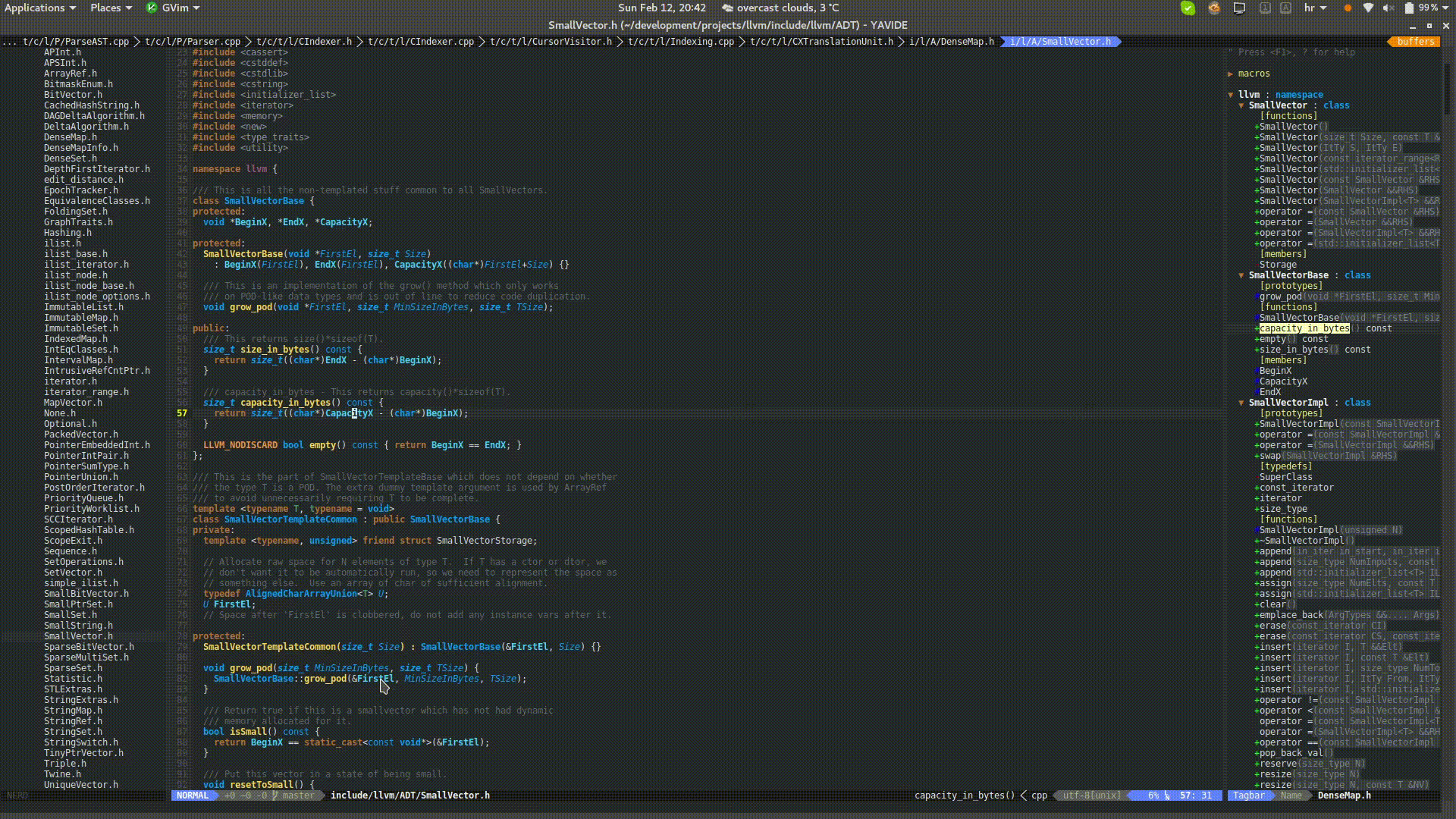
One is able to issue a query that will find all occurences of (almost) any kind of symbol throughout the whole code base (project).
Integration with Vim is done via quickfix window.
One can jump to the definition of any symbol across different translation units (it works even for forward-declared symbols).
One can open any header file included via #include directive(s). This feature is NOT based on custom-made heuristics to guess
the file under the cursor (i.e. by traversing the (sub)-directories) but it is actually built on top of clang to find out the
proper and 100% correct file.
Putting a mouse cursor over source code will provide details about the underlying constructs. Vim integration is achieved with balloon expressions.
Clang is known for its expressive diagnostics and fix-it hints that it can provide as a feedback without going to the compilation stage.
This feature is now made available and integrated into the Vim location-list which will be holding such information for each window you have opened. In order to get location-list one shall use standard Vim commands to manipulate with it (i.e. :lopen to open location list for current window you are at).
If you find it too intrusive or redundant you can always turn it off. See enabling/disabling services.

Compared to the Vim syntax highlighting mechanism, this service brings a semantic syntax highlighting. That basically means that
colorschemes now have access to the source code model and therefore can enrichen the experience.
| Before | After |
|---|---|
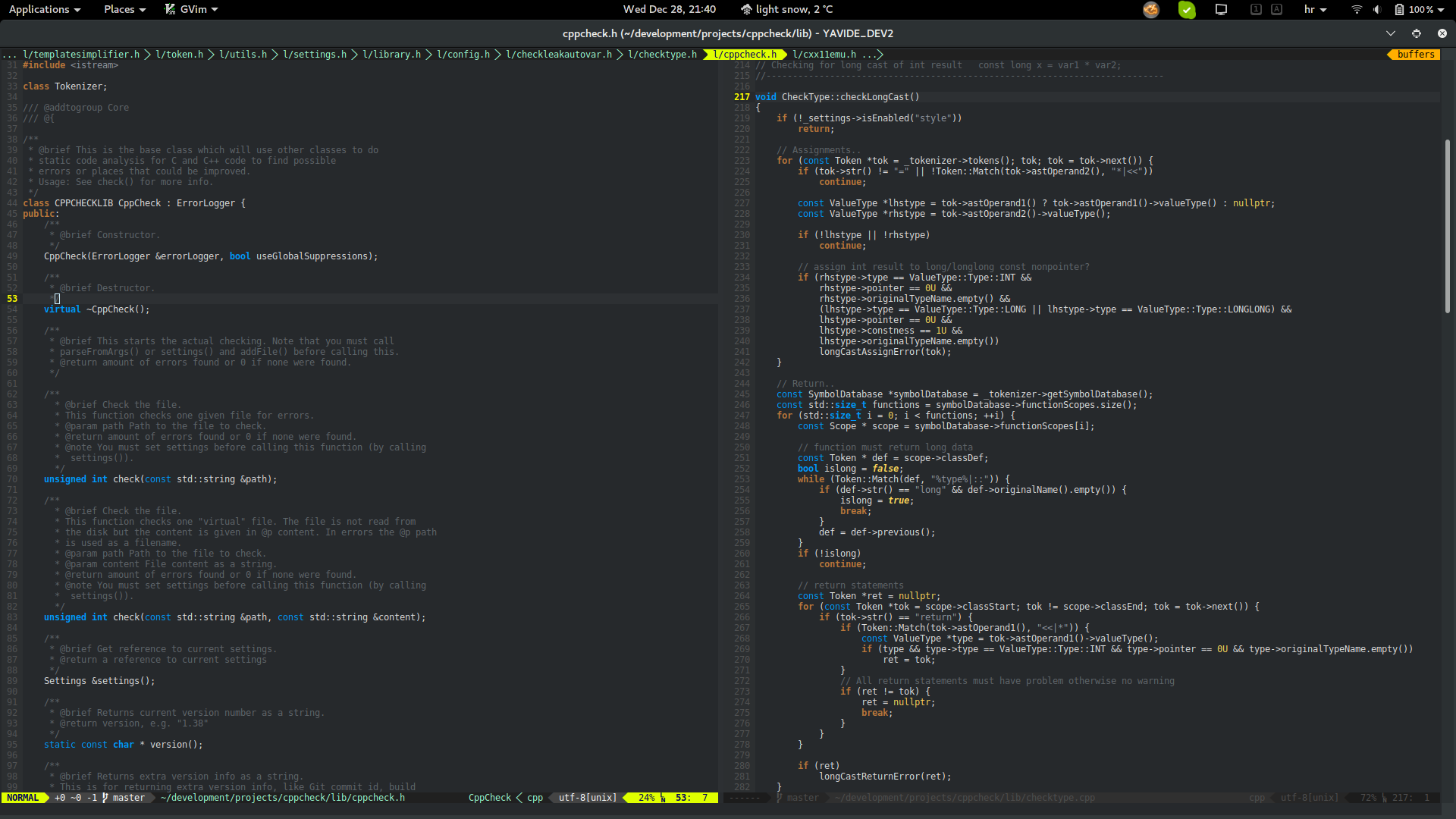 |
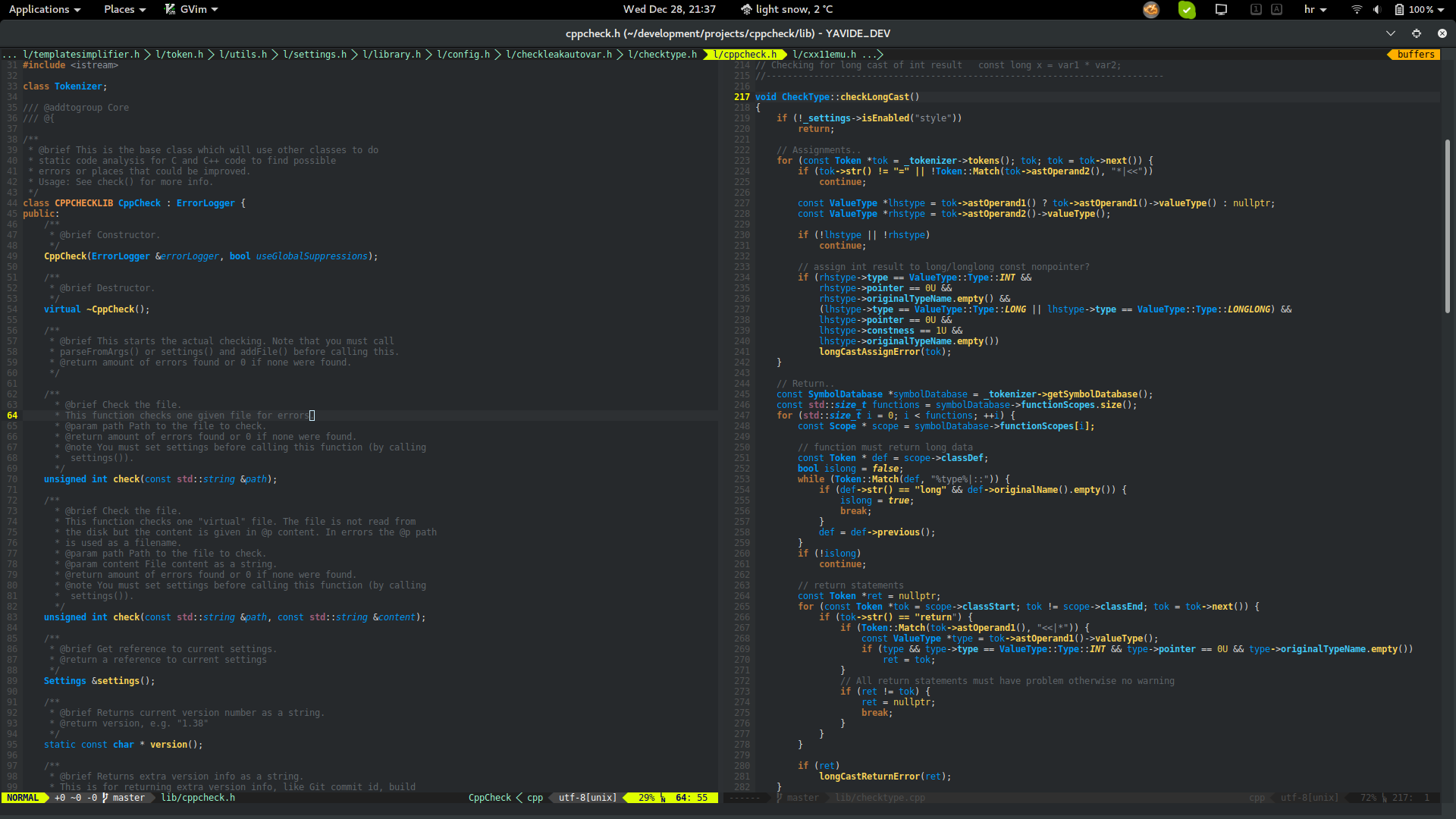 |
Not only that it attributes to the visual appeal but it also does something much more important:
- it provides an immediate feedback on correctness of your code
In other words, source code will not get properly colored if there are any syntax errors in your code. This may have a positive side-effect of shortening the development cycle.
As mentioned, one has to use a colorscheme which can take advantage of this level of detail. One such colorscheme
is yaflandia which I have made for this very purpose. Other colorschemes out
there are not designed in such a way and, to make them play well with semantic syntax highlighting, must be tweaked to include these additional highlight groups.
If you don't see what you expected, then there are certainly some errors (semantic, parsing, ...) for which you can get a hint if you have look at the corresponding location-list window (i.e. use :lopen).
You need to have Diagnostic service enabled.
For bigger files, scrolling will become really really slow if cursorline variable is set (in my env set by default). This is a very old and very annoying Vim issue which is even mentioned in vim-help.
See :help 'cursorline' for more details.
For bigger files one might set nocursorline (it can be even scripted) or turn it off permanently by putting it in .editor.vimrc file.
However, not always this will be enough. See next section.
Vim crawls down because there are thousands of syntax rules being applied to the buffer, and I suspect that by each scroll event these are being reapplied. On a N-thousand lines of code big file applying such a large number of syntax rules will cause rendering issues. To circumvent this issue, either Vim needs to be patched or we have to solve this issue by our own within the framework by introducing a new syntax applying strategy.
A new strategy wouldn't apply all the syntax rules which have been generated for the given file but it would apply syntax rules only for the visible parts (±N lines) of a buffer. This will hopefully fix the issue but for this to be a complete working solution we have to be able to catch all the buffer scrolling events. This is unfortunatelly not exposed by Vim in a seamless way so we will have to apply some workarounds which will make this happen (very soon I hope).
Create .clang-format configuration file in the project root directory. Upon each modification which has been saved, code will be automatically formatted.
If there is no configuration file provided, there will be no effect and service is basically disabled.

Clang-Tidy is a Clang-based static analysis tool and one can run it on
per-file basis within the Yavide environment. For tool to be run one must have a properly configured .clang-tidy
at the root of the project directory. Integration which allows a full run on the whole project is yet to be implemented.
In case of any issues found by the tool, tool can also apply the fixes automatically for you. One can run the tool in either mode (discover-issues-only or discover-and-apply-fixes).
For more thorough explanation see official documentation but in general JSON compilation databases offer a semi-automated way of providing project-specific compiler flags which are then used to feed the Clang-based services with enough details about the include paths, defines, etc. and enables them to properly parse the code and give the correct parsing results.
In order to generate the JSON compilation database for your project, your build system has to provide support for them. CMake/Ninja are for example ones that provide support for generation of JSON compilation databases and for the given project one can be generated simply by running the following command:
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=ON <path_to_your_source_root_dir>
However, for the best experience I would advise to automate this step by integrating it into the build itself. I.e. include set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
in your CMakeList.txt. This approach will make sure that compilation database is always up-to-date and no manual re-runs will be needed.
For build systems which do not provide direct support for compilation databases one can look at the Bear which helps to achieve the same by basically intercepting the system calls and stealing the compiler flags from it. This obviously requires a user to run the full build before getting the compilation database which in the CMake/Ninja case is not required. For that matter there were numerous tools developed which try to workaround this issue in various ways.
If it proves hard to get the compilation database generated for your project you can always fall-back on a manual way of providing this configuration via a textual file as explained in Configuration section.
Set g:project_env_build_command to the build command specific to the project. I.e. after loading/importing the project do the following:
let g:project_env_build_command='make all'
Once this variable has been successfully set, one is able to use YavideBuildRun command or F7 to trigger the build.
Upon completion quickfix window will be populated with build output where in case of any warnings/errors one is able
to jump to the given warning/error double-clicking/pressing-enter-key on the particular entry from the list. Once the project has
been saved build command will be persisted in project settings and therefore re-loaded on the next project start-up.
Current progress of the build cannot be tracked directly from Yavide but one can use tail -f /tmp/yavide<random_string>build from the terminal.
Possibility to stream the build directly on-the-fly to the Yavide environment (i.e. quickfix window) needs to be evaluated and will be considered.
