The main goal of the Cassandra Neo4j data import tool is to provide a direct way to map a Cassandra schema to Neo4j and import result sets that come from Cassandra columns to Neo4j property graph model, generating a meaningful representation of nodes and relationships. This translation is specified by populating a YAML file based on the Cassandra schema to specify how the data should be mapped from a column-oriented data model to a property graph. The tool exports data from Cassandra using the Cassandra Python driver into CSV format as an intermediate step. LOAD CSV cypher statements are then generated based on the data model mapping specified for loading the data into Neo4j. The following sections will guide you through this process and also provide some mapping examples.
At this point, only Python 3.x is supported
-
Clone this GitHub repository:
git clone https://github.com/neo4j-contrib/neo4j-cassandra-connector.git -
Install project dependencies:
pip install -r requirements.txt
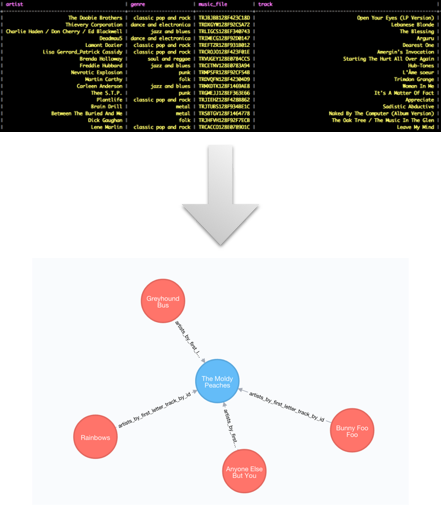
We will use a sample database of musicians and songs:
-
A sample database is included that works with this example. Simply go to
db_gendirectory, start Cassandra shellcqlshand invoke the commandSOURCE '/playlist.cql'. You can also provide the absolute path of the file. This will populate your Cassandra database with a sample Tracks and Artists database.
After populating your initial database, you must generate a file to properly map a Cassandra Schema to a graph. Do the following:
-
Into the project directory, navigate to the subfolder connector/
-
Run the script
connector.py. Invoke it withpython connector.py parse -k playlist. -
Some output files will be generated. At this stage, take a look into the generated
schema.yamlfile. It contains a YAML representation of the Cassandra schema with placeholders for specifying how to convert this Cassandra schema into a Neo4j property graph data model.
The next step consists of populating the placeholders in this file with mapping information. Check out the next section for more information.
In order to import data into Neo4j the mapping from Cassandra schema to Neo4j property graph must be specified. This is done by populating the placeholders in the generated schema.yaml file.
schema.yaml file for the sample database:
CREATE TABLE playlist.artists_by_first_letter:
first_letter text: {}
artist text: {}
PRIMARY KEY (first_letter {}, artist {})
CREATE TABLE playlist.track_by_id:
track_id uuid PRIMARY KEY: {}
artist text: {}
genre text: {}
music_file text: {}
track text: {}
track_length_in_seconds int: {}
NEO4J CREDENTIALS (url {}, user {}, password {})-
Every table will be translated as a Node in Neo4j.
-
The keyspace from Cassandra will be translated as a label for every generated node in Neo4j.
Note the {}. It’s possible to fill them up with the following options:
-
p, for regular node property (fill with {p}),
-
r for relationship (fill with {r}),
-
u for unique constraint field (fill with {u})
-
i to create an index on this property (fill with {i})
For example:
CREATE TABLE playlist.artists_by_first_letter:
first_letter text: {p}
artist text: {r}
PRIMARY KEY (first_letter {p}, artist {u})
CREATE TABLE playlist.track_by_id:
track_id uuid PRIMARY KEY: {u}
artist text: {r}
genre text: {p}
music_file text: {p}
track text: {p}
track_length_in_seconds int: {p}This will create a propery graph with nodes for the artists and tracks, with a relationship connecting the artist to the track.
There’s also one last line at the end of the file, that requires Neo4j address and credentials:
NEO4J CREDENTIALS (url {"http://localhost:7474/db/data"}, user {"neo4j"}, password {"neo4jpasswd"})If you have turned off authentication, you can leave user and password fields empty:
NEO4J CREDENTIALS (url {"http://localhost:7474/db/data"}, user {}, password {})An example of filled YAML file can be found on connector/schema.yaml.example.
For this first version, we do not have a strong error handling. So please be aware of the following aspects:
-
If you populate a field as a relationship between two nodes, please map the field with r in both table. In the example above, note that artist is mapped as r in both tables, playlist.track_by_artist and playlist.track_by_id. In this initial version keys must have the same name to indicate a relationship.
-
Regarding unique constraints: be sure that you will not have more than one node with the property that you selected for creating this constraint. u is going to work only for lines that have been marked with PRIMARY KEY. For example:
PRIMARY KEY (first_letter {p}, artist {u})This example denotes that artist is selected to be a constraint. We cannot have more than one node with the same artist. -
To avoid performance issues, try to promote fields to constraints if you notice that it would reduce the number of reduced nodes (of course considering the meaningfulness of the modelling).
After populating the empty brackets, save the file and run the script connector.py, now specifying the tables you wish to export from Cassandra:
python connector.py export -k playlist -t track_by_id,artists_by_first_letterThe schema YAML file name (if different than schema.yaml) can also be specifed as a command line argument. For example:
python connector.py export -k playlist -t track_by_id,artists_by_first_letter -f my_schema_file.yaml
The YAML file will be parsed into Cypher queries. A file called cypher_ will be generated in your directory. It contains the Cypher queries that will generate Nodes and Relationship into a graph structure. After generated, the queries are automatically executed by Py2Neo using the Neo4j connection parameters specified in schema.yaml.
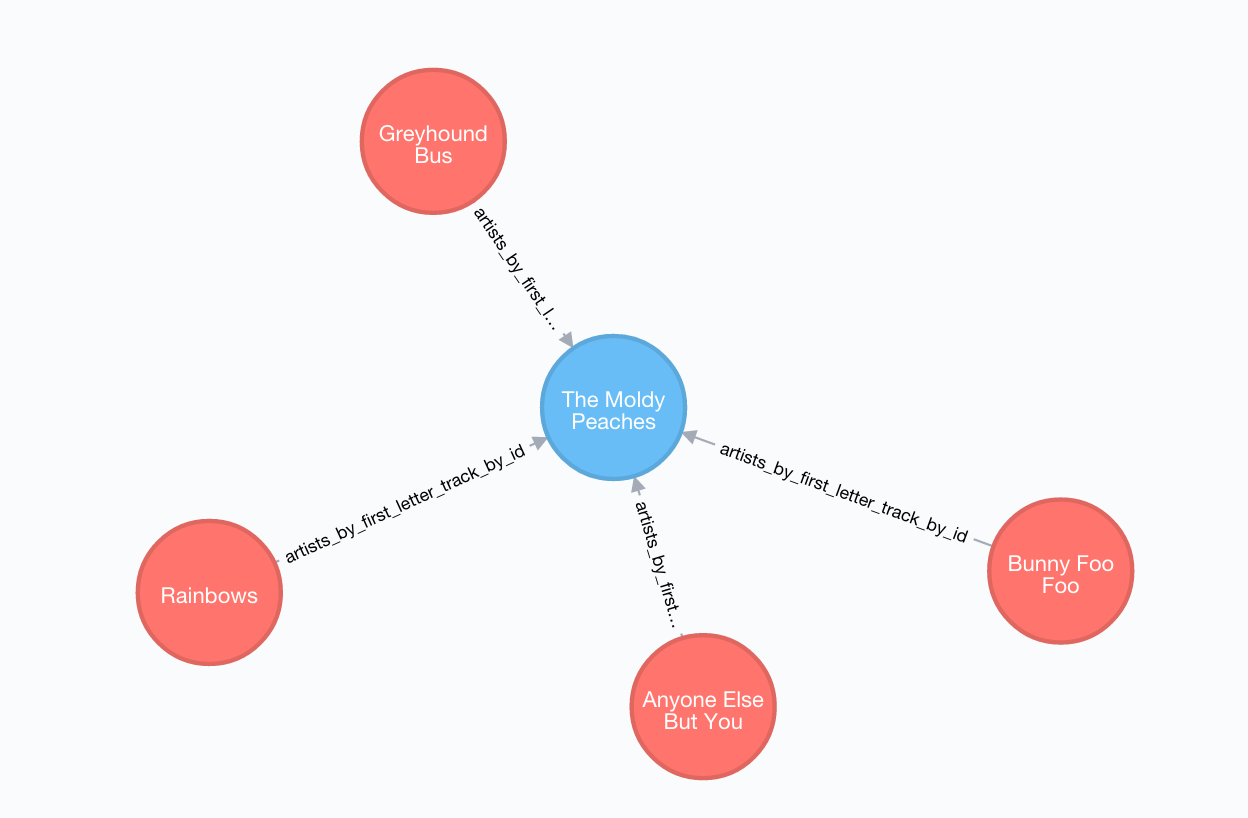
Using the sample Artists and Tracks dataset, we have Track nodes and Artist nodes, connected by artist fields. We also wanted to make a constraint on artist by its name - we could not have two different nodes with similar artist names.
Another example of information that we could store into Cassandra and have a corresponding mapping into Neo4j would be a Fraud Detection System. For example, we could have a Schema similar to:
CREATE TABLE detection.bank_by_holder:
user text: {}
bank text: {}
bank_id: {}
last_transaction datetime: {}
PRIMARY KEY (bank {i})
CREATE TABLE detection.address_by_holder:
user text: {}
address text: {}
last_update datetime: {}
PRIMARY KEY (bank {})
CREATE TABLE detection.credit_card_by_holder:
user text: {}
identifier text: {}
last_update datetime: {}
expire_date datetime: {}
PRIMARY KEY (bank {})
CREATE TABLE detection.holder:
username text PRIMARY KEY: {}
password text: {}
ssn text: {}
PRIMARY KEY (bank {})Fraud detection has been a nice use case for graphs. Check this reference.
The Neo4j Cassandra data import tool is in its infancy and currently has many limitations. It is currently a simple prototype meant to support a limited data model. We’d appreciate any feedback you might have, please raise an issue on the GitHub project.
We are aware that this first version is very tight to a single example. We plan to expand this connector to more general cases, improve mappings, add tricks and smart YAML files that can infer some patterns into Cassandra Schema and suggest an initial translate to Neo4j.
We also plan to add more flexibility to Neo4j mapping and avoid performance issues. We are aware that declaring all fields might be a little inconvenient too, so we plan to automate this process in order to make it less verbose.
Another further work consists of organising better directories for the generated files and add Travis CI support, together with a better integration tests suite.