---?image=assets/TitleCard.png&size=contain
gitpitch.com/potatosalad/elixirconf2017
![]()
+++

Native Implemented Functions (NIFs)
still experimental but very useful.Feedback is welcome.
![]()
+++
| Type | Isolation | Latency* |
|---|---|---|
Node |
Network |
~100μs |
Port |
Process |
~100μs |
Port Driver |
Shared |
~10μs |
NIF |
Shared |
~0.1μs |
*Rounded to nearest order of magnitude.
potatosalad.io/2017/08/05/latency-of-native-functions-for-erlang-and-elixir
+++
A well-behaving native function is to return to its caller within 1 millisecond.
![]()
+++
void
spin(ErlNifSInt64 count)
{
for (; count > 0; --count) {}
}+++
ErlNifSInt64
spinsleep(ErlNifSInt64 microseconds)
{
ErlNifTime start, current, stop;
ErlNifSInt64 count;
start = enif_monotonic_time(ERL_NIF_NSEC);
stop = start + ((ErlNifTime)microseconds * 1000);
do {
current = enif_monotonic_time(ERL_NIF_NSEC);
count = (stop - current) / 2;
(void)spin(count);
} while (stop > current);
return ((current - start) / 1000);
}keeps CPU busy for given μs stop time = start time + given μs loop until stop time reached
+++
def spinsleep(microseconds, multiplier) do
function = fn () ->
:my_nif.spinsleep(microseconds)
end
count = :erlang.system_info(:schedulers_online) * multipler
spawn_multiple(function, count)
endbusy sleep for given μs spawns this many processes
+++

+++

+++

+++

- Variable input/output
binarylistmaptuple
- CPU blocking
- I/O blocking
- Dirty NIF
- Yielding NIF (timeslice)
- Yielding Dirty NIF
- Threaded NIF
A NIF that cannot be split and cannot execute in a millisecond or less.
![]()
+++
{"spinsleep", 1, spinsleep},
{"spinsleep_dirty", 1, spinsleep, ERL_NIF_DIRTY_JOB_CPU_BOUND},normal NIF dirty NIF
+++

+++

+++

+++
This approach is always preferred over the other alternatives.
![]()
+++
+++
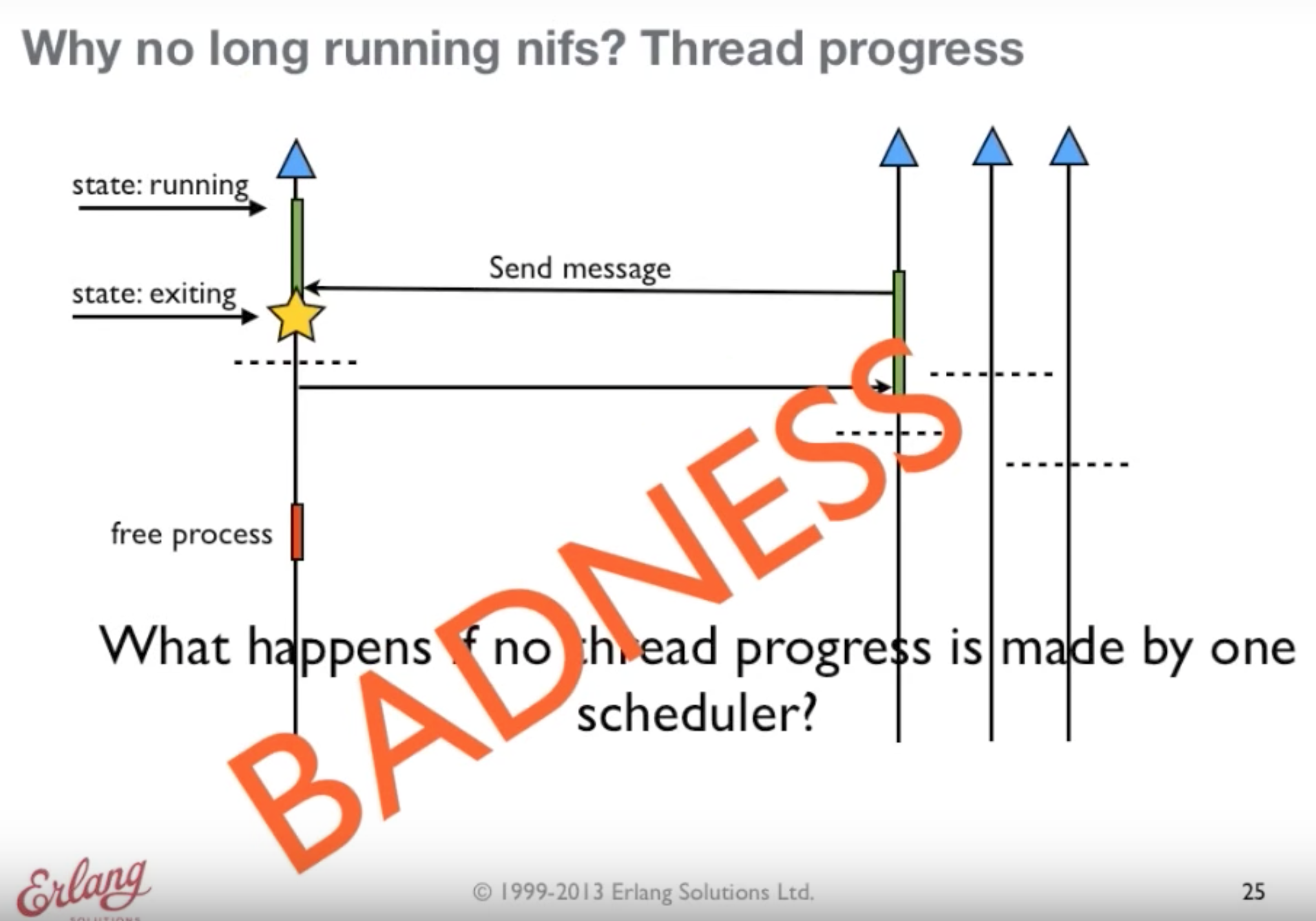
The scheduler is responsible for the [soft] real-time guarantees of the system.
+++
One can describe the scheduling in BEAM as preemptive scheduling on top of cooperative scheduling.
+++
- Elixir functions are preemptive
- C functions are cooperative…hopefully
+++
+++
A process can only be suspended at certain points of the execution, such as at a receive or a function call.
+++
When a process is scheduled it will get a number of reductions defined by
CONTEXT_REDS(currently 4000).
+++
It is not completely defined what a reduction is, but at least each function call should be counted as a reduction.
+++
def echo(term) do
term
end+++
self = :erlang.self()
{:reductions, r1} = :erlang.process_info(self, :reductions)
:ok = echo(:ok)
{:reductions, r2} = :erlang.process_info(self, :reductions)
rdiff = r2 - r1 # ~400+++
def collect(_ref, 0, replies) do
replies
end
def collect(ref, n, replies) do
receive do
{^ref, reply} ->
collect(ref, n - 1, [reply | replies])
end
endsuspend caller of collect/3
suspend on receive
suspend on call to collect/3
at least 3 preemption points
+++
parent = self()
ref = make_ref()
:ok =
Enum.reduce(1..1000, :ok, fn (_, ok) ->
_ = spawn(:erlang, :send, [parent, {ref, 1}])
ok
end)
{:reductions, r1} = :erlang.process_info(parent, :reductions)
replies = collect(ref, 1000, [])
{:reductions, r2} = :erlang.process_info(parent, :reductions)
1000 = Enum.sum(replies)
rdiff = r2 - r1 # ~1400+++
+++
There is a risk that a function implemented in C takes many more clock cycles per reduction than a normal Erlang function.
+++
nif_bif_result = (*fp)(&env, bif_nif_arity, reg);erts/emulator/beam/bif_instrs.tab
blocks thread until the NIF returns
+++
static ERL_NIF_TERM
echo(ErlNifEnv *env, int argc, const ERL_NIF_TERM argv[])
{
return argv[0];
}+++
self = :erlang.self()
{:reductions, r1} = :erlang.process_info(self, :reductions)
:ok = :my_nif.echo(:ok)
{:reductions, r2} = :erlang.process_info(self, :reductions)
rdiff = r2 - r1 # ~200+++
static ERL_NIF_TERM
echo(ErlNifEnv *env, int argc, const ERL_NIF_TERM argv[])
{
(void) spinsleep(1000 * 1000); // spin for 1 second
return argv[0];
}reductions = ~200
+++
+++
static ERL_NIF_TERM
echo(ErlNifEnv *env, int argc, const ERL_NIF_TERM argv[])
{
(void) enif_consume_timeslice(env, 100);
return argv[0];
}reductions = ~4200
+++
if (microseconds > 1000) {
ERL_NIF_TERM newargv[1];
newargv[0] = enif_make_int64(env, (ErlNifSInt64) start);
newargv[1] = enif_make_int64(env, (ErlNifSInt64) stop);
newargv[2] = enif_make_int64(env, 1000 * 1000);
return enif_schedule_nif(env, "spinsleep_timeslice", 0,
spinsleep_ts, 3, newargv);
}max_per_slice
+++
static ERL_NIF_TERM
spinsleep_ts(ErlNifEnv *env, int argc, const ERL_NIF_TERM argv[])
{
ErlNifTime start, stop, current;
ErlNifSInt64 max_per_slice, offset = 0;
int percent, total = 0;
if (argc != 3
|| !enif_get_int64(env, argv[0], &start)
|| !enif_get_int64(env, argv[1], &stop)
|| !enif_get_int64(env, argv[2], &max_per_slice)) {
return enif_make_badarg(env);
}
// ...
}+++
current = enif_monotonic_time(ERL_NIF_NSEC);
while (stop > current) {
(void)spin(max_per_slice);
offset += max_per_slice;
diff = enif_monotonic_time(ERL_NIF_NSEC) - current;
current += diff;
percent = (int)(diff / 1000 / 1000);
total += percent;
if (enif_consume_timeslice(env, percent)) {
// ...
}
}
return enif_make_int64(env, (current - start) / 1000);+++
max_per_slice = offset;
if (total > 100) {
int m = (int)(total / 100);
if (m == 1) {
max_per_slice -= (max_per_slice * (total - 100) / 100);
} else {
max_per_slice = (max_per_slice / m);
}
}
ERL_NIF_TERM newargv[1];
newargv[0] = argv[0]; // start
newargv[1] = argv[1]; // stop
newargv[2] = enif_make_int64(env, max_per_slice);
return enif_schedule_nif(env, "spinsleep_timeslice", 0,
spinsleep_ts, 3, newargv);+++

+++

+++
+++

+++

+++
This isn't really mentioned in the documentation.
— Me
![]()
+++
return enif_schedule_nif(env, "spinsleep_timeslice_dirty",
ERL_NIF_DIRTY_JOB_CPU_BOUND,
spinsleep_tsd, 3, newargv);+++

+++

+++

+++

+++

+++

---?image=assets/idle-summary.png&size=contain
+++
|
1x |
10x |
100x |
1000x |
10000x |
| Normal | +1s |
+15s |
|||
| Dirty | +1s |
+10s |
|||
| Yielding | |||||
| Yielding Dirty |
+++
|
1x |
10x |
100x |
1000x |
10000x |
| Normal | +1s |
+10s |
+2m |
||
| Dirty | +1s |
+10s |
+2m |
||
| Yielding | |||||
| Yielding Dirty |
+++
|
1x |
10x |
100x |
1000x |
10000x |
| Normal | +1s |
+15s |
+30s |
+2m |
+16m |
| Dirty | +15s |
+30s |
+2m |
+16m |
|
| Yielding | |||||
| Yielding Dirty |
+++
|
1x |
10x |
100x |
1000x |
10000x |
| Yielding | +1s |
+1s |
+2s |
+3s |
|
| Yielding Dirty |
+++
|
1x |
10x |
100x |
1000x |
10000x |
| Yielding | +1s |
+2s |
+5s |
+10s |
+15s |
| Yielding Dirty |
+++
|
1x |
10x |
100x |
1000x |
10000x |
| Yielding Dirty |
| Duration | NIF Type |
|---|---|
< 1ms |
Normal |
< 100ms |
Yielding |
≥ 100ms |
Yielding Dirty |

---?image=assets/h2-load.png&size=contain
+++

+++

+++

+++

+++

+++

+++

+++

+++

+++

+++

+++

+++

+++

+++

+++

- NIF timeslice examples
- One dirty example:
crypto:rsa_generate_key_nif/2
- BIF timeslice examples
binary:match/2,3binary:matches/2,3binary:split/2,3
- More in [#1480](erlang/otp#1480)
- Magic references instead of magic binaries
enif_whereis_pidenif_monitor_processenif_select
- Example by Sverker Eriksson
- Uses
enif_select - NIF I/O Queue API: [#1364](erlang/otp#1364)
- Example by Sverker Eriksson
- Uses
enif_select

potatosalad.io/2017/08/20/load-testing-cowboy-2-0-0-rc-1
 potatosalad/elixirconf2017
potatosalad/elixirconf2017{kind=link}
{kind=link}