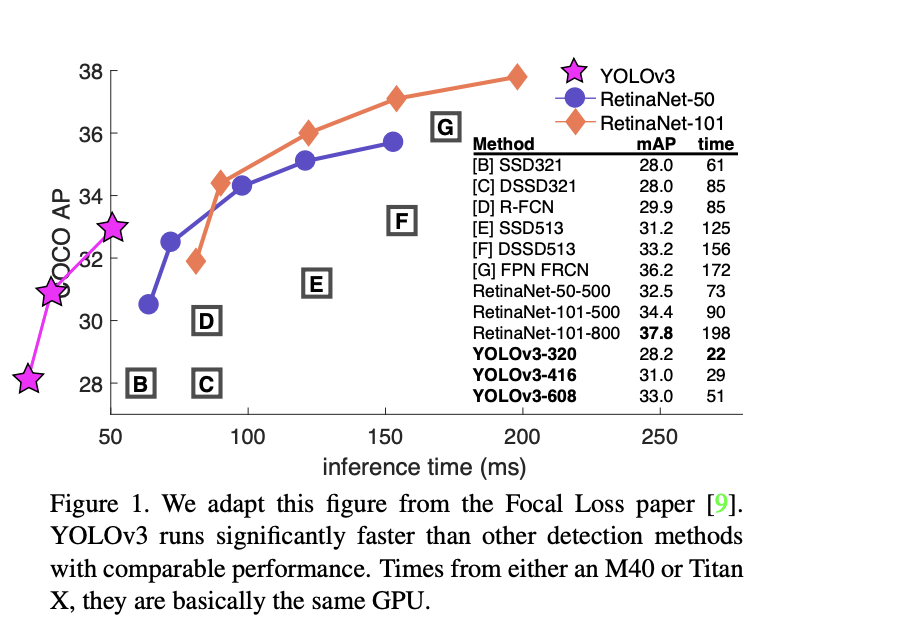
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that's pretty swell. It's a little bigger than last time but more accurate. It's still fast though, don't worry. At 320x320 YOLOv3 runs in 22 ms at 28.2 mAP, as accurate as SSD but three times faster. When we look at the old .5 IOU mAP detection metric YOLOv3 is quite good. It achieves 57.9 mAP@50 in 51 ms on a Titan X, compared to 57.5 mAP@50 in 198 ms by RetinaNet, similar performance but 3.8x faster.
| Name | Scale | Context | ImageSize | Dataset | Box mAP (%) | Params | FLOPs | Recipe | Download |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | Darknet53 | D910x8-G | 640 | MS COCO 2017 | 45.5 | 61.9M | 156.4G | yaml | weights |
- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Box mAP: Accuracy reported on the validation set.
- We referred to a commonly used third-party YOLOv3 implementation.
Please refer to the GETTING_STARTED in MindYOLO for details.
You can get the pre-training model from here.
To convert it to a loadable ckpt file for mindyolo, please put it in the root directory then run it
python mindyolo/utils/convert_weight_darknet53.pyIt is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config ./configs/yolov3/yolov3.yaml --device_target Ascend --is_parallel TrueIf the script is executed by the root user, the
--allow-run-as-rootparameter must be added tompirun.
Similarly, you can train the model on multiple GPU devices with the above mpirun command.
For detailed illustration of all hyper-parameters, please refer to config.py.
Note: As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
If you want to train or finetune the model on a smaller dataset without distributed training, please run:
# standalone training on a CPU/GPU/Ascend device
python train.py --config ./configs/yolov3/yolov3.yaml --device_target AscendTo validate the accuracy of the trained model, you can use test.py and parse the checkpoint path with --weight.
python test.py --config ./configs/yolov3/yolov3.yaml --device_target Ascend --weight /PATH/TO/WEIGHT.ckpt
See here.
[1] Jocher Glenn. YOLOv3 release v9.1. https://github.com/ultralytics/yolov3/releases/tag/v9.1, 2021. [2] Joseph Redmon and Ali Farhadi. YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.