| Author: | The Blosc development team |
|---|---|
| Contact: | [email protected] |
| Github: | https://github.com/Blosc/python-blosc2 |
| Actions: | |
| PyPi: |  |
| NumFOCUS: | |
| Code of Conduct: |
C-Blosc2 is the new major version of C-Blosc, and is backward compatible with both the C-Blosc1 API and its in-memory format. Python-Blosc2 is a Python package that wraps C-Blosc2, the newest version of the Blosc compressor.
Currently Python-Blosc2 already reproduces the API of Python-Blosc, so it can be used as a drop-in replacement. However, there are a few exceptions for a full compatibility.
In addition, Python-Blosc2 aims to leverage the new C-Blosc2 API so as to support super-chunks, multi-dimensional arrays (NDArray), serialization and other bells and whistles introduced in C-Blosc2. Although this is always and endless process, we have already catch up with most of the C-Blosc2 API capabilities.
Note: Python-Blosc2 is meant to be backward compatible with Python-Blosc data. That means that it can read data generated with Python-Blosc, but the opposite is not true (i.e. there is no forward compatibility).
SChunk is the simple data container that handles setting, expanding and getting data and metadata. Contrarily to chunks, a super-chunk can update and resize the data that it contains, supports user metadata, and it does not have the 2 GB storage limitation.
Additionally, you can convert a SChunk into a contiguous, serialized buffer (aka cframe) and vice-versa; as a bonus, the serialization/deserialization process also works with NumPy arrays and PyTorch/TensorFlow tensors at a blazing speed:
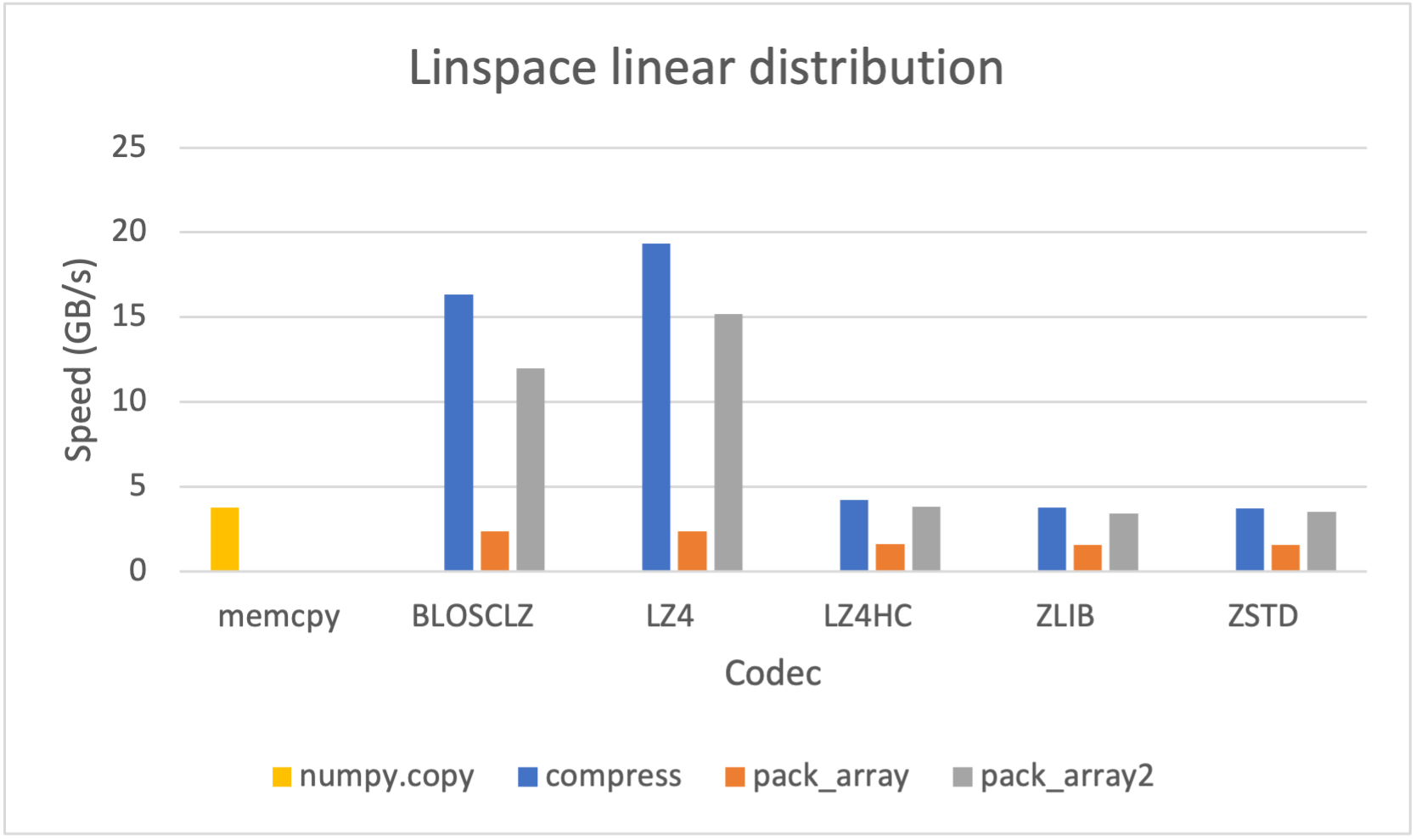 |
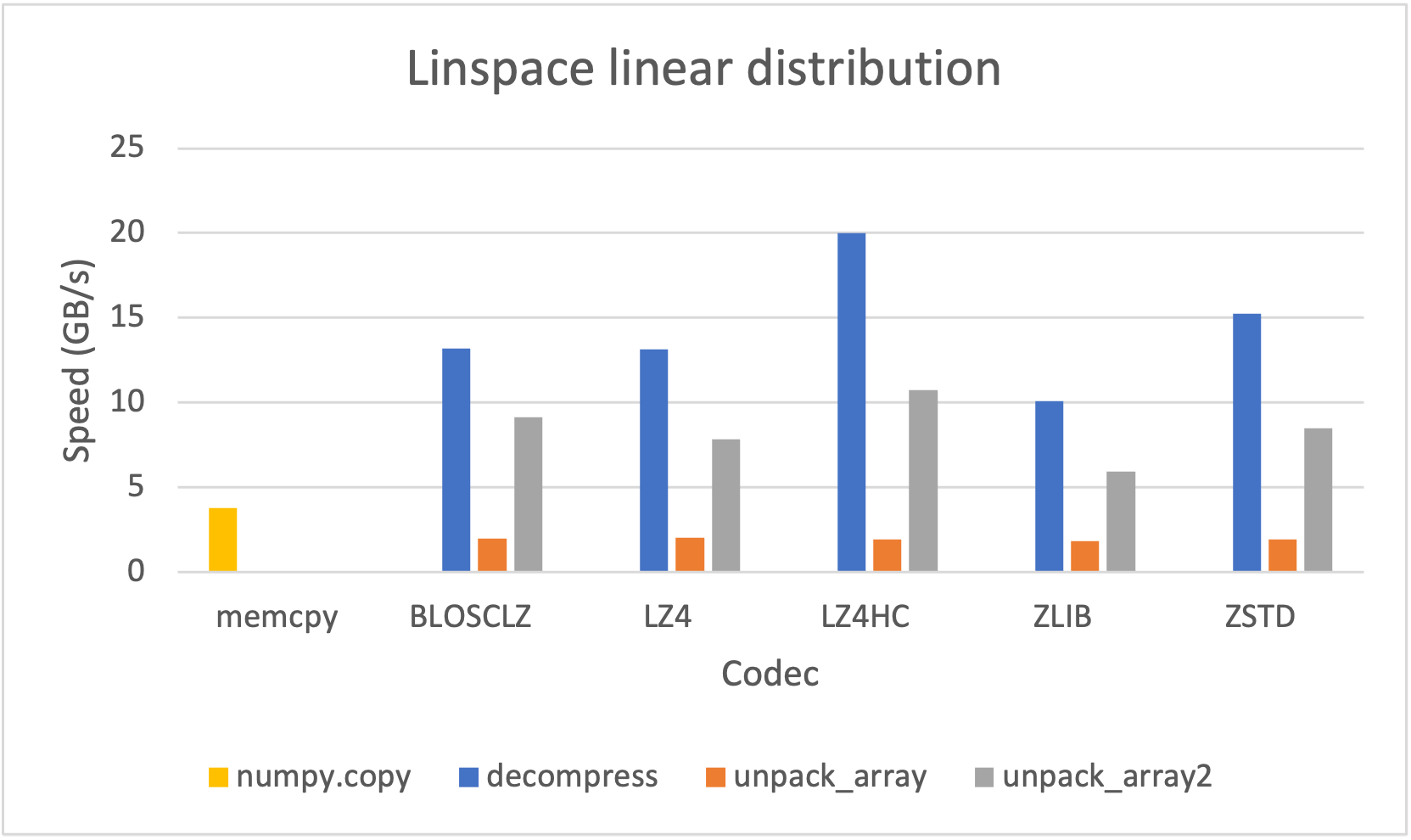 |
while reaching excellent compression ratios:

Also, if you are a Mac M1/M2 owner, make you a favor and use its native arm64 arch (yes, we are distributing Mac arm64 wheels too; you are welcome ;-):
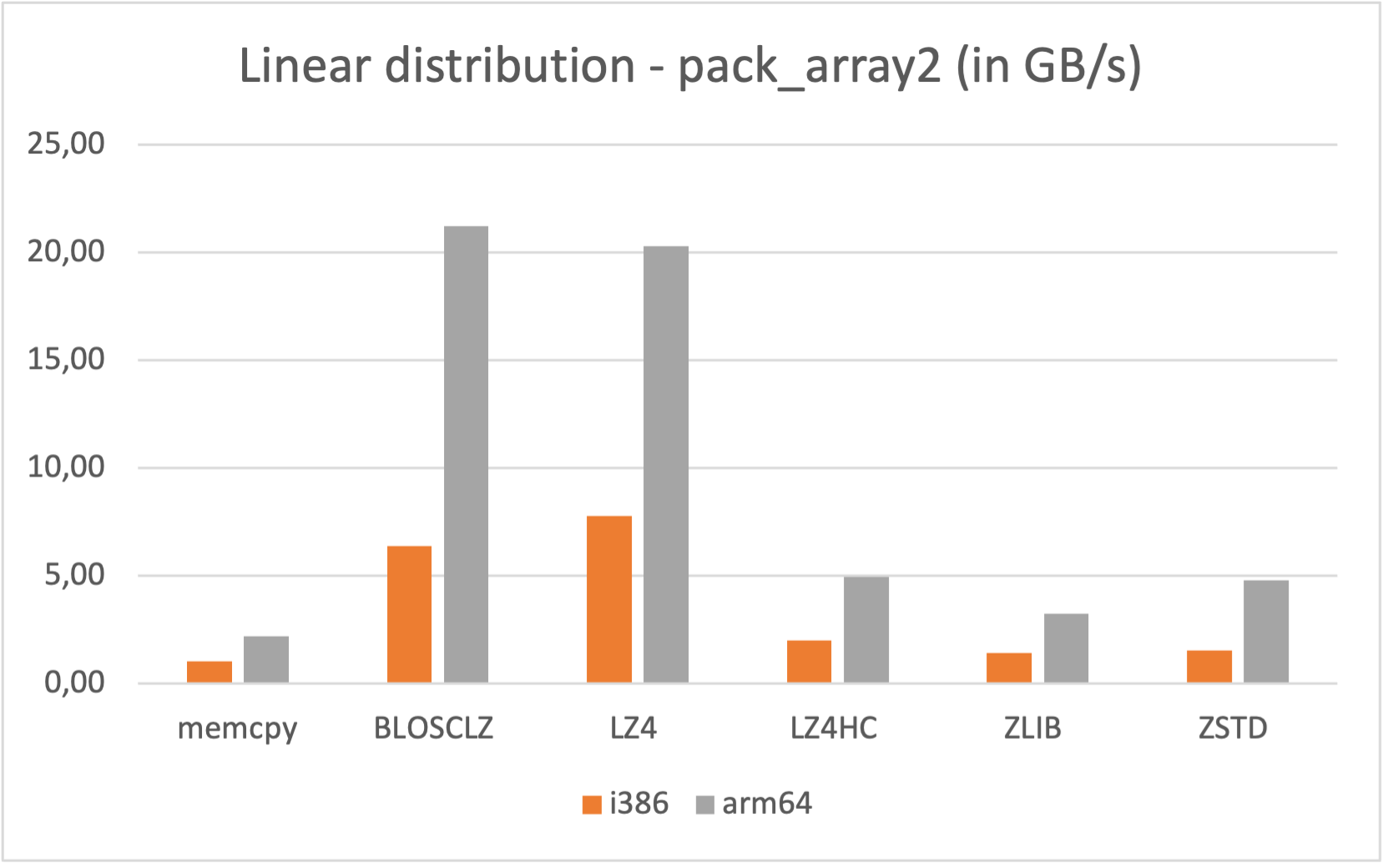 |
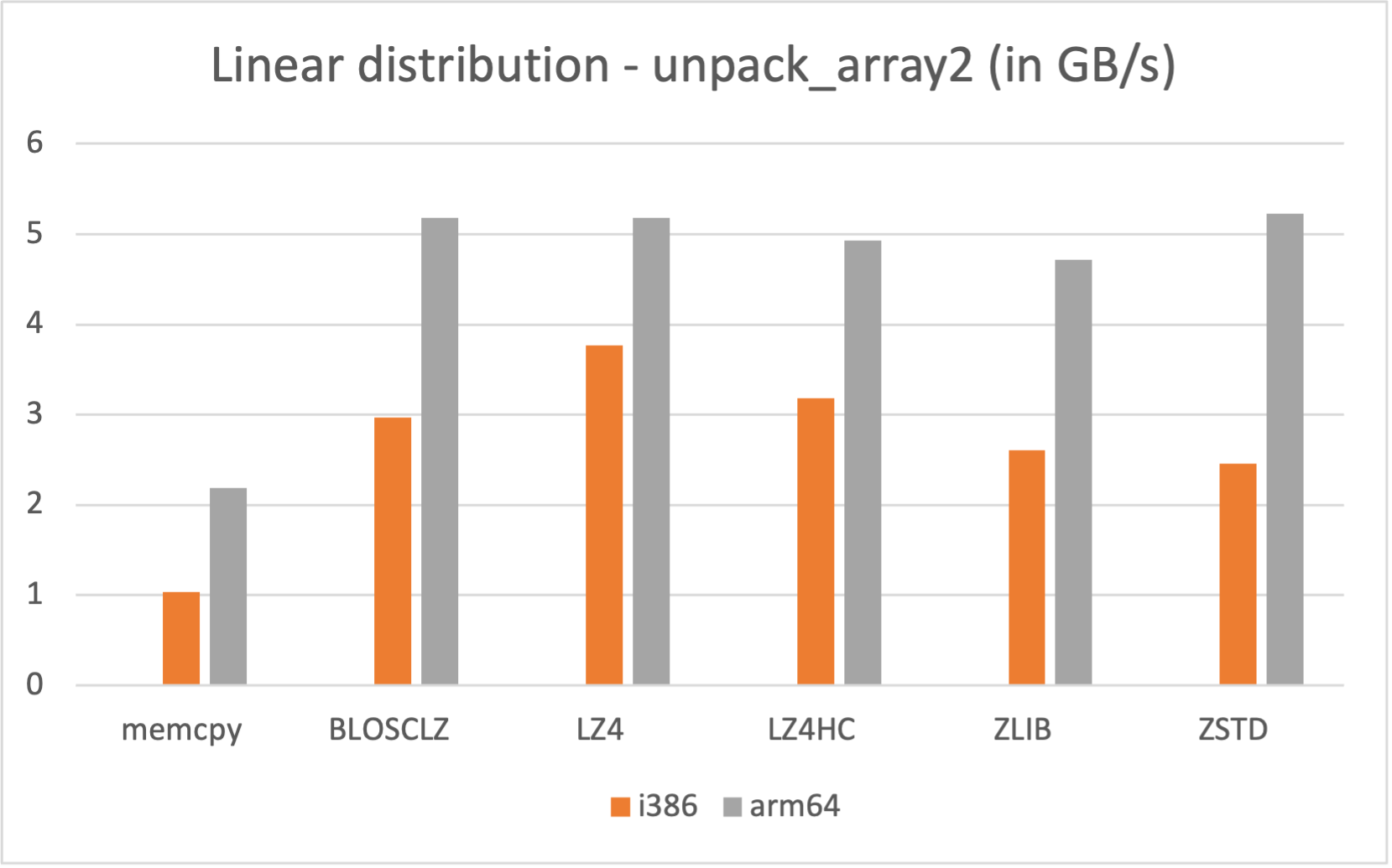 |
Read more about SChunk features in our blog entry at: https://www.blosc.org/posts/python-blosc2-improvements
One of the latest and more exciting additions in Python-Blosc2 is the NDArray object. It can write and read n-dimensional datasets in an extremely efficient way thanks to a n-dim 2-level partitioning, allowing to slice and dice arbitrary large and compressed data in a more fine-grained way:

To wet you appetite, here it is how the NDArray object performs on getting slices orthogonal to the different axis of a 4-dim dataset:

We have blogged about this: https://www.blosc.org/posts/blosc2-ndim-intro
We also have a ~2 min explanatory video on why slicing in a pineapple-style (aka double partition) is useful:

Blosc is now offering Python wheels for the main OS (Win, Mac and Linux) and platforms.
You can install binary packages from PyPi using pip:
pip install blosc2The documentation is here:
https://blosc.org/python-blosc2/python-blosc2.html
Also, some examples are available on:
https://github.com/Blosc/python-blosc2/tree/main/examples
python-blosc2 comes with the C-Blosc2 sources with it and can be built in-place:
git clone https://github.com/Blosc/python-blosc2/
cd python-blosc2
git submodule update --init --recursive
python -m pip install -r requirements-build.txt
python setup.py build_ext --inplaceThat's all. You can proceed with testing section now.
After compiling, you can quickly check that the package is sane by running the tests:
python -m pip install -r requirements-tests.txt
python -m pytest (add -v for verbose mode)If curious, you may want to run a small benchmark that compares a plain NumPy array copy against compression through different compressors in your Blosc build:
PYTHONPATH=. python bench/pack_compress.pyThe software is licenses under a 3-Clause BSD license. A copy of the python-blosc2 license can be found in LICENSE.txt.
Discussion about this module is welcome in the Blosc list:
https://groups.google.es/group/blosc
Please follow @Blosc2 to get informed about the latest developments.
You can cite our work on the different libraries under the Blosc umbrella as:
@ONLINE{blosc,
author = {{Blosc Development Team}},
title = "{A fast, compressed and persistent data store library}",
year = {2009-2023},
note = {https://blosc.org}
}Enjoy!