






{kind=link}
Scripts for reproducing annembed paper
This is a colloboration between Jianshu Zhao and Jean Pierre-Both (algorithm part). In the scripts folder, you can see the R scripts used to reproduce the main figures in the paper. We have a GitLab mirror clone here just in case Github service is not freely available in some region.
If you find annembed useful, please cite the following paper:
@article{zhao2024approximate,
title={Approximate nearest neighbor graph provides fast and efficient embedding with applications for large-scale biological data},
author={Zhao, Jianshu and Pierre Both, Jean and Konstantinidis, Konstantinos T},
journal={NAR Genomics and Bioinformatics},
volume={6},
number={4},
pages={lqae172},
year={2024},
publisher={Oxford University Press}
}
conda install -c bioconda -c conda-forge annembed=0.1.8
### or if you have an old version miniconda3/bioconda3, use the most version number here: https://bioconda.github.io/recipes/annembed/README.html#package-package%20'annembed'
conda install -c bioconda -c conda-forge annembed=0.1.7### Linux
wget https://github.com/jianshu93/annembed/releases/download/v0.1.8/annembed_Linux_x86-64_v0.1.8.zip
unzip annembed_Linux_x86-64_v0.1.8.zip
chmod a+x ./annembed
./annembed -h
### Macos
wget https://github.com/jianshu93/annembed/releases/download/v0.1.8/annembed_Darwin_universal_v0.1.8.tar.gz
tar -xzvf ./annembed_Darwin_universal_v0.1.8.tar.gz
chmod a+x ./annembed
### check install MacOS, you may need to change the system setup to allow external binary to run by type the following first and use your admin password
sudo spctl --master-disable
./annembed -h
### or you can have Homebrew on MacOS installed first and then (recommended):
brew update
brew tap jianshu93/annembed
brew install annembed
annembed -h
## bioconda
conda install -c bioconda -c conda-forge annembed
## pre-compiled binary
wget https://github.com/jianshu93/annembed/releases/download/v0.2.1/annembed_Linux_x86-64_v0.2.0.zip
unzip annembed_Linux_x86-64_v0.2.0.zip
chmod a+x ./annembed
./annembed -h$ annembed -h
************** initializing logger *****************
Non-linear Dimension Reduction/Embedding via Approximate Nearest Neighbor Graph
Usage: annembed-new [OPTIONS] --csv <csvfile> [COMMAND]
Commands:
hnsw Build HNSW graph
help Print this message or the help of the given subcommand(s)
Options:
--csv <csvfile> Expecting a csv file
-o, --out <outfile> Output file name
-d, --delim <delim> Delimiter can be ' ', ','
--batch <batch> Number of batches to run [default: 20]
--stepg <grap_step> Number of gradient descent steps
--nbsample <nbsample> Number of edge sampling [default: 10]
-l, --layer <hierarchy> A layer num [default: 0]
--scale <scale> Spatial scale factor [default: 1.0]
-d, --dim <dimension> Dimension of embedding [default: 2]
-q, --quality <quality> Sampling fraction, should <= 1.
-h, --help Print help
$ annembed hnsw -h
************** initializing logger *****************
Build HNSW graph
Usage: annembed-new --csv <csvfile> hnsw [OPTIONS] --dist <dist> --nbconn <nbconn> --ef <ef> --knbn <knbn>
Options:
-d, --dist <dist> Distance type is required, must be one of "DistL1" , "DistL2", "DistCosine" and "DistJeyffreys"
--nbconn <nbconn> Maximum number of build connections allowed (M in HNSW)
--ef <ef> Build factor ef_construct in HNSW
--scale_modify_f <scale_modify> Hierarchy scale modification factor in HNSW/HubNSW or FlatNav, must be in [0.2,1] [default: 1.0]
--knbn <knbn> Number of k-nearest neighbours to be retrieved for embedding
-h, --help Print help
Annembed can be run like this (see the example input format):
### prepare data
git clone https://github.com/jianshu93/annembed_analysis
cd annembed_analysis
### in the example input, column name or header will be skipped (detected automatically), the order of raws in output (most likely your sample) will be the same with that of the input.
## useage (v0.1.6 and later)
annembed --csv ./example/c-elegans_qc_final_all_2000.csv --scale 0.65 --nbsample 10 --stepg 2.0 --layer 0 --dim 2 -o fashion_embedded_csv.txt hnsw --dist 'DistL2' --nbconn 64 --ef 512 --knbn 15
### For high dimension datasets. We can use HubNSW (v0.1.8 or later) to reduce memory and speedup HNSW graph build
###get mist-fashion data (758 dimensions)
wget https://github.com/jianshu93/annembed/releases/download/v0.1.8/fashion-mnist_data.csv.gz
gunzip fashion-mnist_data.csv.gz
### scale_modify_f is to set number of layers to build, 0.25 is good to allow only 1 layer.
annembed --csv ./fashion-mnist_data.csv --scale 0.65 --nbsample 10 --stepg 2.0 --layer 0 --dim 2 -o fashion_embedded.csv hnsw --dist 'DistL2' --nbconn 64 --ef 512 --knbn 15 --scale_modify_f 0.25
## For old version (v0.1.5 and before)
annembed --csv ./example/c-elegans_qc_final_all_2000.csv embed --scale 0.65 --nbsample 10 --stepg 2.0 --layer 0
By default, annembed will use all available computer cores/threads for nearly all steps except difussion map initialization, which is very fast even for large dataset. Annembed library can be found here or here. Annembed can also be used as a library, as shown in the Ann section of GSearch
you will find a 2 column output embedded.csv by default, which are the embedded dimensions 1 and 2 respectively. Sample order are preserved and can be combined with sample metadata. Each run can be different because initialization is random and edge sampling is also random. But the visualization results will not be changed.
Embedding genome database via GSearch (install GSearch first)
### Install gsearch (Linux for example, see above for MacOS install)
https://github.com/jean-pierreBoth/gsearch/releases/download/v0.1.4/GSearch_Linux_x86-64_v0.1.3.zip
unzip GSearch_Linux_x86-64_v0.1.3.zip
cd GSearch_Linux_x86-64_v0.1.3
chmod a+x ./gsearch
./gsearch -h
### download pre-built bacterial genome HNSW graph database, check GSearch page ann section on how to do it
wget http://enve-omics.ce.gatech.edu/data/public_gsearch/GTDBv207_v2023.tar.gz
tar xzvf ./GTDBv207_v2023.tar.gz
cd ./GTDB/prot
tar xzvf k7_s12000_n128_ef1600.prob.tar.gz
gsearch ann -b ./k7_s12000_n128_ef1600_gsearch --stats --embed
The output of this step can be visualized, for example for the GTDB v207 we have the following plot. A new paper for the library and also this subcommand is in preparation.
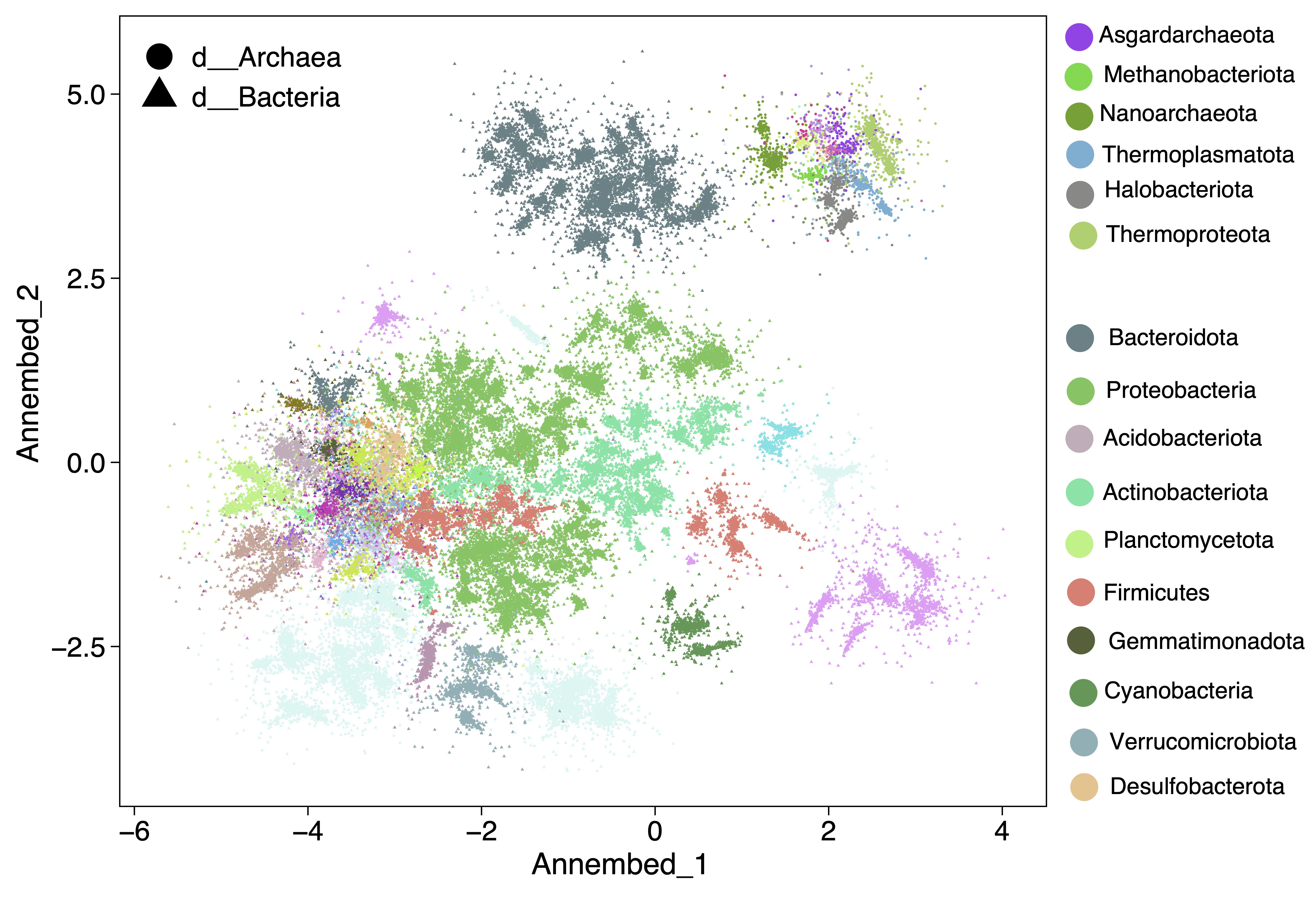
By default, annembed use Intel Math Kernel Library (intel-mkl-static feature) as the BLAS backend to make full use of x86 CPU performance on Linux machines. However, it is possible to use the open source OpenBLAS (openblas-static feature) as the BLAS backend. Our tests showed that OpenBLAS is slightly slower than Intel MKL on x86-64 Linux. On x86-64/Intel MacOS, OpenBLAS/Intel-MKL performance is significantly decreased compared to Linux but still supported (openblas-system/intel-mkl-system feature). We also provide the native BLAS framework support from MacOS called Accelerate Framework (macos-accelerate feature). On aarch64 MacOS (M1, M2, M3 chips), only the OpenBLAS and Accelerate Framework backend is supported (macos-accelerate feature). Again, performance decreased for both compared to Linux.
Jianshu Zhao, Jean Pierre Both, Konstantinos T Konstantinidis, Approximate nearest neighbor graph provides fast and efficient embedding with applications for large-scale biological data, NAR Genomics and Bioinformatics, Volume 6, Issue 4, December 2024, lqae172, https://doi.org/10.1093/nargab/lqae172