performance 2016 10 26
Contents
The main goal of the byteserver is to provide a more (vertically) scalable ZEO server mainly by using a fast language not constrained by a GIL. And also using object-level commit locks and better temporary file management.
A secondary goal is to provide better performance even under light load.
For the initial operation, we want to stick with the same basic architecture as existing ZEO servers:
- Writing to and reading from a single file.
- Asynchronous replication.
Assessing scalability of the server is complicated by the fact that it's easy to have results skewed by non-server-related factors such as:
- Limited file I/O performance.
- Saturated client CPU.
- Saturated network connections.
For this reason, I separated clients and server and chose a server for high I/O capacity. The tests were run in AWS using EC2 instances in a single VPC and subnet.
The machines:
- server
- i2.8xlarge, 36 virtual cpus, 100K pystones/s, 244G ram, 10Gb network, instance ssd storage
- client
- m4.10xlarge, 40 virtual cpus, 140K pystones/s, 160G ram, 10Gb network, ping times to server 430 microseconds
- big client
- m4.16xlarge, 64 virtual cpus, 144K pystones/s, 256G ram, 20Gb network ping times to server 400 microseconds
- big client 2
- m4.16xlarge, 64 virtual cpus, 143K pystones/s, 256G ram, 20Gb network, ping times to server 400 microseconds
I compared byteserver to ZEO. Clients ran Python 3.5 using uvloop. The ZEO server also used uvloop.
I performed several operations:
- add
- Add 3 objects in a transaction
- update
- Update 3 objects in a transaction
- cold read
- Read 3 objects per transaction
- cold read with prefetch
- Read 3 objects per transaction using prefetch
For each test, 1000 transactions were performed using the (non-big) client.
Results shown are in microseconds per transaction. Columns are level of concurrency. For concurrence > 1, the numbers are averages.
| Server | c1 | c2 | c4 | c8 | c16 | c32 | c64 |
|---|---|---|---|---|---|---|---|
| ZEO | 5779 | 6483 | 8839 | 13397 | 24400 | 48930 | 105670 |
| byteserver | 5521 | 5580 | 5967 | 6144 | 8970 | 17804 | 40802 |
| Server | c1 | c2 | c4 | c8 | c16 | c32 | c64 |
|---|---|---|---|---|---|---|---|
| ZEO | 5008 | 5188 | 8509 | 12529 | 23080 | 47730 | 107758 |
| byteserver | 4678 | 4917 | 5120 | 5845 | 8970 | 17667 | 39800 |
| Server | c1 | c2 | c4 | c8 | c16 | c32 | c64 |
|---|---|---|---|---|---|---|---|
| ZEO | 3234 | 3366 | 3300 | 3440 | 4492 | 7500 | 13471 |
| byteserver | 3154 | 3092 | 3100 | 3112 | 3049 | 3503 | 4374 |
| Server | c1 | c2 | c4 | c8 | c16 | c32 | c64 |
|---|---|---|---|---|---|---|---|
| ZEO | 1640 | 1628 | 1618 | 1836 | 3031 | 5392 | 10380 |
| byteserver | 1367 | 1424 | 1463 | 1501 | 1583 | 1762 | 2297 |
With ZEO, write operations become more expensive as concurrency increases. For the byteserver, write times were relatively consistent up until a concurrency of 16, after which times increase linearly, likely because disk I/O was maxed out.
ZEO write performance degradation at low concurrency is likely due to the global commit lock.
It appears that ZEO read performance is limited by the global commit lock and and the machine's disk I/O. A separate analysis of a ZEO server with experimental object-level commit locks showed server speed and the GIL to be the limiting factor (to the point that object-level commit locks provided no benefit).
The byteserver seems only to be limited by disk I/O.
ZEO read performance is relatively consistent up to a concurrency of 8, after which it degrades quickly. This appeared to be due to CPU saturation of the client and the server.
Byteserver read perforce also degrades much more slowly above a concurrency of 8. This appeared to be due to CPU saturation of the client. The server was more or less idle.
Because reads are the most common operations, and because they shouldn't be as limited by disk I/O, I explored how hard I could stress ZEO and byteserver servers with read operations.
I first looked at byteserver. Using a single client, it appeared that I was saturating the network connection between the client and server. I added the 2 big clients and found that I started to saturate the network at around 24 clients per client machine (72 clients). A this rate, the CPU load on the server was high, but it wasn't pegged. 96 client processes pegged one of the server CPUs.
What's odd is that with the byteserver, lead was spread over multiple CPUs, but at very high read load, it tended to be concentrated on one of the CPUs. This is a bit of a mystery. The only explanation I can think of off hand is that reads have to look up file locations in an index that's protected by a lock, so perhaps at very high loads, the index serializes requests and becomes a limiting factor. This is worth exploring later.
For ZEO, I was able to peg the server CPU (on a single core because of the GIL) with 10 concurrent clients, and %CPU was in the 90s with 8 clients.
Byteserver is much more scalable than ZEO servers. Write capacity is limited by the basic architecture (single file being written) and underlying disk I/O. Object-level locks provide a win until disk I/O is saturated.
For reads, byteserver scaled to more than 70 clients before request times started to degrade, while the ZEO became saturated at 10 clients.
Note that at low concurrency, while byteserver was faster, request times were dominated by network round trip times, so requests weren't that much faster.
The existing byteserver implementation is very basic (and incomplete). It's likely that there's a lot of room to push performance further in the future.
Oct 30 2016
At the Plone conference, I'd noted that some tests with PyPy suggested that it sped things up by 2x. This was based on a conversation I had with Jason Madden last year. This was with respect to ZEO4. I looked back at those results and the speedups were for writes, not reads. With some help from Jason, I was able to reproduce those numbers. Note, however, that the numbers were for a client talking to a server on the same machine.
I re-ran the earlier analysis to include pypy and along the way, ran into some issues.
- When I performed the original analyses, I underestimated the danger of saturating network connections between clients and servers in AWS, especially for reads. When redoing read tests, I used 5 ZEO client machines, which were m4.10xlarge machines. With these machines, it appeared I was just beginning to saturate the network at ~16 ZEO clients on a machine. The next larger instance could do a little bit more, but was quite a bit more expensive. I used 5 machines because asking for more would have required asking for an EC2 limit increase and I didn't want to wait. :)
- In my earlier analysis, I didn't notice that client machines were created in a different availability zone, which made network connections much slower. This time, I was careful to make sure each client was in the same AZ as the server. As a result, ping times were .130 milliseconds, rather ~.430.
- I also upped my game in the benchmark script by having it save data files rather than reports, which in turn allows me to summarize results as graphs rather than tables.
I ran the analysis with Python 2.7 rather than 3.5 because pypy doesn't support Python 3.4 yet. Pypy was used in the server, not the client. The clients were the same across servers, except that the bytserver client used msgpack rather than pickle for network serialization.
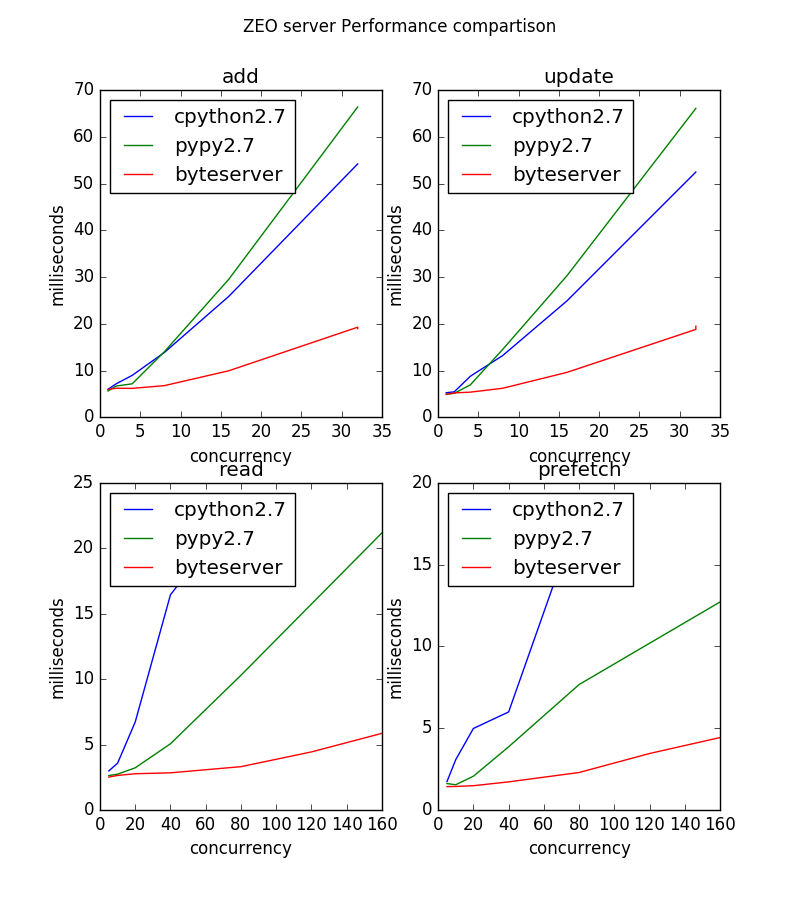
Some things to note:
- pypy is a big win for reads over cpython.
- byteserver is still much faster than pypy
- pypy is slower than cpython for writes. This is surprising.
Observing htop on the server, CPU on the server for the server
process hit 100% for cpython at around 8 concurrent read clients. For
pypy, the CPU was pegged at around 16 clients.
For byteserver, up until around 60 read clients, CPU percentages were low and spread over multiple CPUs. Over around 60 clients, one of the CPUs starts to load up and becomes pegged at around 80 clients. My initial guess is that this was due to clients needing to synchronize to gain access to the index. I tried splitting the index into separate indexes by oid, but this made no difference. (It's possible that I screwed this up somehow, as it was a quick hack.) So the concentration of computation in a single processor remains a mystery.