Pobieranie i przekształcanie surowych wyników egzaminów
Załadujmy potrzebne pakiety i nawiążmy połączenie z bazą:
library("ZPD")
library("ggplot2")
src = polacz()Pobieranie dużych ilości danych z bazy (jak np. wyników egzaminu dla całego rocznika) może zająć kilkanaście minut (a w wypadku, gdy pobiera je wiele osób równocześnie odpowiednio dłużej). Stosowne fragmenty kodu oznaczone zostały odpowiednim komentarzem.
Do pobierania surowych wyników służy funkcja pobierz_wyniki_egzaminu(), dla której pomoc można wyświetlić za pomocą polecenia ?pobierz_wyniki_egzaminu.
Jej składnia jest następująca:
pobierz_wyniki_egzaminu(src, rodzajEgzaminu, czescEgzaminu, rokEgzaminu, czyEwd, punktuj = TRUE, idSkali = NULL, skroc = TRUE)
argumenty:
-
src - uchwyt źródła danych dplyr-a (zwrócony przez funkcję
polacz()) - rodzajEgzaminu - rodzaj egzaminu, ktorego wyniki maja zostac pobrane
- czescEgzaminu - czesc egzaminu, ktorego wyniki maja zostac pobrane
- rokEgzaminu - rok egzaminu, ktorego wyniki maja zostac pobrane
- czyEwd - wybor, czy maja byc pobrane wyniki gromadzone przez EWD, czy PAOU
- punktuj - wybor, czy dane maja byc pobrane w postaci dystraktorow, czy punktow
- idSkali - identyfikator skali, ktora ma zostac zastosowana do danych
- skroc - czy do danych zastosowac skrocenia skal opisane w skali
Najkrótsze zastosowanie tej funkcji to pobierz_wyniki_egzaminu(src, rodzajEgzaminu, czescEgzaminu, rokEgzaminu, czyEwd) (domyślnie zwraca ona punkty, a nie dystraktory i nie jest stosowana żadna skala).
Pobierzmy wyniki egzaminu gimnazjalnego w części matematyczno-przyrodniczej w 2011 roku:
-
Sprawdzamy, jaki to rodzaj i część egzaminu - http://zpd.ibe.edu.pl/doku.php?id=czesci_egzaminu
-
Sprawdzamy, czy będą to dane EWD czy dane ZAOU - http://zpd.ibe.edu.pl/doku.php?id=obazie
-
Pobieramy dane:
# UWAGA! Wykonywanie tego polecenia może zająć kilkanaście minut. gmp11_surowe = pobierz_wyniki_egzaminu(src, "egzamin gimnazjalny", "matematyczno-przyrodnicza", 2011, TRUE) %>% collect() head(gmp11_surowe)
## Source: local data frame [6 x 50] ## ## id_obserwacji id_testu id_szkoly rok k_995 k_996 k_997 k_998 k_999 ## (int) (int) (int) (dbl) (dbl) (dbl) (dbl) (dbl) (dbl) ## 1 1876177 871 15347 2011 0 1 0 0 0 ## 2 2301664 871 16020 2011 1 0 0 0 0 ## 3 1873968 871 14415 2011 0 0 0 1 0 ## 4 2301665 871 14615 2011 0 0 0 1 1 ## 5 2301666 871 17497 2011 1 0 0 0 0 ## 6 2301667 871 17771 2011 0 0 0 0 0 ## Variables not shown: k_1000 (dbl), k_1001 (dbl), k_1002 (dbl), k_1003 ## (dbl), k_1004 (dbl), k_1005 (dbl), k_1006 (dbl), k_1007 (dbl), k_1008 ## (dbl), k_1009 (dbl), k_1010 (dbl), k_1011 (dbl), k_1012 (dbl), k_1013 ## (dbl), k_1014 (dbl), k_1015 (dbl), k_1016 (dbl), k_1017 (dbl), k_1018 ## (dbl), k_1019 (dbl), k_1020 (dbl), k_1021 (dbl), k_1022 (dbl), k_1023 ## (dbl), k_1024 (dbl), k_1025 (dbl), k_1026 (dbl), k_1027 (dbl), k_1028 ## (dbl), k_1029 (dbl), k_1030 (dbl), k_1031 (dbl), k_1032 (dbl), k_1033 ## (dbl), k_1034 (dbl), k_1035 (dbl), k_1036 (dbl), k_1037 (dbl), k_1038 ## (dbl), k_1039 (dbl), k_1040 (dbl)
Obliczmy sumę punktów dla każdego ucznia i wyświetlmy histogram wyników.
-
Aby zsumować punkty dla każdego ucznia użyjemy finkcji
zsumuj_punkty()(pomoc:?zsumuj_punkty).Jej składnia jest następująca:
zsumuj_punkty(dane, usunKryteria = TRUE)
argumenty:-
dane - wynik dzialania dowolnej z funkcji
pobierz_wyniki_...() - usunKryteria - czy usuwac ze zbioru kolumny z wynikami za poszczegolne kryteria
UWAGA: Domyślnie (przy podaniu tylko nazwy danych, które chcemy zsumować) funkcja
zsumuj_punkty()usuwa punktację za poszczególne zadania!a) Stwórzmy zmienną zawierającą sumy punktów uczniów z pobranych danych z matematyki:
gmp11_surowe_sumy = gmp11_surowe %>% zsumuj_punkty() head(gmp11_surowe_sumy)
## Source: local data frame [6 x 5] ## ## id_obserwacji id_testu id_szkoly rok wynik ## (int) (int) (int) (dbl) (dbl) ## 1 1876177 871 15347 2011 13 ## 2 2301664 871 16020 2011 4 ## 3 1873968 871 14415 2011 17 ## 4 2301665 871 14615 2011 11 ## 5 2301666 871 17497 2011 20 ## 6 2301667 871 17771 2011 7b) Dodajmy zmienną zawierającą sumy punktów uczniów do pobranych danych z matematyki:
gmp11_surowe = gmp11_surowe %>% zsumuj_punkty(FALSE) head(gmp11_surowe)
## Source: local data frame [6 x 51] ## ## id_obserwacji id_testu id_szkoly rok k_995 k_996 k_997 k_998 k_999 ## (int) (int) (int) (dbl) (dbl) (dbl) (dbl) (dbl) (dbl) ## 1 1876177 871 15347 2011 0 1 0 0 0 ## 2 2301664 871 16020 2011 1 0 0 0 0 ## 3 1873968 871 14415 2011 0 0 0 1 0 ## 4 2301665 871 14615 2011 0 0 0 1 1 ## 5 2301666 871 17497 2011 1 0 0 0 0 ## 6 2301667 871 17771 2011 0 0 0 0 0 ## Variables not shown: k_1000 (dbl), k_1001 (dbl), k_1002 (dbl), k_1003 ## (dbl), k_1004 (dbl), k_1005 (dbl), k_1006 (dbl), k_1007 (dbl), k_1008 ## (dbl), k_1009 (dbl), k_1010 (dbl), k_1011 (dbl), k_1012 (dbl), k_1013 ## (dbl), k_1014 (dbl), k_1015 (dbl), k_1016 (dbl), k_1017 (dbl), k_1018 ## (dbl), k_1019 (dbl), k_1020 (dbl), k_1021 (dbl), k_1022 (dbl), k_1023 ## (dbl), k_1024 (dbl), k_1025 (dbl), k_1026 (dbl), k_1027 (dbl), k_1028 ## (dbl), k_1029 (dbl), k_1030 (dbl), k_1031 (dbl), k_1032 (dbl), k_1033 ## (dbl), k_1034 (dbl), k_1035 (dbl), k_1036 (dbl), k_1037 (dbl), k_1038 ## (dbl), k_1039 (dbl), k_1040 (dbl), wynik (dbl) -
dane - wynik dzialania dowolnej z funkcji
-
Narysujmy histogram sum punktów. W tym celu użyjemy funkcji
ggplot()orazgeom_histogram()gmp11_surowe_sumy %>% ggplot(aes(wynik)) + geom_histogram(binwidth = 1)
Dla tego samego egzaminu pobierzmy dane w dystraktorach wraz z dołączonymi informacjami kontekstowymi z grupy danych :
# UWAGA! Wykonywanie tego polecenia może zająć kilkanaście minut!
gmp11_surowe_dys = pobierz_wyniki_egzaminu(src, "egzamin gimnazjalny", "matematyczno-przyrodnicza", 2011, TRUE, FALSE) %>%
inner_join(pobierz_dane_uczniowie_testy(src)) %>%
collect()## Joining by: c("id_obserwacji", "id_testu", "id_szkoly", "rok")
head(gmp11_surowe_dys)## Source: local data frame [6 x 32]
##
## id_obserwacji id_testu id_szkoly rok k_4129 k_4130 k_4131 k_4132
## (int) (int) (int) (dbl) (int) (int) (int) (int)
## 1 3095157 1481 19812 2013 3 4 3 2
## 2 2709340 1481 31174 2013 3 2 2 2
## 3 3095159 1481 19250 2013 2 4 1 2
## 4 3095162 1481 19270 2013 3 4 4 2
## 5 3095163 1481 19276 2013 3 4 3 2
## 6 3095167 1481 19288 2013 2 1 4 1
## Variables not shown: k_4133 (int), k_4134 (int), k_4135 (int), k_4136
## (int), k_4137 (int), k_4138 (int), k_4139 (int), k_4140 (int), k_4141
## (int), k_4142 (int), k_4143 (int), k_4144 (int), k_4145 (int), k_4146
## (int), k_4147 (int), k_4148 (int), k_4149 (int), k_4150 (int), k_4151
## (int), dysleksja (lgl), laureat (lgl), pop_podejscie (chr), oke (chr),
## zrodlo (chr)
Obliczmy częstość występowania poszczególnych dystraktorów w pierwszym zadaniu.
-
Sprawdzamy, jaki jest identyfikator zadania, które nas interesuje w wyszukiwarce zadań - http://zpd.ibe.edu.pl/doku.php?id=bazatestypytania [k_4129]
-
Wyświetlmy tabelę częstości:
gmp11_surowe_dys %>% select(k_4129) %>% table() * 100 / nrow(gmp11_surowe_dys)
## . ## -2 -1 1 2 3 ## 0.002107298 0.155676667 8.668108410 41.861218598 41.372588790 ## 4 ## 7.940300237 -
Porównując wyniki z treścią arkusza wygodniej byłoby operować na rzeczywistych kodach odpowiedzi. W celu "odkodowania" dystraktorów możemy użyć funkcji
odkoduj_dystraktory():gmp11_surowe_dys %>% select(k_4129) %>% odkoduj_dystraktory(src) %>% table() * 100 / nrow(gmp11_surowe_dys)
## . ## -1 -2 A B C ## 0.155676667 0.002107298 8.668108410 41.861218598 41.372588790 ## D ## 7.940300237 -
Wykonajmy te same analizy w podziale na wersję arkusza. W tym celu dołączymy informację o arkuszu z grupy danych
testy = pobierz_testy(src) %>% select(id_testu, arkusz) %>% collect() gmp11_surowe_dys = gmp11_surowe_dys %>% inner_join(testy)
## Joining by: "id_testu"czestosci = gmp11_surowe_dys %>% select(arkusz, k_4129) %>% odkoduj_dystraktory(src) %>% table() round(czestosci * 100 / rowSums(czestosci), 1)
## k_4129 ## arkusz -1 -2 A B C D ## GM-MA1-132 0.2 0.0 10.6 38.0 45.7 5.6 ## GM-MB1-132 0.2 0.0 7.0 45.3 37.6 10.0 -
Nasze analizy zakłócane są jeszcze przez laureatów - jako że wszystkim laureatom przypisywana jest wersja A arkusza sztucznie zawyżają oni częstośc występowania poprawnej odpowiedzi w wersji A arkusza. Usuńmy ich zatem z naszej analizy:
czestosci = gmp11_surowe_dys %>% filter(laureat == FALSE) %>% select(arkusz, k_4129) %>% odkoduj_dystraktory(src) %>% table() round(czestosci * 100 / rowSums(czestosci), 1)
## k_4129 ## arkusz -1 -2 A B C D ## GM-MA1-132 0.2 0.0 10.7 38.5 45.1 5.6 ## GM-MB1-132 0.2 0.0 7.0 45.2 37.7 10.0
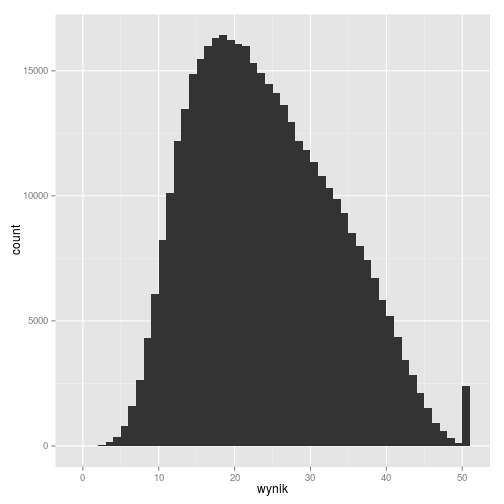
Narysujmy jeszcze raz histogram sum punktów:
gmp11_surowe_sumy %>%
ggplot(aes(wynik)) +
geom_histogram(binwidth = 1)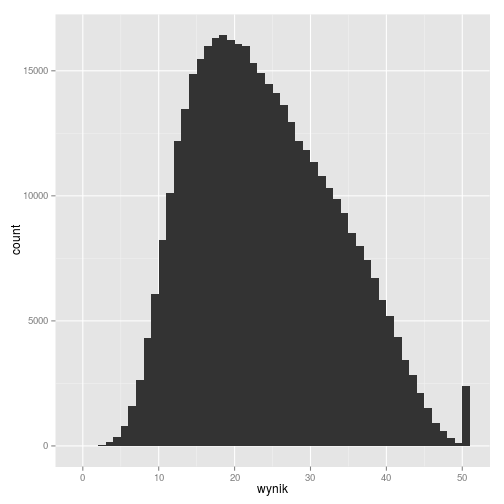
Odbiega on nieco od rokładu normalnego. Co gorsza, dla innych lat rozkład wyników może mieć (i w istocie tak się dzieje) istotnie różny kształt. Powoduje to, że nie jest metodologicznie poprawne porównywanie między sobą wyników uczniów pochodzących z egzaminów z różnych lat. Najprostszym sposobem poradzenia sobie z tym problemem jest założenie, że rozkład umiejętności w populacji uczniów jest stały między latami, a obserwowane różnice w rozkładzie sum punktów mają źródło jedynie w zróżnicowaniu właściwości pomiarowych egzaminów w poszczególnych latach. Przyjmując takie założenie możemy dokonać normalizacji ekwikwantylowej wyników i w ten sposób uzyskać znormalizowane, porównywalne między latami, wyniki uczniów.
W celu ekwikwantylowego znormalizowania wyników uczniów użyjemy funkcji normalizuj(). Przekształca ona sumy punktów na wartości znormalizowane o średniej 100 i odchyleniu standardowym 15 (co można zmienić - patrz ?normalizuj oraz ?normy_ekwikwantylowe).
gmp11_surowe_norm = gmp11_surowe_sumy %>%
normalizuj()
head(gmp11_surowe_norm)## id_obserwacji id_testu id_szkoly rok wynik wynik_norm
## 1 1876177 871 15347 2011 13 83.08106
## 2 2301664 871 16020 2011 4 53.16476
## 3 1873968 871 14415 2011 17 91.23555
## 4 2301665 871 14615 2011 11 77.97892
## 5 2301666 871 17497 2011 20 96.17470
## 6 2301667 871 17771 2011 7 65.25038
Histogram wyników po normalizacji:
gmp11_surowe_norm %>%
ggplot(aes(wynik_norm)) +
geom_histogram(binwidth = 1)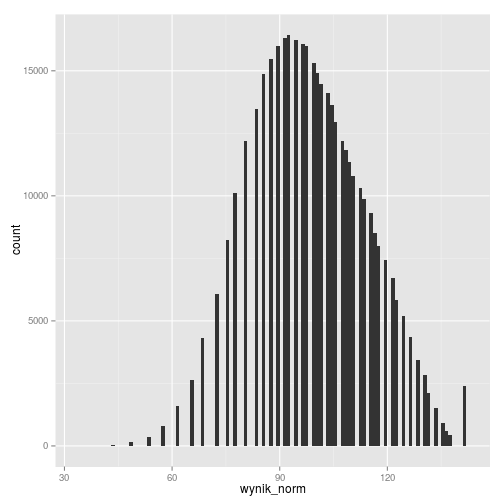
Drugim sposobem normalizacji danych jest wykorzystanie norm zapisanych w bazie. Mają one tą przewagę nad prostą normalizacją ekwikwantylową, że powstały na podstawie bardziej zaawansowanych analiz statystycznych, nakładających mniej arbitralne założenia.
Dwie kategorie norm dostępnych w bazie to:
- normy używane w Kalkulatorze EWD, przekształcające wynik surowy na wynik znormalizowany
- normy przygotowane na podstawie badań zrównujących, przekształcające wynik surowy na wynik surowy danego egzaminu w roku 2012
Spróbujmy zastosować do wyników egzaminu najpierw normę z kalkulatora EWD, a następnie normę zrównującą. W tym celu:
-
Wyszukajmy normy korzystając z grupy danych
- norma identyfikowana jest przez trójkę identyfikatorów id_skali, skalowanie oraz grupę
normy = pobierz_skale(src) %>% filter(posiada_normy == TRUE, rodzaj_egzaminu == 'egzamin gimnazjalny', czesc_egzaminu == 'matematyczno-przyrodnicza', rok == 2011) %>% collect() normy
## Source: local data frame [9 x 17] ## ## id_skali opis_skali rodzaj_skali skala_do_prezentacji ## (int) (chr) (chr) (lgl) ## 1 1012 ewd;gmR;2011 ewd TRUE ## 2 1012 ewd;gmR;2011 ewd TRUE ## 3 1012 ewd;gmR;2011 ewd TRUE ## 4 827 paou;gm;2011 zrównywanie TRUE ## 5 827 paou;gm;2011 zrównywanie TRUE ## 6 827 paou;gm;2011 zrównywanie TRUE ## 7 1012 ewd;gmR;2011 ewd TRUE ## 8 1012 ewd;gmR;2011 ewd TRUE ## 9 1012 ewd;gmR;2011 ewd TRUE ## Variables not shown: rodzaj_egzaminu (chr), czesc_egzaminu (chr), id_testu ## (int), rok (dbl), skalowanie (int), opis_skalowania (chr), estymacja ## (chr), data_skalowania (date), skalowanie_do_prezentacji (lgl), ## posiada_normy (lgl), posiada_eap (lgl), posiada_pv (lgl), grupa (chr)Ograniczmy się do wyświetlenia jedynie tych informacji, które będą nam przydatne:
normy %>% select(id_skali, skalowanie, grupa, opis_skali, opis_skalowania) %>% arrange(id_skali) %>% distinct()
## Source: local data frame [3 x 5] ## ## id_skali skalowanie grupa opis_skali ## (int) (int) (chr) (chr) ## 1 827 2 paou;gm;2011 ## 2 1012 2 ewd;gmR;2011 ## 3 1012 1 ewd;gmR;2011 ## Variables not shown: opis_skalowania (chr) -
Skorzystajmy z funkcji
normalizuj(), ale z nieco inną parametryzacją niż przy wyliczaniu norm ekwikwantylowych na podstawie danych:normalizuj(dane, src, kolWynik = 'wynik', idSkali = NULL, skalowanie = NULL)argumenty:-
dane - wyniki egzaminu (bądź testu) z obliczonymi sumami punktów (np. funkcją
zsumuj_punkty()) -
src - uchwyt źródła danych dplyr-a (zwrócony przez funkcję
polacz()) -
kolWynik - nazwa zmiennej z sumą punktów (wartość domyślna pasuje do zmiennej tworzonej przez funkcję
zsumuj_punkty()) - idSkali - identyfikator skali, z której normę chcemy zastosować
- skalowanie - identyfikator skalowania, z którego normę chcemy zastosować
-
Na początek zastosujmy normę z gimnazjalnego kalkulatora EWD (ekwikwantylową) - id_skali 1012, skalowanie 1, grupa ''
gmp11_norm_kalk1 = gmp11_surowe_sumy %>% normalizuj(src, 'wynik', 1012, 1, '')
-
Następnie zastosujmy normę z maturalnego kalkulatora EWD (pochodzącą ze skalowania IRT modelem Rascha) - id_skali 1012, skalowanie 2, grupa ''
gmp11_norm_kalk2 = gmp11_surowe_sumy %>% normalizuj(src, 'wynik', 1012, 2, '')
-
Na koniec zastosujmy normę zrównującą - id_skali 827, skalowanie 2, grupa ''
gmp11_norm_zrwm = gmp11_surowe_sumy %>% normalizuj(src, 'wynik', 827, 2, '')
-
dane - wyniki egzaminu (bądź testu) z obliczonymi sumami punktów (np. funkcją
-
Porównajmy wszystkie cztery rozkłady (surowy, znormalizowany normą ekwikwantylową z kalkulatora EWD, normą "raschową" z kalkulatora EWD oraz normą zrównującą):
# wyniki surowe gmp11_surowe_sumy %>% ggplot(aes(wynik)) + geom_histogram(binwidth = 1)
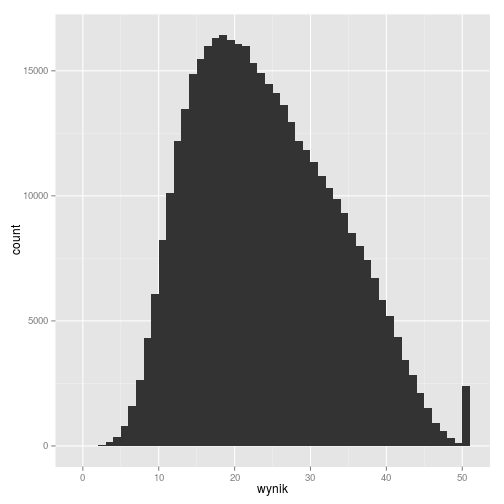
# norma ekwikwantylowa z kalkulatora EWD gmp11_norm_kalk1 %>% ggplot(aes(wynik_norm)) + geom_histogram(binwidth = 1)
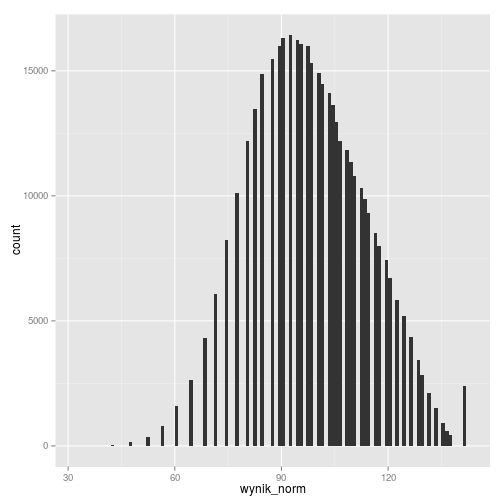
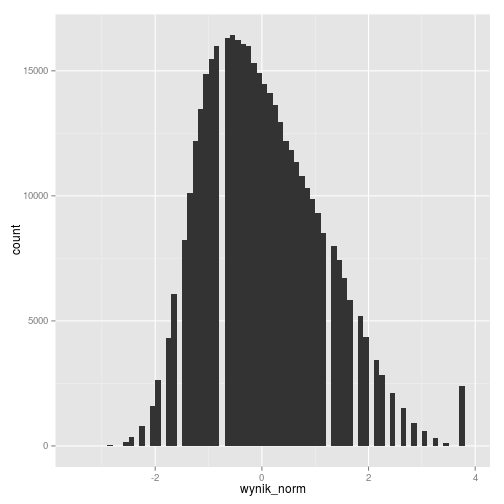
# norma "raschowa" z maturalnego kalkulatora EWD gmp11_norm_kalk2 %>% ggplot(aes(wynik_norm)) + geom_histogram(binwidth = 0.1)
# norma zrównująca gmp11_norm_zrwm %>% ggplot(aes(wynik_norm)) + geom_histogram(binwidth = 1)
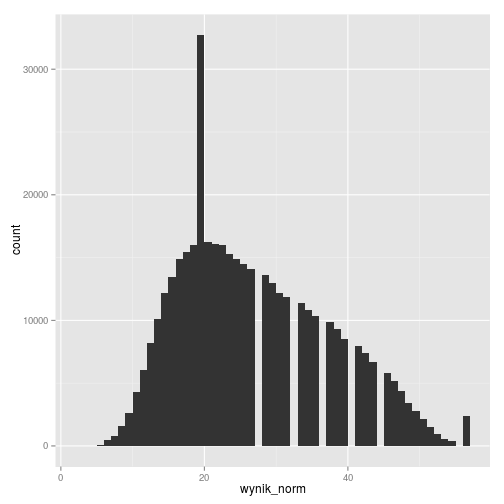
Dziwny pik w danych znormalizowanych normą zrównującą wynika z faktu, że dwie częste sumy punktów z roku 2011 (17 i 18 punktów) odpowiadają wg tej normy takiemu samemu wynikowi (20 punktów) w roku 2012. Z kolei ze względu na większą liczbę punktów możliwą do uzyskania w roku 2012 w sposób naturalny w rozkładzie przeskalowanym występują luki.
Z kolei dla danych znormalizowanych normą z kalkulatora EWD widzimy, że mają one średnią 0 i odchylenie stardowe 1, zaś lekko skośny rozkład wyników surowych został w jej wypadku zachowany.
Czasami (w wypadku EWD na ogół) interesować mogą nas tylko uczniowie piszący dany egzamin po raz pierwszy (na wyjściu) lub ostatni (na wejściu).
Do ich odfiltrowywania służy funkcja filtruj_przystapienia() (pomoc: ?filtruj_przystapienia). Dla wskazanego rodzaju egzaminu (lub tylko dla wybranej części egzaminu) oraz określenia z jakiego źródła (EWD/ZAOU) mają pochodzić dane, zwraca ona zbiór zawierający jedynie pierwsze lub ostatnie przystąpienia uczniów do danego egzaminu.
Jej składnia jest następująca:
filtruj_przystapienia(src, pierwsze, rodzajEgzaminu, czescEgzaminu = NULL, czyEwd, obserwacje = NULL)
argumenty:
- src - uchwyt źródła danych dplyr-a
- pierwsze - czy odfiltrować pierwsze podejście (jeśli FALSE, odfiltrowane zostanie ostatnie)
- rodzajEgzaminu - rodzaj egzaminu - patrz http://zpd.ibe.edu.pl/doku.php?id=czesci_egzaminu
- czescEgzaminu - wektor części egzaminu - patrz http://zpd.ibe.edu.pl/doku.php?id=czesci_egzaminu
- czyEwd - czy korzystać z danych EWD czy PAOU (patrz opis)
- obserwacje - wektor id_obserwacji lub ramka danych z kolumną id_obserwacji
Za pomocą złączenia inner_join lub filtrowania semi_join można odfiltrować pożądane wyniki egzaminu lub oszacowania umiejętności uczniów.
Złączmy obliczone powyżej sumy punktów z informacjami o pierwszym przystąpieniu do egzaminu gimnazjalnego:
- sprawdzając przystąpienia tylko w obrębie części matematyczno-przyrodniczej egzanuby,
- sprawdzając przystąpienia w obrębie całego egzaminu gimnazjalnego.
W obydwu wypadkach dla danych EWD, bo właśnie na takich danych mamy policzone sumy punktów.
# UWAGA! Wykonywanie tych poleceń może zająć kilka minut.
filtrMat = filtruj_przystapienia(src, TRUE, "egzamin gimnazjalny", "matematyczno-przyrodnicza", TRUE) %>% collect()
filtrGim = filtruj_przystapienia(src, TRUE, "egzamin gimnazjalny", NULL, TRUE) %>% collect()
head(filtrMat)## Source: local data frame [6 x 5]
##
## id_obserwacji dane_ewd rodzaj_egzaminu czesc_egzaminu
## (int) (lgl) (chr) (chr)
## 1 1500842 TRUE egzamin gimnazjalny matematyczno-przyrodnicza
## 2 1323799 TRUE egzamin gimnazjalny matematyczno-przyrodnicza
## 3 1539466 TRUE egzamin gimnazjalny matematyczno-przyrodnicza
## 4 16246538 TRUE egzamin gimnazjalny matematyczno-przyrodnicza
## 5 861952 TRUE egzamin gimnazjalny matematyczno-przyrodnicza
## 6 3029049 TRUE egzamin gimnazjalny matematyczno-przyrodnicza
## Variables not shown: rok (dbl)
head(filtrGim)## Source: local data frame [6 x 4]
##
## id_obserwacji dane_ewd rodzaj_egzaminu rok
## (int) (lgl) (chr) (dbl)
## 1 3316818 TRUE egzamin gimnazjalny 2013
## 2 3375654 TRUE egzamin gimnazjalny 2013
## 3 3090901 TRUE egzamin gimnazjalny 2012
## 4 2344626 TRUE egzamin gimnazjalny 2011
## 5 2391333 TRUE egzamin gimnazjalny 2011
## 6 2460482 TRUE egzamin gimnazjalny 2011
# filtrujemy
gmp11_filtrMat = gmp11_surowe_sumy %>%
inner_join(filtrMat)## Joining by: c("id_obserwacji", "rok")
gmp11_filtrGim = gmp11_surowe_sumy %>%
inner_join(filtrGim)## Joining by: c("id_obserwacji", "rok")
# jaka jest różnica w liczbie obserwacji?
nrow(gmp11_filtrMat) - nrow(gmp11_filtrGim)## [1] 27
- Z czego wynika różnica w liczbie obserwacji pomiędzy jednym i drugim sposobem filtrowania?
Na wstępie warto zaznaczyć, że nie wszystkie wyniki egzaminacyjne i oszacowania umiejętności uczniów są łączliwe między latami. Szczegółowe informacje znajdują się pod adresem http://zpd.ibe.edu.pl/doku.php?id=obazie
Złączanie następuje wprost po id_obserwacji, więc co najwyżej dane się nie połączą.
Warto jeszcze zauważyć, że złączane zbiory mogą zawierać jednakowo nazywające się kolumny (np. wynik, dysleksja, itp.), które przed złączeniem należy zmienić im nazwy (np. na wynik_spr, wynik_gh, dysleksja_spr, dysleksja_gh itd.). Wynika to z faktu, że złączenie przebiega na podstawie dopasowania wszystkim zmiennych o jednakowych nazwach w obydwu zbiorach, a my chcemy dokonać złączenia jedynie po zmiennej id_obserwacji.
Przyłączmy do policzonych sum surowych punktów z egzaminu GMP 2011 wyniki sprawdzianu 2008. W tym celu musimy:
-
Pobrać wyniki sprawdzianu 2011 z danych EWD (dodatkowo policzymy sumę punktów).
# UWAGA! Wykonywanie tego polecenia może zająć kilkanaście minut! spr08 = pobierz_wyniki_egzaminu(src, "sprawdzian", "", 2008, TRUE) %>% collect() spr08 = zsumuj_punkty(spr08) head(spr08)
## Source: local data frame [6 x 5] ## ## id_obserwacji id_testu id_szkoly rok wynik ## (int) (int) (int) (dbl) (dbl) ## 1 2320231 618 43963 2008 13 ## 2 2320234 618 43963 2008 27 ## 3 2320238 618 43963 2008 25 ## 4 2320242 618 43963 2008 26 ## 5 2320244 618 43963 2008 13 ## 6 2320248 618 43963 2008 11 -
Zmienić nazwy kolumn.
spr08 = spr08 %>% rename(wynik_spr = wynik, rok_spr = rok, id_testu_spr = id_testu, id_szkoly_spr = id_szkoly) head(spr08)
## Source: local data frame [6 x 5] ## ## id_obserwacji id_testu_spr id_szkoly_spr rok_spr wynik_spr ## (int) (int) (int) (dbl) (dbl) ## 1 2320231 618 43963 2008 13 ## 2 2320234 618 43963 2008 27 ## 3 2320238 618 43963 2008 25 ## 4 2320242 618 43963 2008 26 ## 5 2320244 618 43963 2008 13 ## 6 2320248 618 43963 2008 11 -
Połączyć wyniki z obydwu egzaminów.
polaczone = gmp11_surowe_sumy %>% left_join(spr08)
## Joining by: "id_obserwacji"head(polaczone)## Source: local data frame [6 x 9] ## ## id_obserwacji id_testu id_szkoly rok wynik id_testu_spr id_szkoly_spr ## (int) (int) (int) (dbl) (dbl) (int) (int) ## 1 1876177 871 15347 2011 13 NA NA ## 2 2301664 871 16020 2011 4 NA NA ## 3 1873968 871 14415 2011 17 NA NA ## 4 2301665 871 14615 2011 11 NA NA ## 5 2301666 871 17497 2011 20 NA NA ## 6 2301667 871 17771 2011 7 NA NA ## Variables not shown: rok_spr (dbl), wynik_spr (dbl)
Możemy sprawdzić, dla ilu uczniów połączyliśmy wyniki.
polaczone %>%
group_by(is.na(rok_spr)) %>%
summarize(n = n())## Source: local data frame [2 x 2]
##
## is.na(rok_spr) n
## (lgl) (int)
## 1 FALSE 376402
## 2 TRUE 32357
Jak widać nie przyłączyło się nieco ponad 32 tys. uczniów (np. o opóźnionym toku kształcenia).
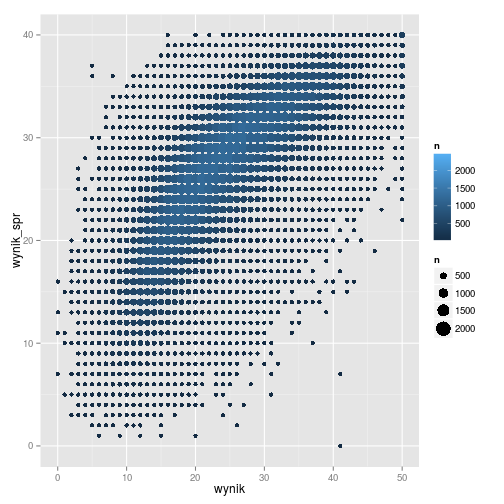
Na koniec naryzujmy wykres rozrzutu dla wyników obydwu egzaminów.
polaczone %>%
# obliczamy liczbę uczniów o danej kombinacji wyników na spr. i egz. gimn.
group_by(wynik, wynik_spr) %>%
summarize(n = n()) %>%
# rysujemy wykres rozrzutu
ggplot(aes(x = wynik, y = wynik_spr, size = n, color = n)) +
geom_point() +
# aby punkty miały porządany zakres wielkości
scale_size_continuous(range = c(2, 8))